
文字分類需要CNN? No!fastText完美解決你的需求(前篇)
文字分類需要CNN?No!fastText完美解決你的需求(前篇)
fastText是個啥?簡單一點說,就是一種可以得到和深度學習結果準確率相同,但是速度快出幾個世紀的文字分類演算法。這個演算法類似與CBOW,可愛的讀著是不是要問CBOW又是個什麼鬼?莫急,聽小編給你慢慢到來,一篇文章,讓你瞭解word2vec的原理,CBOW、Skip-gram模型,以及目前業界最流行的文字分類演算法——fastText。
2013年,Google的大牛Tomas Mikolov開源了word2vec演算法,轟動一時(當然,托馬斯大牛現在於FaceBook就職,16年中下旬開源了fastText演算法,又在業界引起了軒然大波,沒辦法,速度太快了)。
為了更好地理解fastText,我們的介紹分為上下兩篇,前篇,我們先來了解一下word2vec到底是啥,以及CBOW和Skip-gram;後篇,我們就來講述fastText演算法的思想和原理,有了前篇的鋪墊,你會輕鬆的學會fastText。
你可以在這篇文章看到:word2vec的思想與實現,fastText演算法的核心思想與創新,以及實現案例;你不會看到長篇的數學公式,高中數學就可以讓你看懂這篇文章,通篇都會以最最簡單直白的例子來說明,不會用讓人看了就想吐的數學公式來刺激可愛的你。
本篇博文將從以下幾個方面進行講解
- word2vec的思想與實現
- fastText演算法的核心思想與創新
- 實現案例
word2vec思想
word2vec的核心是神經網路,採用 CBOW(Continuous Bag-Of-Words,即連續的詞袋模型)和 Skip-Gram 兩種模型,將詞語映像到同一座標系,輸出為數值型向量的方法。簡而言之,就是將人類才可以看懂的文字,轉換為機器也可以識別、操作、處理的數值,將一串文字轉化為一個數值型向量的過程。
Word2vec的產生是一個必然的過程,隨著人類對非結構化資料(文字、語音、影象等)分析的需求,尤其是大量文字類資料的分析,必然需要一些讓計算機“理解”文字的方法,最直接有效的自然就是將文字轉化為數字;換言之,將全部的文字對映到數值空間中就是word2vec做的事情。這裡需要引入一個概念——語言模型,我們不會在此深入的去探索語言模型,只是簡單向讀者介紹這個概念。
語言最大的特徵就是上下文的聯絡,比如中文當中,兩個特定的字會組成一個詞語,若干詞語和字組成句子,多個句子組成文章,如果文章中的全部文字都隨機的打亂順序排列,那麼我想哪怕正在讀文章的你是中文系的高材生,要完全看懂這篇文章也要費九牛二虎之力,請看下面這兩段文字:
“自然語言處理是電腦科學領域與人工智慧領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通訊的各種理論和方法。自然語言處理是一門融語言學、電腦科學、數學於一體的科學。因此,這一領域的研究將涉及自然語言,即人們日常使用的語言,所以它與語言學的研究有著密切的聯絡,但又有重要的區別。”
“與言將學處處方聯及數言理語言信理各、語區工計系別這之和論切領所因人使中間究密的它有然的的與涉有自的要一言算語要效現體進的機融,語學究科科的計然行的學、但實又研是然。與重門能,究然常語域們語科是。自通人種日。言用領域機領域一智著機一人有即言用以言於能研方學的學它自重算向。算學自,計法此研個理一,語”
好吧,看到這裡你可能要罵人了,第二段是人話麼?答案是,第二段話就
是第一段話,只是對第一段話隨機打亂了順序,這個不倒150字的段落,也許你用30分鐘一個小時可以將它還原成“人話”,如果是長篇大論的呢?這裡就看出了語言的邏輯性,詞語前後關係的重要性。語言模型就是在做這樣的事情,考察一個句子出現的可能性(也就是概率)。如果一個句子S由n個詞
不懂這個公式絲毫不影響後面的學習,這個公式翻譯成白話就是:詞語
語言模型正是為了考察句子,或者說由詞a到詞b存在在句子中的概率而存在的。如果將我們的語言模型即為
word2vec從大量文字語料中以無監督的方式學習語義資訊,即通過一個嵌入空間使得語義上相似的單詞在該空間內距離很近。比如“機器”和“機械”意思很相近,而“機器”和“猴子”的意思相差就很遠了,那麼由word2vec構建的這個數值空間中,“機器”和“機械”的距離較“機器”和“猴子”的距離而言是要近很多的。
Skip-gram 和 CBOW
不要被這兩個看起來高大上的詞嚇到,其實很簡單。由word2vec思想,即考察前後文的關聯性產生了這兩個模型:Skip-gram是通過一個詞a去預測它周圍的上下文;而CBOW相反,是通過上下文來預測其間的詞。CBOW一般用於資料,而Skip-Gram通常用在資料量較大的情況。
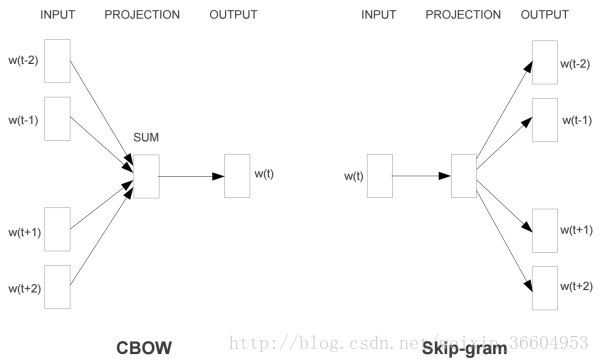
圖1比較直接的展示了比較常規的CBOW和Skip-gram,圖1左側的CBOW給出了文字中一個詞語
前文說過,word2vec輸出是神經網路的權重值,用這些值組成詞向量,它的輸入就是我們文字中的詞(將文字按一定顆粒度切分為詞語和字),但是輸入進計算機的文字依然是無法被計算機識別啊?該怎麼進入這個過程呢?答案就是——one hot encoder。one hot encoder就是一個只含有1個1,其他都為0的值構成的向量。如果全世界的詞一共有N個,為了簡單起見,假設N是3,這3個詞分別是“我”、“是”、“帥哥”(別罵我不要臉~~~),那麼很顯然,“我”就可以被編碼為(1,0,0),“是”編碼為(0,1,0),“帥哥”編碼為(0,0,1)。這樣的數值向量是完全可以被計算機識別和處理的。
言歸正傳,我們先來看一看Skip-gram模型。我們的輸入已經明確了,再明確一下我們的輸出:Skip-gram是一個單隱藏層的神經網路結構,那麼我們要找的詞向量其實就是輸入層到第一個隱藏層的權重(也就是圖1中Project層的權重值)。
這裡,引入“視窗”和“skip-num”的概念,舉個例子,比如有這麼一句話:“中秋月亮比往常圓”,“中秋”、“月亮”、“比”、“往常”、“圓”作為6個獨立的詞,如果我們的輸入是“月亮”,視窗設為2,skip-num也是2,那麼我們會得到兩組輸入-輸出:(月亮,中秋)和(月亮,比),假如先使用(月亮,中秋)作為神經網路的輸入和輸出進行訓練,那麼神經網路會輸出整個文字中每個詞作為“月亮”的輸出的概率,也就是給定這組輸入輸出資料時,輸入是“月亮”,輸出結果是“中秋”的概率,即文字中每個詞與輸入值“月亮”相鄰出現的概率(當然,這個例子沒用對文字進行one hot encoder,是為了方便解釋和理解,讀著可以自行把它們假想為0-1向量,不想也沒關係,小編覺得這樣看得見摸得著不抽象的例子才能讓大家都看懂)。
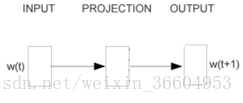
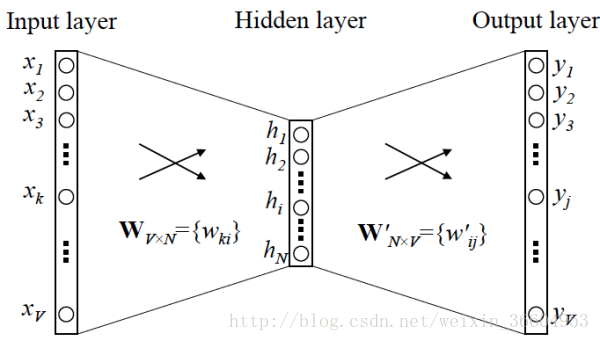
現在假設我們的Skip-gram是一個最簡單的情況,用一個輸入詞去預測它相鄰的一個詞,如圖2和圖3所示(圖3是圖2的展開、細化模式)。那麼請接著看圖4,如果我們的詞表中有10000個詞,那麼每個詞進行one-hot編碼後,就會是一個10000維的向量,其中9999個都是0,只有一個是1。從輸入層到隱藏層沒有使用啟用函式,但在輸出層中使用了softmax(不用怕,這個東西很簡單,後面會介紹的,目前你只要把它簡單理解成為類似邏輯迴歸中的logstic變換即可)。
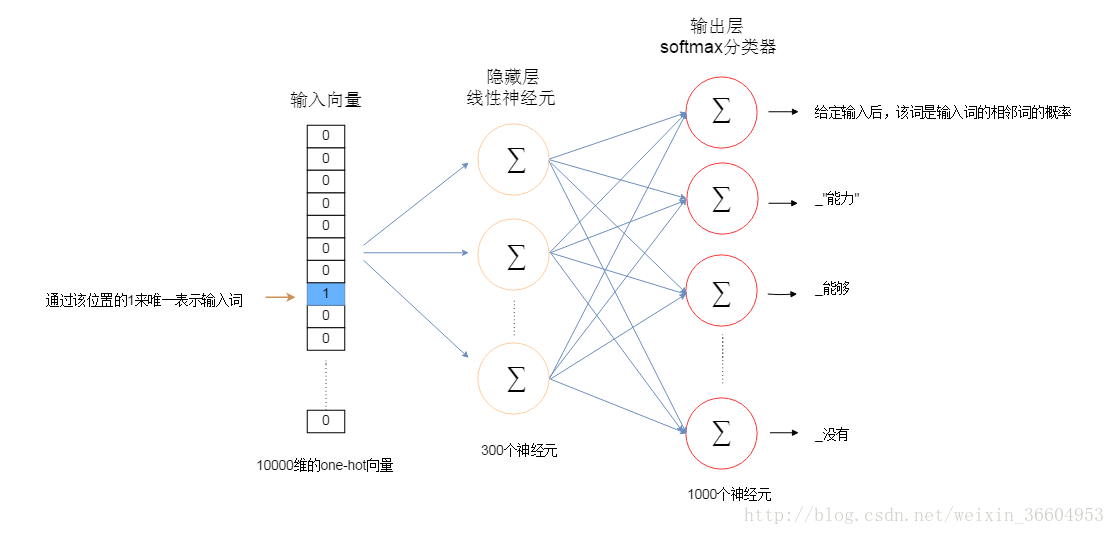
輸出層理所當然也是10000維的向量,每個值就是按照輸入的這個詞,可以得到自己本身的概率,這個10000維的向量其實就是一個概率分佈。
我們關注的點在隱藏層,如果我們想用將每個詞表示為一個維度為100的向量,即每個詞有100個特徵,那麼隱藏層就是一個10000行×100列的矩陣(也就是隱藏層有100個結點),這個10000×100的矩陣就是我們最後想要的結果,它會將10000個詞中的每一個表示為一個100維的向量,有木有發現,10000維的詞瞬間被降維到了100維,當然這個權重矩陣中的值就不是0-1了。輸入是一個1×10000的向量,隱藏層是一個10000×100的矩陣,這兩個矩陣做乘法運算看似需要耗費很多的計算資源,其實並沒有,計算機根本沒有在運算(也沒有在偷懶哈),它只是做了一個“查表”的工作,也就是對權重矩陣做了一個“提取”的動作,只提識別1×10000的向量中那個不為0的值對應的索引,並且從10000×100的矩陣中提取該索引所對應的行。簡單展示如下:
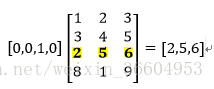
最終得到這個1×100的向量。在輸出層通過softmax進行變換,使輸出層每個結點將會輸出一個0-1之間的值(概率),這些所有輸出層結點的概率之和為1。
CBOW是同樣的道理(如果按照最簡單的情況,Skip-gram用一個輸入詞預測它後面的詞,CBOW用一個輸出詞去預測它前面的一個詞,其實是一模一樣的套路)。
一點補充:理論部分的最後一點就是對前文的softmax進行一點簡單的說明:softmax函式如下所示,
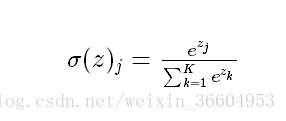
Python實現word2vec
好了,到此為止,word2vec的原理相比讀者已經瞭如指掌了,是不是有些蠢蠢欲動,摩拳擦掌了?那麼我們用一個簡單的小例子來實現一下word2vec吧~請讀者自行搭建開發環境,小編使用的是Python3+加JupyterNotebook的環境,當然,讀者可以使用Pycharm、Spyder等任何IDE進行練習~。請安裝好jieba和gensim。在命令列使用pip install jieba和pip install genism即可安裝。
好了,小編我選取的文字是小說《神鵰俠侶》,其實網上有很多開源的語料,不過比較大,這裡為了方便大家練習,故找了一個內容比較多且資料比較小的文字(當然,語料越充實,效果會越好),這個語料大家可以去網上隨意搜尋。語料如圖5所示。
import jieba
novel = open('E:/神鵰俠侶.txt','r')
content=novel.read()
novel_segmented = open('E:/神鵰俠侶_segmented.txt','w')
cutword = jieba.cut(content,cut_all=False)
seg = ' '.join(cutword).replace(',','').replace('。','').replace('“','').replace('”','').replace(':','').replace('…','')\
.replace('!','').replace('?','').replace('~','').replace('(','').replace(')','').replace('、','').replace(';','')
print(seg,file=novel_segmented)
novel.close()
novel_segmented.close()首先,載入jieba庫,對文字進行分詞,以行為單位逐行讀入文字,對每行(line)進行分詞,cut_all=False為精確模式(預設情況也是精確模式),然後將文字中的標點符號替換為空,即去除標點符號,然後將分詞結果存入novel_segmented中。
分詞後的部分結果如圖6所示。

from gensim.models import word2vec
# 訓練word2vec模型,生成詞向量
from gensim.models import word2vec
# 訓練word2vec模型,生成詞向量
s = word2vec.LineSentence('E:/神鵰俠侶_segmented.txt')
# 這裡如果報編碼錯誤,只需將‘神鵰俠侶_segmented.txt’用、notepad++開啟,然後轉碼為對應編碼即可。
model = word2vec.Word2Vec(s,size=20,window=5,min_count=5,workers=4)
model.save('E:result.txt')接下來,載入gensim.models的word2vec,訓練我們的模型,並生成詞向量,將模型儲存。我們的模型就是上面程式碼中的model啦~~~已經接近成功了!其中s使我們傳入的分詞後的文字,size就是前文中所說的詞向量的維度,window即前文中引入的“視窗”概念,min_count是一個閾值,如果詞語的頻數少於這個閾值,將會從詞表中刪除或者說忽略該詞(預設也是5),workers是控制並行數的引數,如果沒有特殊需求,使用預設值一般就可以得到非常不錯的效果。
好了,模型已經誕生了!那麼來看看我們的模型可以帶給我們哪些資訊吧。首先,我們會有詞表中每個詞語的詞向量表示,比如我的偶像楊過大俠,來看看“楊過”的詞向量吧,圖7中給出了一個20維(維度即size的值)的向量,這就是“楊過”的詞向量。

前文中提到過,word2vec表示的詞語的詞向量有這樣的特徵:經常一起出現的詞,其詞向量的相似度會高,那麼我們來看看圖8給出的楊過和一些主角的相似度吧!果然,楊過小龍女永遠是珍愛啊!!!

至此為止,fastText文字分類的前篇——word2vec的介紹就告一段落了,加下來,就要進入目前業界最流行最常用的快到起飛的文字分類演算法fastText了。欲知後事如何,且聽下回講解!