
(筆記)網路壓縮量化,訓練三值量化TRAINED TERNARY QUANTIZATION
阿新 • • 發佈:2019-01-03
原文連結:
摘要
提供一個三值網路的訓練方法。對AlexNet在ImageNet的表現,相比32全精度的提升0.3%。
方法
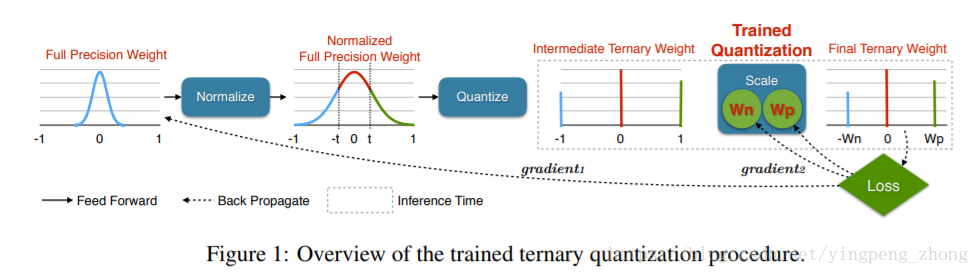
對於每一層網路,三個值是32bit浮點的,、是可訓練的引數。另外32bit浮點的模型也是訓練的物件,但是閾值是不可訓練的。
由公式(6)從32bit浮點的到量化的三值:
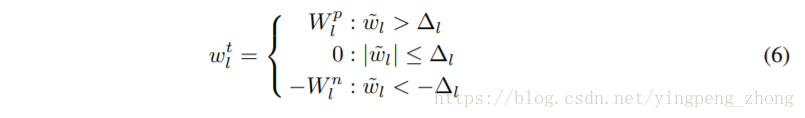
由(7)算出、的梯度
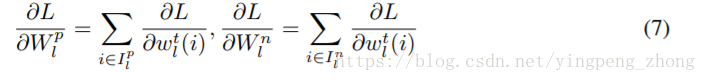
其中
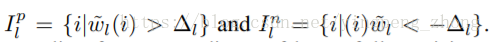
由(8)算出32bit浮點模型的梯度
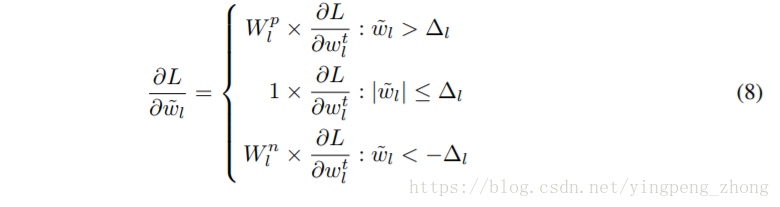
由(9)給出閾值,這種方法在CIFAR-10的實驗中使用閾值t=0.05。而在ImageNet的實驗中,並不是由通過欽定閾值的方式進行量化的劃分,而是欽定0值的比率r,即稀疏度。

整個流程如Figure 1所示
實驗效果
ResNets on CIFAR-10

AlexNet on ImageNet,第一層卷積和最後一層FC用的32bit浮點權重,其它用的三值權重。

ResNet-18 on ImageNet

討論
稀疏度為0(即二值網路)不好,稀疏度太大也不好,30%~50%最好,如Figure 5。用閾值t比稀疏度r更好,這樣各層可以找到自己合適的稀疏度。

最後看一下三值的AlexNet的卷積核
