大資料_資料採集引擎(Sqoop和Flume)
阿新 • • 發佈:2019-01-03
一、資料採集引擎
1、準備實驗環境: 準備Oracle資料庫
使用者:sh 表:sales 訂單表(92萬)
2、Sqoop:採集關係型資料庫中的資料
用在離線計算的應用中
強調:批量
(1)資料交換引擎: RDBMS <---> Sqoop <---> HDFS、HBase、Hive
(2)底層依賴MapReduce
(3)依賴JDBC
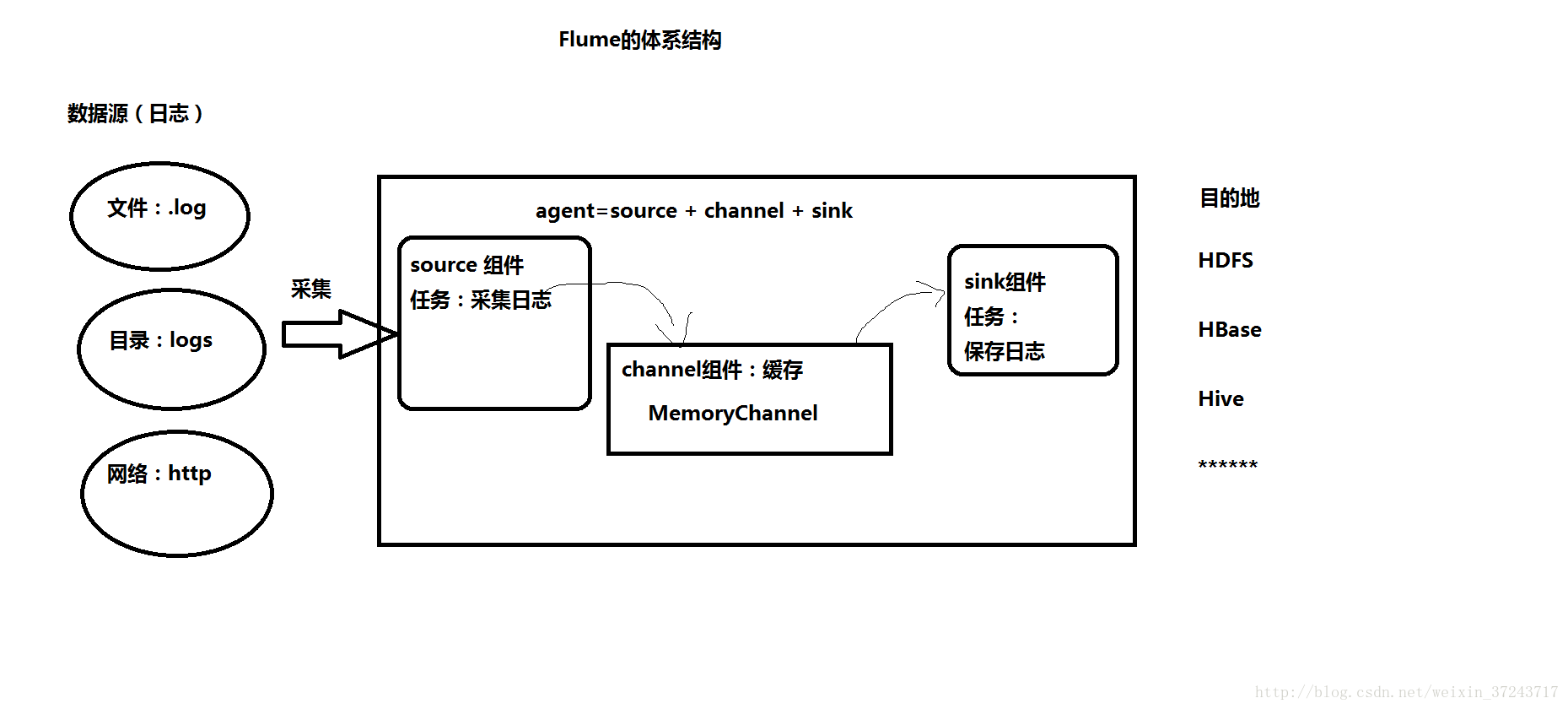
(4 Flume的體系結構
二、HUE
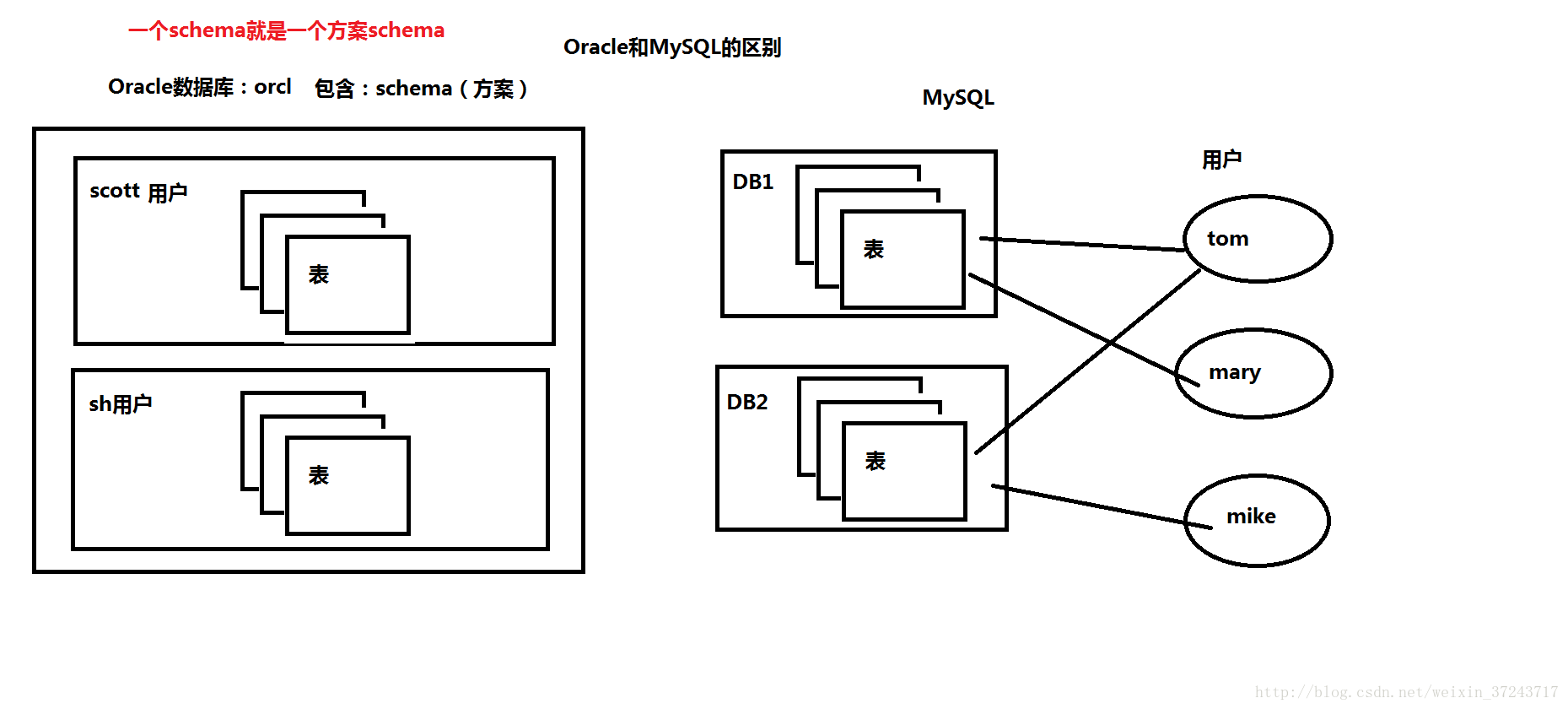
三、ZooKeeperOracle和Mysql的區別