Spark自帶的叢集模式(Standalone),Spark/Spark-ha叢集搭建
#1、Spark自帶的叢集模式
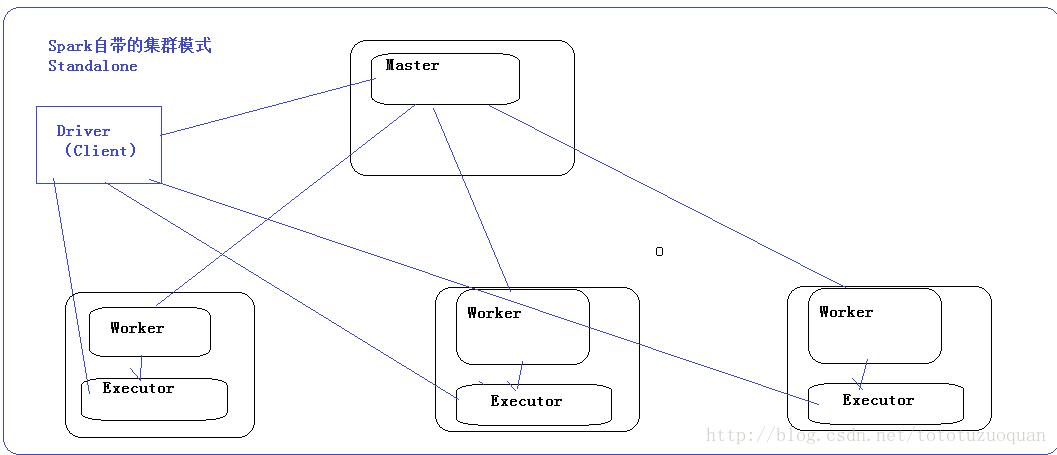
對於Spark自帶的叢集模式,Spark要先啟動一個老大(Master),然後老大Master和各個小弟(Worker)進行通訊,其中真正幹活的是Worker下的Executor。關於提交任務的,需要有一個客戶端,這個客戶端叫做Driver.這個Driver首先和Master建立通訊,然後Master負責資源分配,然後讓Worker啟動Executor,然後Executor和Driver進行通訊。效果圖如下:
#2、Spark叢集搭建(先非HA—>再HA)
##2.1. 機器準備
A:準備5臺Linux伺服器(hadoop1(Master),hadoop2(Master),hadoop3(worker),hadoop4(worker),hadoop5(worker))
B:安裝好/usr/local/jdk1.8.0_73
[[email protected] software] cd /home/tuzq/software
[[email protected] software] tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /home/tuzq/software
[[email protected] software]# cd spark-2.1.1-bin-hadoop2.7
[[email protected] spark-2.1.1-bin-hadoop2.7]# ls
bin conf data examples jars LICENSE licenses NOTICE python R README.md RELEASE sbin yarn
[ ##2.3. 配置Spark
進入到Spark安裝目錄
cd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7
進入conf目錄並重命名並修改spark-env.sh.template檔案
[[email protected] spark-2.1.1-bin-hadoop2.7]# cd conf/
[[email protected] conf]# pwd
/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/conf
[ 在該配置檔案中新增如下配置
export JAVA_HOME=/usr/local/jdk1.8.0_73
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
儲存退出
重新命名並修改slaves.template檔案
mv slaves.template slaves
vi slaves
在該檔案中新增子節點所在的位置(Worker節點)
hadoop3
hadoop4
hadoop5
儲存退出
配置環境變數:
vim /etc/profile
#set spark env
export SPARK_HOME=/home/tuzq/software/spark-2.1.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
將配置好的Spark拷貝到其他節點上
cd /home/tuzq/software
scp -r spark-2.1.1-bin-hadoop2.7 [email protected]:$PWD
scp -r spark-2.1.1-bin-hadoop2.7 [email protected]:$PWD
scp -r spark-2.1.1-bin-hadoop2.7 [email protected]:$PWD
scp -r spark-2.1.1-bin-hadoop2.7 [email protected]:$PWD
Spark叢集配置完畢,目前是1個Master,3個Work,在hadoop1上啟動Spark叢集
/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
執行結果:

如果想停止,就用:
/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/sbin/stop-all.sh
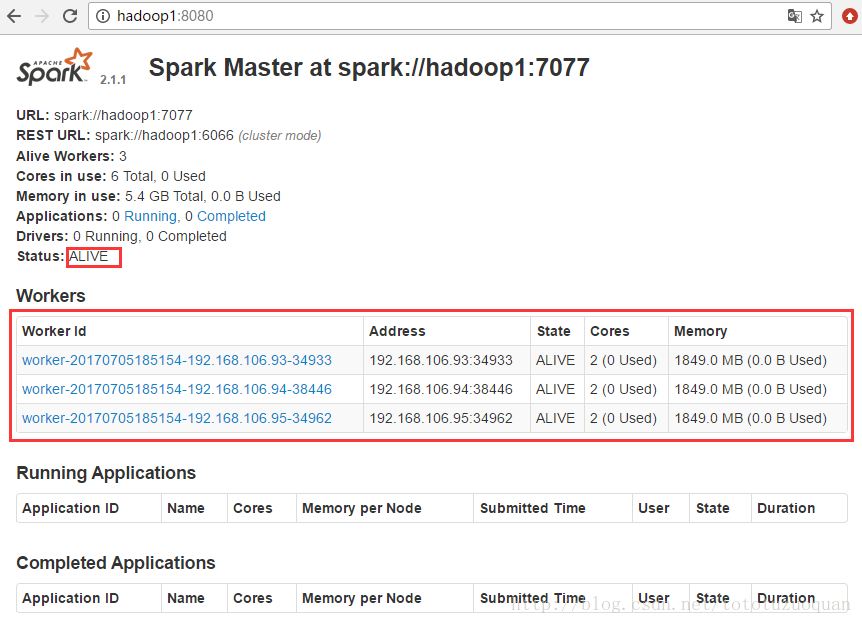
啟動後執行jps命令,主節點上有Master程序,其他子節點上有Work進行,登入Spark管理介面檢視叢集狀態(主節點):http://hadoop1:8080/
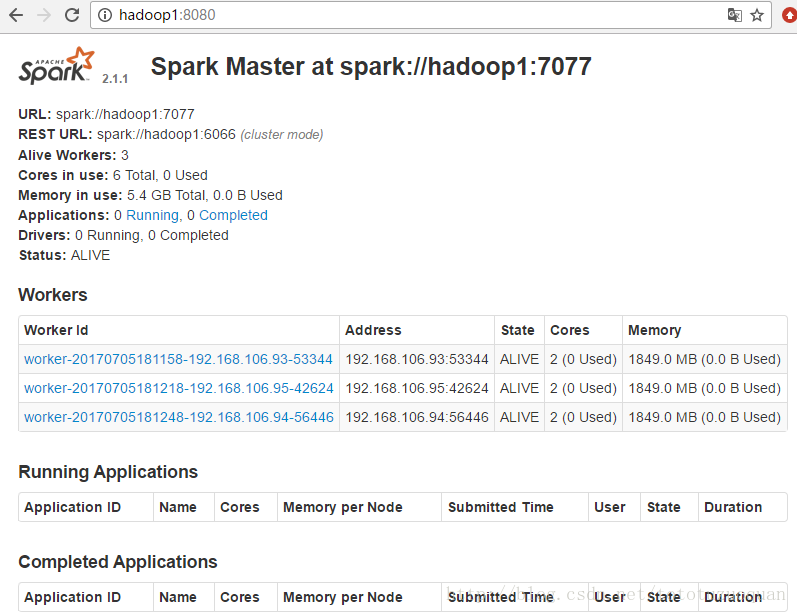
#2.4.Spark-Ha叢集配置
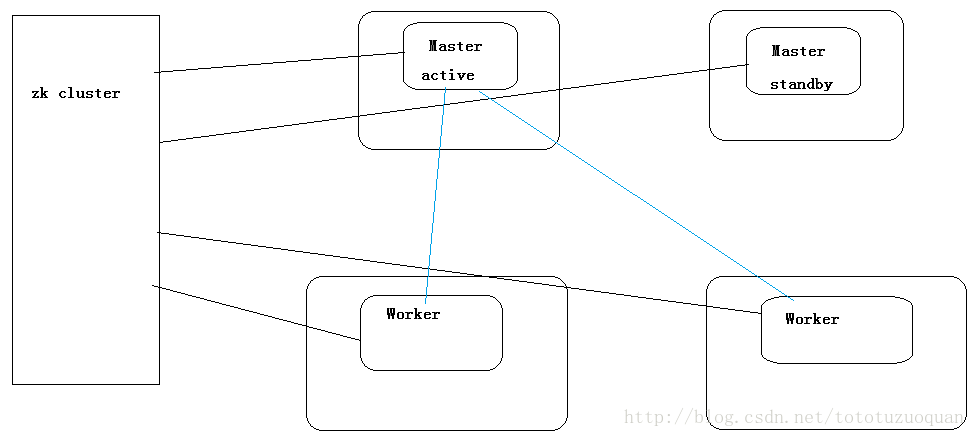
到此為止,Spark叢集安裝完畢,但是有一個很大的問題,那就是Master節點存在單點故障,要解決此問題,就要藉助zookeeper,並且啟動至少兩個Master節點來實現高可靠,配置方式比較簡單:
Spark叢集規劃:hadoop1,hadoop2是Master;hadoop3,hadoop4,hadoop5是Worker
安裝配置zk叢集,並啟動zk叢集(hadoop11,hadoop12,hadoop13)
停止spark所有服務,修改配置檔案spark-env.sh,在該配置檔案中刪掉SPARK_MASTER_IP並新增如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop11,hadoop12,hadoop13 -Dspark.deploy.zookeeper.dir=/spark"
效果如下:

將修改的配置同步到hadoop2,hadoop3,hadoop4,hadoop5這些機器上
[[email protected] conf]# pwd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/conf
[[email protected] conf]# scp -r * [email protected]:$PWD
[[email protected] conf]# scp -r * [email protected]:$PWD
[[email protected] conf]# scp -r * [email protected]:$PWD
[[email protected] conf]# scp -r * [email protected]:$PWD
1. 在hadoop1節點上修改slaves配置檔案內容指定worker節點(本篇部落格上hadoop3,hadoop4,hadoop5為worker,hadoop1和hadoop2 master)
2. 在hadoop1上執行sbin/start-all.sh指令碼,然後在hadoop2上執行sbin/start-master.sh啟動第二個Master(注意在啟動之前先停止啟動了的單叢集)
[[email protected] ~]# cd $SPARK_HOME
[[email protected] spark-2.1.1-bin-hadoop2.7]# sbin/start-all.sh

[[email protected] ~]# cd $SPARK_HOME
[[email protected] spark-2.1.1-bin-hadoop2.7]# sbin/start-master.sh

3、接著訪問http://hadoop1:8080/:
效果如下:
上面的狀態是:ALIVE狀態
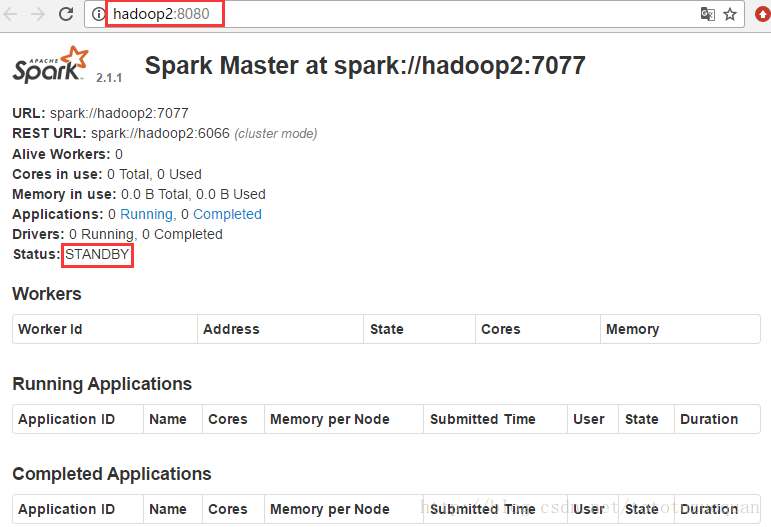
接著訪問http://hadoop2:8080/:
上面的狀態是:STANDBY狀態,通過上面的這些現象可以知道Spark叢集已經搭建成功