
IBM專家親自解讀 Spark2.0 操作指南
Spark 背景介紹
1、什麼是Spark
在Apache的網站上,有非常簡單的一句話,”Spark is a fast and general engine ”,就是Spark是一個統一的計算引擎,而且突出了fast。那麼具體是做什麼的呢?是做large-scale的processing,即大資料的處理。
“Spark is a fast and general engine for large-scale processing”這句話非常簡單,但是它突出了Spark的一些特點:第一個特點就是spark是一個並行式的、記憶體的計算密集型的計算引擎。
那麼來說記憶體的,因為Spark是基於Map Reduce的,但是它的空間資料不是存在於HDFS上面,而是存在於記憶體中,所以他是一個記憶體式的計算,這樣就導致Spark的計算速度非常得快,同時它可以部署在叢集上,所以它可以分佈到各個的節點上,並行式地計算;Spark上還有很多機器學習和資料探勘的學習包,使用者可以利用學習包進行資料的迭代式計算,所以它又是一個計算密集型的計算工具。
2、Spark的發展歷程
瞭解完什麼是Spark之後,我們看一下Spark的發展歷程。

Spark 2009年作為研究專案建立,13年成為Apache的孵化專案,14年成為Apache的頂級專案,Spark2.0還沒有正式釋出,目前只有比較draft的版本。
3、Spark2.0的最新特性
Spark2.0是剛出的,今天主要講解它的兩個部分,一個是它的new feature,就是它有哪些新的特性;另一部分是community,大家知道Spark是一個開源社群,社群對Spark的發展功不可沒。

在feature這一部分,可以看到,Spark2.0中有比較重要的兩個部分,其中一個就是Structured API。
Spark2.0統一了DataFrame和Dataset,並且引入了新的SparkSession。SparkSession提供了一個新的切入點,這個切入點統一了sql和sql context,對使用者來說是透明的,使用者不需要再去區分用什麼context或者怎麼建立,直接用SparkSession就可以了。還有一個是結構化的流,streaming。在Spark2.0中,流和bash做了一個統一,這樣的話對使用者來說也是透明的,就不在區分什麼是流處理,什麼是批量處理的資料了。
後面幾個特性,比如MLlib,相信對data scientists非常有吸引力。MLlib可以將使用者訓練過的模型儲存下來,等需要的時候再匯入所需要的訓練模型;從R上來說,原來SparkR上支援的只是單機單節點的,不支援分散式的計算,但是R的分散式的開發在Spark2.0中是非常有力的feature。此外,在Spark2.0中,SQL 2003的support可以讓Spark在對結構化的資料進行處理的時候,基本上支援了所有的SQL語句。
4、為什麼使用Spark
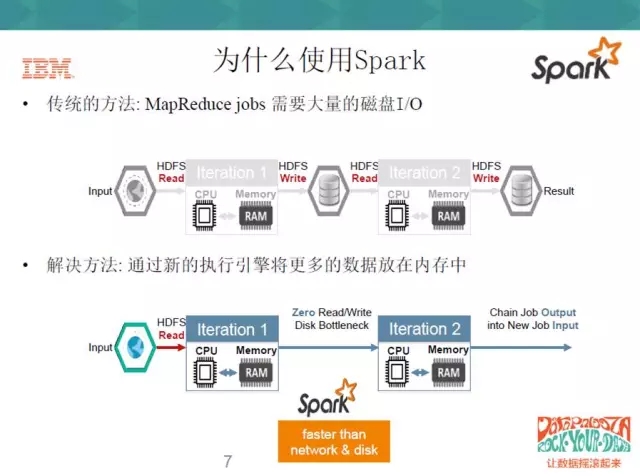
在傳統方法中,MapReduce需要大量的磁碟I/O,從對比圖中可以看到,MapReduce會將大量的資料存在HDFS上,而Spark因為是記憶體式的,就不需要大量的磁碟I/O,這一塊就會非常快。

效能方面,在通用的任務上,Spark可以提高20-100倍的速度,因此Spark效能的第一點就是快;第二個就是比較高效,用過Scala開發程式的人應該有感受,Spark語法的表達非常強大,原來可能用十行去描述一段匹配的程式碼,Scala可能一行就可以做到,所以它效率非常地高,包括它也支援一些主流的程式設計的語言,java,Python,Scala,還有R等。
此外,Spark2.0可以利用已有的資產。大家知道hadoop的生態系統是非常有吸引力的,Spark可以很好地和hadoop的生態系統結合在一起。上面我們提到了社群的貢獻,社群的貢獻者不斷得對Spark進行 improvement,使得Spark的發展越來越好,而且速度越來愈快。
以上這些特點導致了Spark現在越來越流行,更多的data scientists包括學者都願意去使用Spark,Spark讓大資料的計算更簡單,更高效,更智慧。
5、IBM對Spark的支援

IBM內部對Spark也是越來越重視,主要支援力度體現在社群培育、產品化和Spark Core上。社群方面,big data university的線上課程內容十分豐富,包括資料科學家、包括最基礎的語言的開發,包括Spark、Hadoop生態基礎的培訓都很多,所以它培訓了超過了一百萬的資料科學家,並且贊助了AMP Lab,AMP Lab就是Spark開源社群的開發者。
第二個就是對Spark Core的貢獻,因為在IBM內部,已經建立了Spark技術中心,超過了300名的工程師在進行Spark Core的開發。並且IBM開源的機器學習庫,也成為了databricks的合作伙伴。
產品方面,在CDL就有一些Spark產品,整合到IBM本身的AOP環境裡面,(注:AOP也是一個開源的軟體包),包括Big Insight裡面都集成了Spark的元素,IBM總共投入了超過3500名的員工在Spark的相關工作上。
Spark 基礎
1、Spark核心元件

在Spark Build-in元件中,最基礎的就是Spark Core,它是所有應用程式架構的基礎。SparkSQL、Spark Streaming、MLLib、GraphX都是Spark Build-in元件提供的應用元件的子架構。
SparkSQL是對結構化資料的處理,Spark Streaming是對實時流資料的處理 ,MLLib就是對機器學習庫的處理,GraphX是對並行圖計算的處理。
不管是哪一個應用上的子架構,它都是基於RDD上的應用框架。實際上使用者可以基於RDD來開發出不同領域上的子框架,運用Spark Build-in元件來執行。
2、Spark應用程式的架構
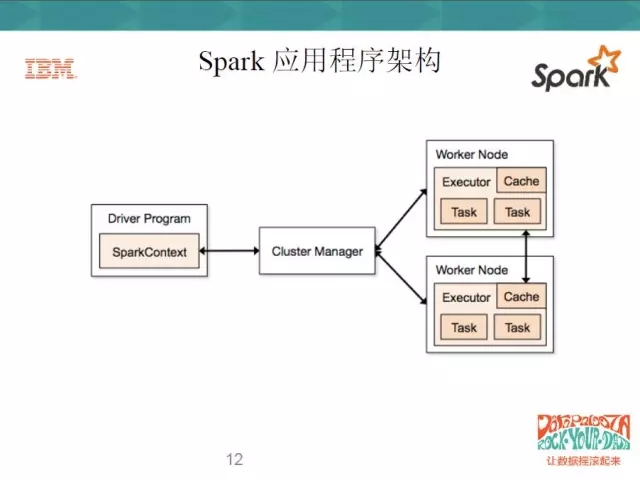
在每一個Spark應用程式中,只有一個Driver Program,和若干個Executor。大家可以看到右邊的Work Node,我們可以認為Work Node就是一個物理機器,所有的應用程式都是從Driver開始的,Driver Program會先初始化一個SparkContext,作為應用程式的入口,每一個Spark應用程式只有一個SparkContext。SparkContext作為入口,再去初始化一些作業排程和任務排程,通過Cluster Manager將任務分配到各個節點上,由Worker Node上面的執行器來執行任務。一個Spark應用程式有多個Executor,一個Executor上又可以執行多個task,這就是Spark平行計算的框架。
此外,Executor除了可以處理task,還可以將資料存在Cache或者HDFS上面。
3、Spark執行模式
一般我們看到的是下圖中的前四種Spark執行模式:Local、standalone、Yarn和Mesos。Cloud就是一種外部base的Spark的執行環境。

Local就是指本地的模式,使用者可以在本地上執行Spark程式,Local[N]即指的是使用多少個執行緒;Standalone是Spark自己自帶的一個執行模式,需要使用者自己去部署spark到相關的節點上;Yarn和Mesos是做資源管理的,它也是Hadoop生態系統裡面的,如果使用Yarn和Mesos,那麼就是這兩者去做資源管理,Spark來做資源排程。
不管是那種執行模式,它都還細分為兩種,一種是client模式:一種是cluster模式,那麼怎麼區分這兩種模式呢?可以用到架構圖中的Driver Program。Driver Program如果在叢集裡面,那就是cluster模式;如果在叢集外面,那就是client模式。
4、彈性分散式資料集RDD
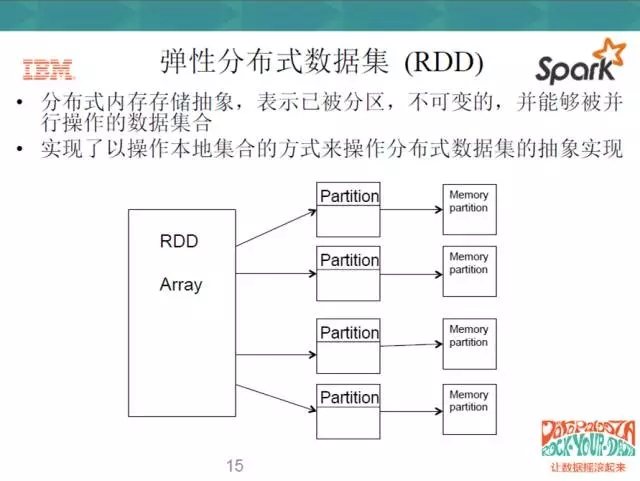
RDD有幾個特點,一是它不可變,二是它被分割槽。我們在java或者C++裡,所用的基本資料集、陣列都可以被更改,但是RDD是不能被更改的,它只能產生新的RDD,也就是說Scala是一種函式式的程式語言。函式式的程式語言不主張就地更改現有的所有的資料,而是在已有的資料上產生一個新的資料,主要是做transform的工作,即對映的工作。
RDD不可更改,但可以分佈到不同的Partition上,對使用者來說,就實現了以操作本地集合的方式來操作分散式資料集的抽象實現。RDD本身是一個抽象的概念,它不是真實存在的,那麼它分配到各個節點上,對使用者來說是透明的,使用者只要按照自己操作本地資料集的方法去操作RDD就可以了,不用管它是怎麼分配到各個Partition上面的。
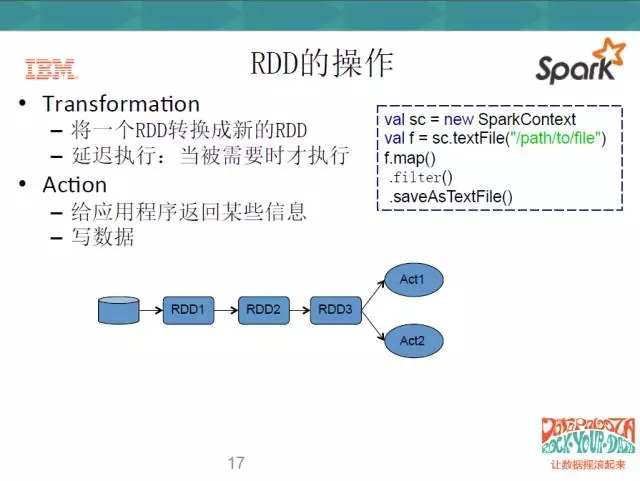
在操作上,RDD主要有兩種方式,一種是Transform,一種是Action。Transform的操作呢,就是將一個RDD轉換成一個新的RDD,但是它有個特點,就是延遲執行;第二種操作就是Action,使用者要麼寫資料,要麼給應用程式返回某些資訊。當你執行Action的時候,Transform才會被觸發,這也就是延遲執行的意思。
看一下右邊的程式碼,這是一個Scala的程式碼,在第一行,它去建立了一個Spark的Context,去讀一個檔案。然後這個檔案做了三個操作,第一個是map,第二個是filter,第三個是save,前面兩個動作就是一個Transform,map的意思就是對映,filter就是過濾,save就是寫。當我”寫”的這個程度執行到map和filter這一步時,它不會去執行,等我的save動作開始的時候,它才會執行去前面兩個。
5、Spark程式的執行
瞭解了RDD和Spark執行原理之後,我們來從整體看一下Spark程式是怎麼執行的。
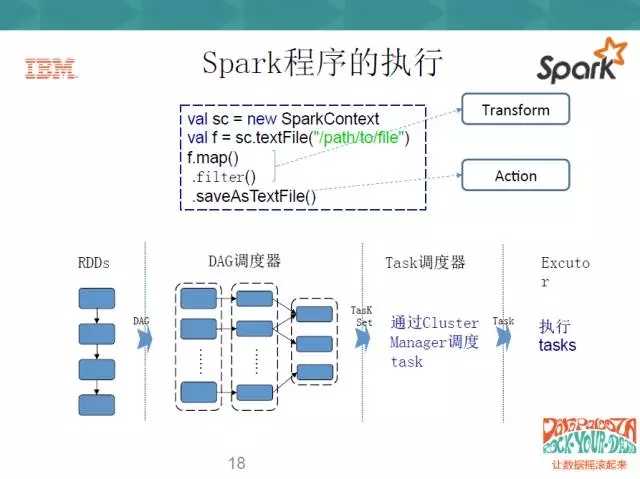
還是之前的三行程式碼,前兩步是Transform,最後一步是Action。那麼這一系列RDD就做一系列的Transform,從第一步開始轉;DAG就是一個排程器,Spark context會初始化一個任務排程器,任務排程器就會將RDD的一系列轉換切分成不同的階段,由任務排程器將不同的階段上分成不同的task set,通過Cluster Manager去排程這些task,把這些task set分佈到不同的Executor上去執行。
6、Spark DataFrame
很多人會問,已經有RDD,為什麼還要有DataFrame?DataFrame API是2015年釋出的,Spark1.3之後就有,它是以命名列的方式去組織分散式的資料集。

Spark上面原來主要是為了big data,大資料平臺,它很多都是非結構化資料。非結構化資料需要使用者自己去組織對映,而DataFrame就提供了一些現成的,使用者可以通過操作關係表去操作大資料平臺上的資料。這樣很多的data scientists就可以使用原來使關係資料庫的只是和方式去操作大資料平臺上的資料。
DataFrame支援的資料來源也很多,比如說JSON、Hive、JDBC等。
DataFrame還有存在的另外一個理由:我們可以分析上表,藍色部分代表著RDD去操縱不同語言的同樣數量集時的效能。可以看到,RDD在Python上的效能比較差,Scala的效能比較好一些。但是從綠色的部分來看,用DataFrame來編寫程式的時候,他們的效能是一樣的,也就是說RDD在操作不同的語言時,效能表現不一樣,但是用DataFrame去操作時,效能表現是一樣的,並且效能總體要高於RDD。
下面是DataFrame的一個簡單示例。
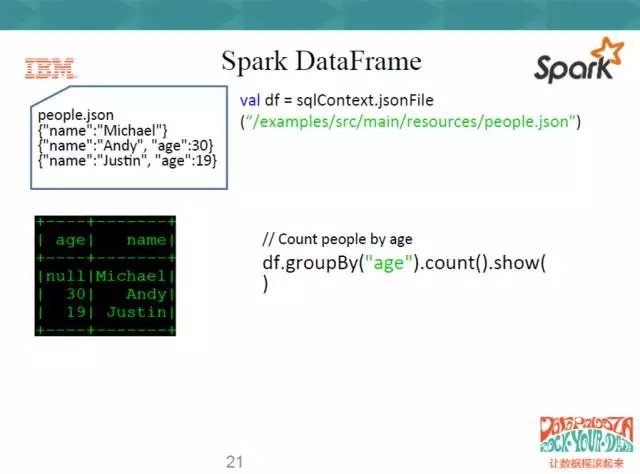
右邊同樣是用Scala寫的一段程式碼,這就是sqlContext,因為它支援JSON檔案,直接點JsonFile,讀進來這個json檔案。下面直接對這個DataFrame
df.groupBy(“ages”).count().show(),show出來的方式就是一個表的方式。這個操作就很簡單,使用者不用再做map操作,如果是用RDD操作的話,使用者需要自己對數列裡的每一塊資料作處理。
7、Spark程式語言
在程式語言上,Spark目前支援的有以下四種:
8、Spark使用方式

使用上,如果本地有Spark叢集,就有兩種操作方式:一種是用Spark-shell,即互動式命令列;互動式的命令操作很簡單,就和java一樣,一行一行敲進去,它會互動式地告訴你,一行一行包括的是什麼;這個地方也可以把一段程式碼複製過去,邊執行邊除錯。一般來講,互動式命令用Local模式就可以了。
第二種是直接用Spark-submit,一般在開發工程專案時使用較多;Spark-submit有幾個必要的引數,一個是master,就是執行模式必須有;還有幾個引數也必須有,比如class,java包的位置等。此外可以根據Spark-submit後面的help命令,來檢視submit有多少引數,每個引數是什麼意思。
此外可以通過Web-based NoteBook來使用Spark,在IBM的workbench上提供了Jupyter和Zepplin兩種NoteBook的方式。