
Go語言-for語句
阿新 • • 發佈:2019-01-03
for語句代表著迴圈。一條語句通常由關鍵字for、初始化子句、條件表示式、後置子句和以花括號包裹的程式碼塊組成。其中,初始化子句、條件表示式和後置子句之間需用分號分隔。示例如下:
for i := 0; i < 10; i++ {
fmt.Print(i, " ")
} 我們可以省略掉初始化子句、條件表示式、後置子句中的任何一個或多個,不過起到分隔作用的分號一般需要被保留下來,除非在僅有條件表示式或三者全被省略時分號才可以被一同省略。
我們可以把上述的初始化子句、條件表示式、後置子句合稱為for子句。實際上,for語句還有另外一種編寫方式,那就是用range子句替換掉for
range子句包含一個或兩個迭代變數(用於與迭代出的值繫結)、特殊標記:=或=、關鍵字range以及range表示式。其中,range表示式的結果值的型別應該是能夠被迭代的,包括:字串型別、陣列型別、陣列的指標型別、切片型別、字典型別和通道型別。例如:for i, v := range "Go語言" {
fmt.Printf("%d: %c\n", i, v)
} 對於字串型別的被迭代值來說,for語句每次會迭代出兩個值。第一個值代表第二個值在字串中的索引,而第二個值則代表該字串中的某一個字元。迭代是以索引遞增的順序進行的。例如,上面的for語句被執行後會在標準輸出上打印出:
0: G 1: o 2: 語 5: 言
可以看到,這裡迭代出的索引值並不是連續的。下面我們簡單剖析一下此表象的本質。我們知道,字串的底層是以位元組陣列的形式儲存的。而在Go語言中,字串到位元組陣列的轉換是通過對其中的每個字元進行UTF-8編碼來完成的。字串"Go語言"中的每一個字元與相應的位元組陣列之間的對應關係如下:
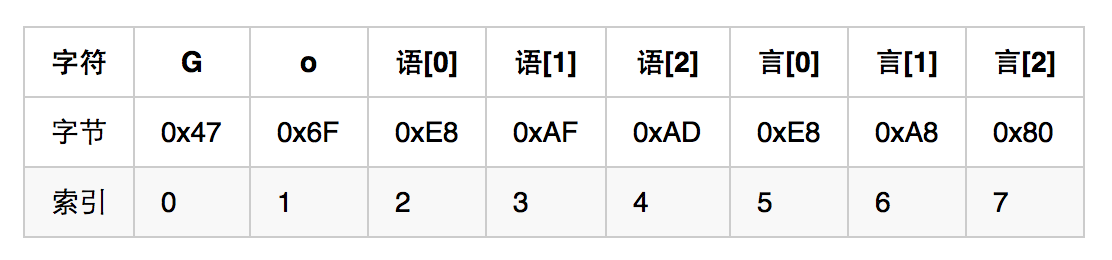
注意,一箇中文字元在經過UTF-8編碼之後會表現為三個位元組。所以,我們用語[0]、語[1]和、語[2]分別表示字元'語'經編碼後的第一、二、三個位元組。對於字元'言',我們如法炮製。
對照這張表格,我們就能夠解釋上面那條for語句打印出的內容了,即:每次迭代出的第一個值所代表的是第二個字元值經編碼後的第一個位元組在該字串經編碼後的位元組陣列中的索引值。請大家真正理解這句話的含義。
對於陣列值、陣列的指標值和切片之來說,range
對於字典值來說,
range子句每次仍然會迭代出兩個值。顯然,第一個值是字典中的某一個鍵,而第二個值則是該鍵對應的那個值。注意,對字典值上的迭代,Go語言是不保證其順序的。攜帶
range子句的for語句還可以應用於一個通道值之上。其作用是不斷地從該通道值中接收資料,不過每次只會接收一個值。注意,如果通道值中沒有資料,那麼for語句的執行會處於阻塞狀態。無論怎樣,這樣的迴圈會一直進行下去。直至該通道值被關閉,for語句的執行才會結束。最後,我們來說一下
break語句和continue語句。它們都可以被放置在for語句的程式碼塊中。前者被執行時會使其所屬的for語句的執行立即結束,而後者被執行時會使當次迭代被中止(當次迭代的後續語句會被忽略)而直接進入到下一次迭代。