
各種排序演算法總結篇(快速/堆/希爾/歸併)
1.快速排序
交換排序有:冒泡(選擇)排序和快速排序,冒泡和選擇排序的時間複雜度太高,思想很簡單暫時不討論,快速排序基於一種分治的思想,逐步地使得序列有序。
#include <iostream> #include <conio.h> using namespace std; int arrs[] = { 23, 65, 12, 3, 8, 76, 345, 90, 21, 75, 34, 61 }; int arrLen = sizeof(arrs) / sizeof(arrs[0]); void quickSort(int * arrs, int left, int right){ //挖坑填坑法 int oldLeft = left; int oldRight = right; bool flag = true; int baseArr = arrs[oldLeft]; // 先挑選一個基準元素 //從陣列的右端開始向前找,一直找到比base小的數字為止(包括base同等數) while (left < right){ while (left < right && arrs[right] >= baseArr){ right--; flag = false; } arrs[left] = arrs[right]; //最終找到了比baseNum小的元素,要做的事情就是此元素放到base的位置 while (left < right && arrs[left] <= baseArr){ //從左端開始向後找,一直找到比base大的數字為止(包括base同等數) left++; flag = false; } arrs[right] = arrs[left]; //最終找到了比baseNum大的元素,要做的事情就是將此元素放到最後的位置 } arrs[left] = baseArr; //最後就是把baseNum放到該left的位置,最終,我們發現left位置的左側數值部分比base小, // left位置右側數值比base大.至此,我們完成了第一篇排序 if (!flag){ //如果在排序的過程中,發現存在需要交換的位置,則兩邊可能無序,繼續對基準的左右分治處理 quickSort(arrs, oldLeft, left-1); quickSort(arrs, left+1, oldRight); } } int main() { quickSort(arrs, 0, arrLen - 1); for (int i = 0; i < arrLen; i++) cout << arrs[i] << endl; getch(); return 0; }
2、堆排序
堆排序屬於選擇排序範圍,選擇排序主要包括:直接選擇排序和堆排序,直接選擇排序很簡單,與氣泡排序很相似,但減少了交換操作的次數,在小規模時,選擇排序效率是比較高的。堆排序主要用在取前N個最大(小)值時。
堆定義
堆實際上是一棵完全二叉樹,其任何一非葉節點滿足性質:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2](小頂堆)或者:Key[i]>=Key[2i+1]&&key>=key[2i+2](大頂堆)
即任何一非葉節點的關鍵字不大於或者不小於其左右孩子節點的關鍵字。
堆排序的思想
利用大頂堆(小頂堆)堆頂記錄的是最大關鍵字(最小關鍵字)這一特性,使得每次從無序中選擇最大記錄(最小記錄)變得簡單。
其基本思想為(大頂堆):
將初始待排序關鍵字序列(R1,R2....Rn)構建成大頂堆,此堆為初始的無序區;
將堆頂元素R[1]與最後一個元素R[n]交換,此時得到新的無序區(R1,R2,......Rn-1)和新的有序區(Rn),且滿足R[1,2...n-1]<=R[n];
由於交換後新的堆頂R[1]可能違反堆的性質,因此需要對當前無序區(R1,R2,......Rn-1)調整為新堆,然後再次將R[1]與無序區最後一個元素交換,得到新的無序區(R1,R2....Rn-2)和新的有序區(Rn-1,Rn)。不斷重複此過程直到有序區的元素個數為n-1,則整個排序過程完成。
#include <iostream> using namespace std; int arrs[] = { 23, 65, 12, 3, 8, 76, 345, 90, 21, 75, 34, 61 }; int arrLen = sizeof(arrs) / sizeof(arrs[0]); void adjustHeap(int * arrs, int p, int len){ int curParent = arrs[p]; int child = 2* p + 1; //左孩子 while(child < len){ //沒有孩子 if(child+1<len&&arrs[child]<arrs[child+1]){ child++; //較大孩子的下標 } if(curParent<arrs[child]){ arrs[p]=arrs[child]; //沒有將curParent賦值給孩子是因為還要迭代子樹, //如果其孩子中有大的,會上移,curParent還要繼續下移。 p=child; child=2*p+1; } else break; } arrs[p]=curParent; } void heapSort(int * arrs, int len){ //建立堆,從最底層的父節點開始 for(int i = arrLen /2 -1; i>=0; i--) adjustHeap(arrs, i, arrLen); for(int i = arrLen -1; i>=0; i--){ int maxEle = arrs[0]; arrs[0] = arrs[i]; arrs[i] = maxEle; adjustHeap(arrs, 0, i); } } int main() { heapSort(arrs, arrLen ); for (int i = 0; i < arrLen; i++) cout << arrs[i] << endl; return 0; }
3、插入排序(直接插入,希爾,歸併)
插入排序包括:直接插入排序、希爾排序、歸併排序。
直接插入排序演算法,將陣列劃分為兩種,“有序陣列塊”和“無序陣列塊”,一個個從無序陣列取出元素,插入到有充陣列的合適位置上,即完成排序,最大的缺點在於要對陣列元素進行移動。
希爾排序
希爾排序加入了一種叫做“縮小增量排序法”的思想,增量取法為:count/2、(count/2)/2、...、1。
希爾演算法實現如下:
#include <iostream>
using namespace std;
int arrs[] = { 23, 65, 12, 3, 8, 76, 345, 90, 21, 75, 34, 61 };
int arrLen = sizeof(arrs) / sizeof(arrs[0]);
void shellSort(int * arrs)
{
int step = arrLen / 2; //初始增量
while(step > 0)
{
//無序部分
for(int i = step; i < arrLen; i++)
{
int temp = arrs[i];
int j;
//子序列中的插入排序,這是有序部分
for(j = i-step; j>=0 && temp < arrs[j]; j=j-step)
//在找到當前元素合適位置前,元素後移
arrs[j+step]=arrs[j];
arrs[j+step]=temp;
}
step /= 2;
}
}
int main()
{
shellSort(arrs);
for (int i = 0; i < arrLen; i++)
cout << arrs[i] << endl;
return 0;
}歸併排序
歸併排序是採用分治法的一個非常典型的應用,它要做兩件事情:
第一: “分”, 就是將陣列儘可能的分,一直分到原子級別。
第二: “並”,將原子級別的數兩兩合併排序,最後產生結果。
至於二個有序數列合併,只要比較二個數列的第一個數,誰小就先取誰安放到臨時佇列中,取了後將對應數列中這個數刪除,直到一個數列為空,再將另一個數列的資料依次取出即可。
#include <iostream>
using namespace std;
int arrs[] = { 23, 65, 12, 3, 8, 76, 345, 90, 21, 75, 34, 61 };
int arrLen = sizeof(arrs) / sizeof(arrs[0]);
int * tempArr = new int[arrLen];
void mergeArray(int * arrs, int * tempArr, int left, int middle, int right){
int i = left, j = middle ;
int m = middle + 1, n = right;
int k = 0;
while(i <= j && m <= n){
if(arrs[i] <= arrs[m])
tempArr[k++] = arrs[i++];
else
tempArr[k++] = arrs[m++];
}
while(i <= j)
tempArr[k++] = arrs[i++];
while(m <= n)
tempArr[k++] = arrs[m++];
for(i=0; i < k; i++)
arrs[left + i] = tempArr[i];
}
void mergeSort(int * arrs, int * tempArr, int left, int right){
if(left < right){
int middle = (left + right)/2;
mergeSort(arrs, tempArr, left, middle);
mergeSort(arrs, tempArr, middle + 1, right);
mergeArray(arrs, tempArr, left, middle, right);
}
}
int main()
{
mergeSort(arrs, tempArr, 0, arrLen-1);
for (int i = 0; i < arrLen; i++)
cout << arrs[i] << endl;
return 0;
}維基百科,歸併排序
歸併操作(merge),也叫歸併演算法,指的是將兩個已經排序的序列合併成一個序列的操作。歸併排序演算法依賴歸併操作。
迭代法[編輯]
- 申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合併後的序列
- 設定兩個指標,最初位置分別為兩個已經排序序列的起始位置
- 比較兩個指標所指向的元素,選擇相對小的元素放入到合併空間,並移動指標到下一位置
- 重複步驟3直到某一指標到達序列尾
- 將另一序列剩下的所有元素直接複製到合併序列尾
遞迴法[編輯]
原理如下(假設序列共有n個元素):
- 將序列每相鄰兩個數字進行歸併操作,形成
 個序列,排序後每個序列包含兩個元素
個序列,排序後每個序列包含兩個元素 - 將上述序列再次歸併,形成
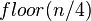 個序列,每個序列包含四個元素
個序列,每個序列包含四個元素 - 重複步驟2,直到所有元素排序完畢
int min(int x, int y)
{
return x < y ? x : y;
}
void merge_sort(int arr[], int len)
{
int* a = arr;
int* b = (int*) malloc(len * sizeof(int*));
int seg, start;
for (seg = 1; seg < len; seg += seg)
{
for (start = 0; start < len; start += seg + seg)
{
int low = start, mid = min(start + seg, len), high = min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int* temp = a;
a = b;
b = temp;
}
if (a != arr)
{
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}void merge_sort_recursive(int arr[], int reg[], int start, int end)
{
if (start >= end)
return ;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
// 將兩端拍好序的區間進行歸併操作
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
void merge_sort(int arr[], const int len)
{
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}歸併排序是建立在歸併操作上的一種有效的排序演算法。該演算法是採用分治法(Divide
and Conquer)的一個非常典型的應用。
首先考慮下如何將將二個有序數列合併。這個非常簡單,只要從比較二個數列的第一個數,誰小就先取誰,取了後就在對應數列中刪除這個數。然後再進行比較,如果有數列為空,那直接將另一個數列的資料依次取出即可。
//將有序陣列a[]和b[]合併到c[]中
void MemeryArray(int a[], int n, int b[], int m, int c[])
{
int i, j, k;
i = j = k = 0;
while (i < n && j < m)
{
if (a[i] < b[j])
c[k++] = a[i++];
else
c[k++] = b[j++];
}
while (i < n)
c[k++] = a[i++];
while (j < m)
c[k++] = b[j++];
} 可以看出合併有序數列的效率是比較高的,可以達到O(n)。
解決了上面的合併有序數列問題,再來看歸併排序,其的基本思路就是將陣列分成二組A,B,如果這二組組內的資料都是有序的,那麼就可以很方便的將這二組資料進行排序。如何讓這二組組內資料有序了?
可以將A,B組各自再分成二組。依次類推,當分出來的小組只有一個數據時,可以認為這個小組組內已經達到了有序,然後再合併相鄰的二個小組就可以了。這樣通過先遞歸的分解數列,再合並數列就完成了歸併排序。
//將有二個有序數列a[first...mid]和a[mid...last]合併。
void mergearray(int a[], int first, int mid, int last, int temp[])
{
int i = first, j = mid + 1;
int m = mid, n = last;
int k = 0;
while (i <= m && j <= n)
{
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while (i <= m)
temp[k++] = a[i++];
while (j <= n)
temp[k++] = a[j++];
for (i = 0; i < k; i++)
a[first + i] = temp[i];
}
void mergesort(int a[], int first, int last, int temp[])
{
if (first < last)
{
int mid = (first + last) / 2;
mergesort(a, first, mid, temp); //左邊有序
mergesort(a, mid + 1, last, temp); //右邊有序
mergearray(a, first, mid, last, temp); //再將二個有序數列合併
}
}
bool MergeSort(int a[], int n)
{
int *p = new int[n];
if (p == NULL)
return false;
mergesort(a, 0, n - 1, p);
delete[] p; // new 申請記憶體空間沒有delete(或者malloc後沒有free)都可能會造成記憶體洩露
return true;
} 歸併排序的效率是比較高的,設數列長為N,將數列分開成小數列一共要logN步,每步都是一個合併有序數列的過程,時間複雜度可以記為O(N),故一共為O(N*logN)。因為歸併排序每次都是在相鄰的資料中進行操作,所以歸併排序在O(N*logN)的幾種排序方法(快速排序,歸併排序,希爾排序,堆排序)也是效率比較高的。
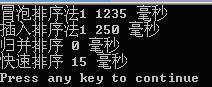
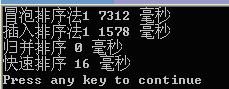
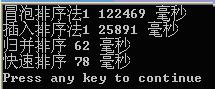
在本人電腦上對氣泡排序,直接插入排序,歸併排序及直接使用系統的qsort()進行比較(均在Release版本下)
對20000個隨機資料進行測試:
對50000個隨機資料進行測試:
再對200000個隨機資料進行測試:
注:有的書上是在mergearray()合併有序數列時分配臨時陣列,但是過多的new操作會非常費時。因此作了下小小的變化。只在MergeSort()中new一個臨時陣列。後面的操作都共用這一個臨時陣列。