
【Python】 csv模組的使用
Python csv模組的使用
1、csv簡介
格式,用以儲存表格資料,包括數字或者字元。很多程式在處理資料時都會碰到csv這種格式的檔案,它的使用是比
較廣泛的(Kaggle上一些題目提供的資料就是csv格式),csv雖然使用廣泛,但卻沒有通用的標準,所以在處理csv
格式時常常會碰到麻煩,幸好python內建了csv模組。下面簡單介紹csv模組中最常用的一些函式。
2、csv模組中的函式
- reader(csvfile, dialect='excel', **fmtparams)
引數說明:
csvfile,必須是支援迭代(Iterator)的物件,可以是檔案(file)物件或者列表(list)物件,如果是檔案對象,開啟時需要加"b"標誌引數。dialect,編碼風格,預設為excel的風格,也就是用逗號(,)分隔,dialect方式也支援自定義,通過呼叫register_dialect方法來註冊,下文會提到。fmtparam,格式化引數,用來覆蓋之前dialect物件指定的編碼風格。
import csv
with open('test.csv','rb') as myFile:
lines=csv.reader(myFile)
for line in lines:
print line'test.csv'是檔名,‘rb’中的r表示“讀”模式,因為是檔案物件,所以加‘b’。open()返回了一個檔案物件
myFile,reader(myFile)只傳入了第一個引數,另外兩個引數採用預設值,即以excel風格讀入。reader()返回一個
reader物件lines,lines是一個list,當呼叫它的方法lines.next()時,會返回一個string。上面程式的效果是將csv
檔案中的文字按行列印,每一行的元素都是以逗號分隔符','分隔得來。
在我的test.csv檔案中,儲存的資料如圖:
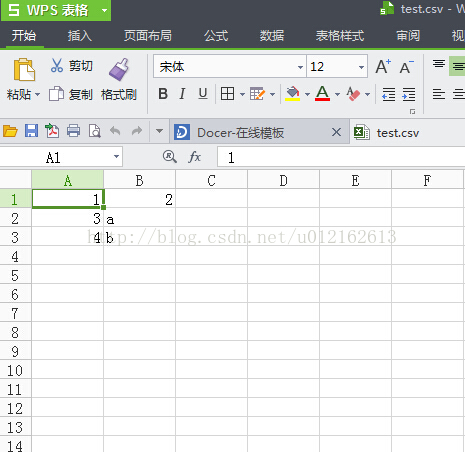
程式輸出:
['1', '2']
['3', 'a']
['4', 'b']
- writer(csvfile, dialect='excel', **fmtparams)
引數的意義同上,這裡不贅述,直接上例程:
with open('t.csv','wb') as myFile:
myWriter=csv.writer(myFile)
myWriter.writerow([7,'g'])
myWriter.writerow([8,'h'])
myList=[[1,2,3],[4,5,6]]
myWriter.writerows(myList)'w'表示寫模式。
首先open()函式開啟當前路徑下的名字為't.csv'的檔案,如果不存在這個檔案,則建立它,返回myFile檔案物件。
csv.writer(myFile)返回writer物件myWriter。
writerow()方法是一行一行寫入,writerows方法是一次寫入多行。
注意:如果檔案't.csv'事先存在,呼叫writer函式會先清空原檔案中的文字,再執行writerow/writerows方法。
補充:除了writerow、writerows,writer物件還提供了其他一些方法:writeheader、dialect
- register_dialect(name, [dialect, ]**fmtparams)
這個函式是用來自定義dialect的。
引數說明:
name,你所自定義的dialect的名字,比如預設的是'excel',你可以定義成'mydialect'
[dialect, ]**fmtparams,dialect格式引數,有delimiter(分隔符,預設的就是逗號)、quotechar、
csv.register_dialect('mydialect',delimiter='|', quoting=csv.QUOTE_ALL)上面一行程式自定義了一個命名為mydialect的dialect,引數只設置了delimiter和quoting這兩個,其他的仍然採用
預設值,其中以'|'為分隔符。接下來我們就可以像使用'excel'一樣來使用'mydialect'了。我們來看看效果:
在我test.csv中儲存如下資料:
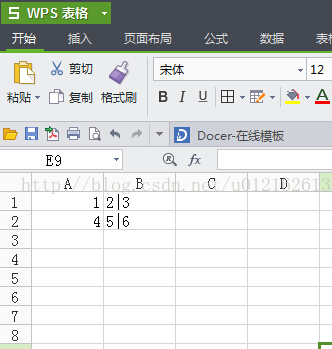
以'mydialect'風格列印:
with open('test.csv','rb') as myFile:
lines=csv.reader(myFile,'mydialect')
print lines.line_num
for line in lines:
print line輸出:
['1,2', '3']
['4,5', '6']
可以看到,現在是以'|'為分隔符,1和2合成了一個字串(因為1和2之間的分隔符是逗號,而mydialect風格的分隔
符是'|'),3單獨一個字串。
對於writer()函式,同樣可以傳入mydialect作為引數,這裡不贅述。
- unregister_dialect(name)
這個函式用於登出自定義的dialect
此外,csv模組還提供get_dialect(name)、list_dialects()、field_size_limit([new_limit])等函式,這些都比較
簡單,可以自己試試。比如list_dialects()函式會列出當前csv模組裡所有的dialect:
print csv.list_dialects()輸出:
['excel-tab', 'excel', 'mydialect']
'mydialect'是自定義的,'excel-tab', 'excel'都是自帶的dialect,其中'excel-tab'跟'excel'差不多,
只不過它以tab為分隔符。
csv模組還定義了
一些類:DictReader、DictWriter、Dialect等,DictReader和DictWriter類似於reader和writer。
一些常量:QUOTE_ALL、QUOTE_MINIMAL、.QUOTE_NONNUMERIC等,這些常量可以作為Dialects and Formatting Parameters的值。
先寫到這,其他的以後用到再更新。