
caffe for windows的matlab介面(四):權重和特徵圖視覺化的一個例子
模型讀取
參照三,想實現一個自己影象的視覺化過程:
首先我發現自己訓練出的model沒有deploy檔案。查閱了下:“如果要把訓練好的模型拿來測試新的圖片,那必須得要一個deploy.prototxt檔案,這個檔案實際上和test.prototxt檔案差不多,只是頭尾不相同而也。deploy檔案沒有第一層資料輸入層,也沒有最後的Accuracy層,但最後多了一個Softmax概率層。”
記得我用的是CaffeNet,於是我在E:\CaffeDev\caffe-master\models\bvlc_reference_caffenet目錄下找到了這個檔案,把它拷貝到資料資料夾裡方便查閱和管理。
首先還是讀取模型:
caffe.set_mode_cpu();%設定CPU模式
model = 'F:/CaffeDev/caffe-master/data/myself8chuli100test4/deploy.prototxt';%模型
weights ='F:/CaffeDev/caffe-master/data/myself8chuli100test4/1900/caffenet_train_iter_900.caffemodel';%引數
net=caffe.Net(model,'test');%測試
net.copy_from(weights); %得到訓練好的權重引數
net %顯示net的結構 然後遇到比較嚴肅的一個問題,當進行到把weights copy到net中去的時候,matlab停止工作了。。。比較尷尬,因為我用的就是現有的CaffeNet,怎麼會出現這個問題呢。。。

反思了一下想起來我修改過影象的大小引數。。。
原來是輸入256大小,進行了一次227的裁剪。而我是直接輸入128,裁剪也是128.第一次做的時候經驗不足,其實最好是把影象做一個原始大小基礎上的裁剪和變換,這樣準確率應該會有所提高。
最後是原始是分類1000,我的是分類100,在deploy.prototxt裡也要做相應的修改。
修改過後再執行,就沒有問題啦~我們看到了這個模型的結構。突然發現和(三)的net是一個呀。。。暈死。。。看來這篇價值不大,只是重複驗證而已。
輸入資料整理
這是我用了標號為1的人的第一隻採集手掌:1_1.bmp
這張影象是經過加強處理的,我們可以很清晰地看到它的紋路,如下圖,(後續還會用採集的原圖,然後用到剪裁和對準,可能也能體現出CNN相比傳統識別方法魯棒性的一個提升。)

過程第一步是先把均值讀進來,原來自帶的例子是讀取了一個自帶的mat均值檔案,開始我想把的二值化的均值檔案image_mean.binaryproto轉換為均值mat檔案,但一直沒找到解決的好辦法。
一個簡單粗暴的解決方案:
pic = imread(‘1_1.bmp’);%讀取圖片
pic = imread('1_1.bmp');%讀取圖片
pic_mean=mean2(pic)
for i=1:128
for j=1:128
for k=1:3
A(i,j,k)=140.0021;
end
end
end
B=single(A);
save my_mean_data B先說一下過程,
①先把均值讀進來
d = load('F:\CaffeDev\mat2\my_mean_data.mat'); mean_data = d.B; ②讀取圖片
im = imread('F:\CaffeDev\mat2\1_2.bmp');%讀取圖片
IMAGE_DIM = 128;%影象將要resize的大小,建議resize為影象最小的那個維度
CROPPED_DIM = 128;%待會需要把一張圖片crops成十塊,最終softmax求出每一塊可能的標籤 把黑白輸入影象轉換為彩色:(為了套用官網彩色影象,不出錯的一個無奈之舉···)
function y = gray2rgb( x )
% x is the gray image
% y is the rgb image
d = size(x);
temp = zeros(d(1),d(2),3);
temp(:,:,1) = x;
temp(:,:,2) = x;
temp(:,:,3) = x;
y = temp;im = gray2rgb( m )im_data = im(:, :, [3, 2, 1]); %matlab按照RGB讀取圖片,opencv是BGR,所以需要轉換順序為opencv處理格式
im_data = permute(im_data, [2, 1, 3]); % 原始影象m*n*channels,現在permute為n*m*channels大小
im_data = single(im_data); % 強制轉換資料為single型別
im_data = imresize(im_data, [IMAGE_DIM IMAGE_DIM], 'bilinear'); % 線性插值resize影象先零均值化一下,然後按照deploy和train的prototxt,將這隻手掌crop(分成)十塊,採用的是classification.demo的分割方法,分別取手掌的上下左右四個角以及中心的大小為deploy中提到的128*128大小。這是五個,然後再對圖片翻轉180°;合起來就是代表這隻手掌的十張圖片:
im_data = im_data - mean_data; % 零均值
crops_data = zeros(CROPPED_DIM, CROPPED_DIM, 3, 10, 'single');%注意此處是因為prototxt的輸入大小為寬*高*通道數*10
indices = [0 IMAGE_DIM-CROPPED_DIM] + 1;%獲得十塊每一塊大小與原始影象大小差距,便於crops
%下面就是如何將一張圖片crops成十塊
n = 1;
%此處兩個for迴圈並非是1:indices,而是第一次取indices(1),然後是indices(2),每一層迴圈兩次
%分別讀取圖片四個角大小為CROPPED_DIM*CROPPED_DIM的圖片
for i = indices
for j = indices
crops_data(:, :, :, n) = im_data(i:i+CROPPED_DIM-1, j:j+CROPPED_DIM-1, :);%產生四個角的cropdata,1 2 3 4
crops_data(:, :, :, n+5) = crops_data(end:-1:1, :, :, n);%翻轉180°來一次,產生四個角的翻轉cropdata,6 7 8 9
n = n + 1;
end
end
center = floor(indices(2) / 2) + 1;
%以中心為crop_data左上角頂點,讀取CROPPED_DIM*CROPPED_DIM的塊
crops_data(:,:,:,5) = ...
im_data(center:center+CROPPED_DIM-1,center:center+CROPPED_DIM-1,:);
%與for迴圈裡面一樣,翻轉180°,繞左邊界翻轉
crops_data(:,:,:,10) = crops_data(end:-1:1, :, :, 5);視覺化看看長啥樣:
% im_data = im_data - mean_data; % 零均值
crops_data = zeros(CROPPED_DIM, CROPPED_DIM, 3, 10, 'single');%注意此處是因為prototxt的輸入大小為寬*高*通道數*10
indices = [0 IMAGE_DIM-CROPPED_DIM] + 1;%獲得十塊每一塊大小與原始影象大小差距,便於crops
%下面就是如何將一張圖片crops成十塊
n = 1;
%此處兩個for迴圈並非是1:indices,而是第一次取indices(1),然後是indices(2),每一層迴圈兩次
%分別讀取圖片四個角大小為CROPPED_DIM*CROPPED_DIM的圖片
for i = indices
for j = indices
crops_data(:, :, :, n) = im_data(i:i+CROPPED_DIM-1, j:j+CROPPED_DIM-1, :);%產生四個角的cropdata,1 2 3 4
crops_data(:, :, :, n+5) = crops_data(end:-1:1, :, :, n);%翻轉180°來一次,產生四個角的翻轉cropdata,6 7 8 9
n = n + 1;
end
end
center = floor(indices(2) / 2) + 1;
%以中心為crop_data左上角頂點,讀取CROPPED_DIM*CROPPED_DIM的塊
crops_data(:,:,:,5) = ...
im_data(center:center+CROPPED_DIM-1,center:center+CROPPED_DIM-1,:);
%與for迴圈裡面一樣,翻轉180°,繞左邊界翻轉
crops_data(:,:,:,10) = crops_data(end:-1:1, :, :, 5);
hand_map=zeros(CROPPED_DIM*2,CROPPED_DIM*5,3);%兩行五列展示
hand_num=0;
for i=0:1
for j=0:4
hand_num=hand_num+1
hand_map(CROPPED_DIM*i+1:(i+1)*CROPPED_DIM,CROPPED_DIM*j+1:(j+1)*CROPPED_DIM,:)=crops_data(:,:,:,hand_num);
end
end
imshow(uint8(hand_map))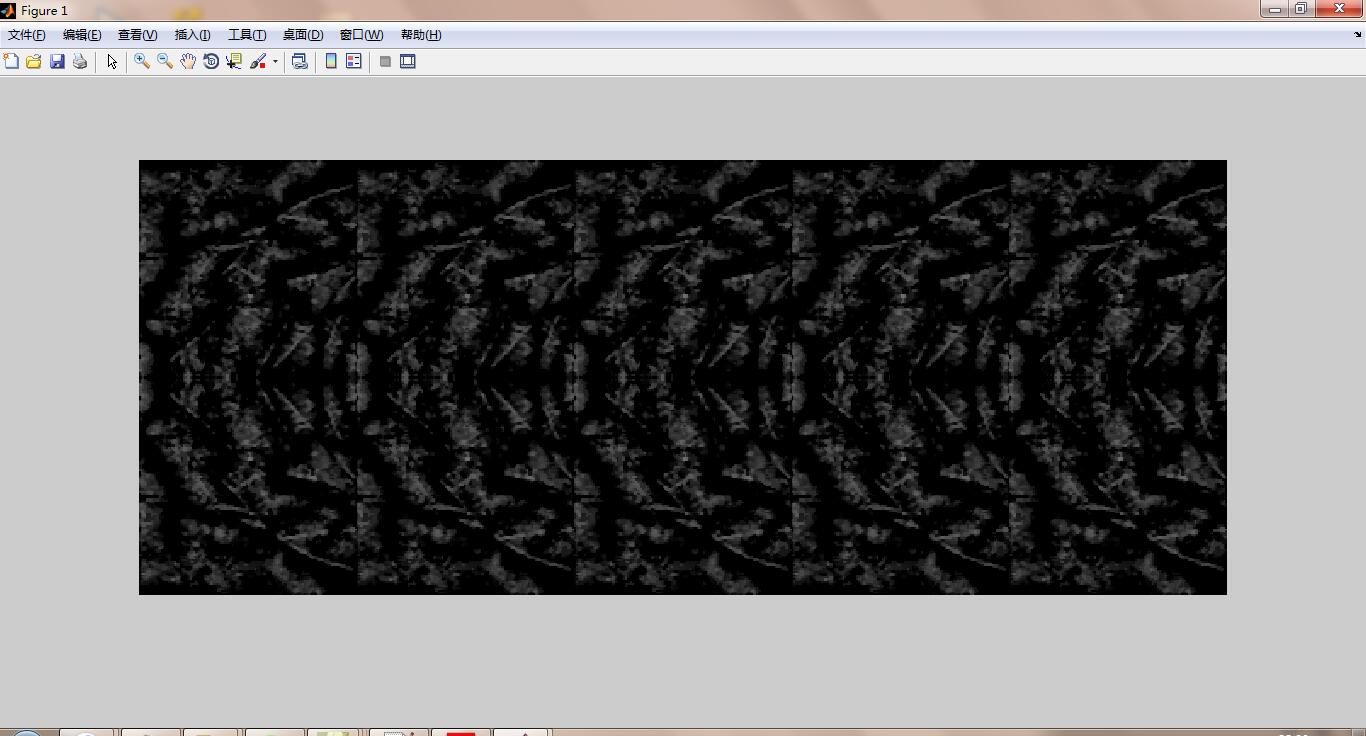
前向計算
res=net.forward({crops_data});
prob=res{1};
prob1 = mean(prob, 2);
[~, maxlabel] = max(prob1); 這一步完畢以後,整個網路就會充滿引數了,權重,特徵圖均生成完畢,接下來視覺化它們。
特徵圖視覺化
特徵圖提取方法
說一下步驟,首先利用net 中的blob_name函式取出與deploy.prototxt對應的 top 名字,顯示一下看看,
names=net.blob_names
names =
'data'
'conv1'
'pool1'
'norm1'
'conv2'
'pool2'
'norm2'
'conv3'
'conv4'
'conv5'
'pool5'
'fc6'
'fc7'
'fc8'
'prob'然後利用blob呼叫get_data()函式獲取我們需要的特徵圖的值。注意,每一層的特徵圖是四維,看看前三層的特徵圖大小:
>>size(net.blobs(names{1}).get_data())
ans =
128 128 3 10
>> size(net.blobs(names{2}).get_data())
ans =
30 30 96 10
>> size(net.blobs(names{3}).get_data())
ans =
15 15 96 10結合deploy中每一層的卷積核大小以及步長,利用 (當前層特徵圖大小 - 卷積核大小) / 步長+1=下一層特徵圖大小,可以推匯出每一個featuremap 的前兩維,第三個維度代表的是卷積核個數,featuremap {2}到featuremap {3}是池化了。第四個維度代表最開始輸入了十張圖
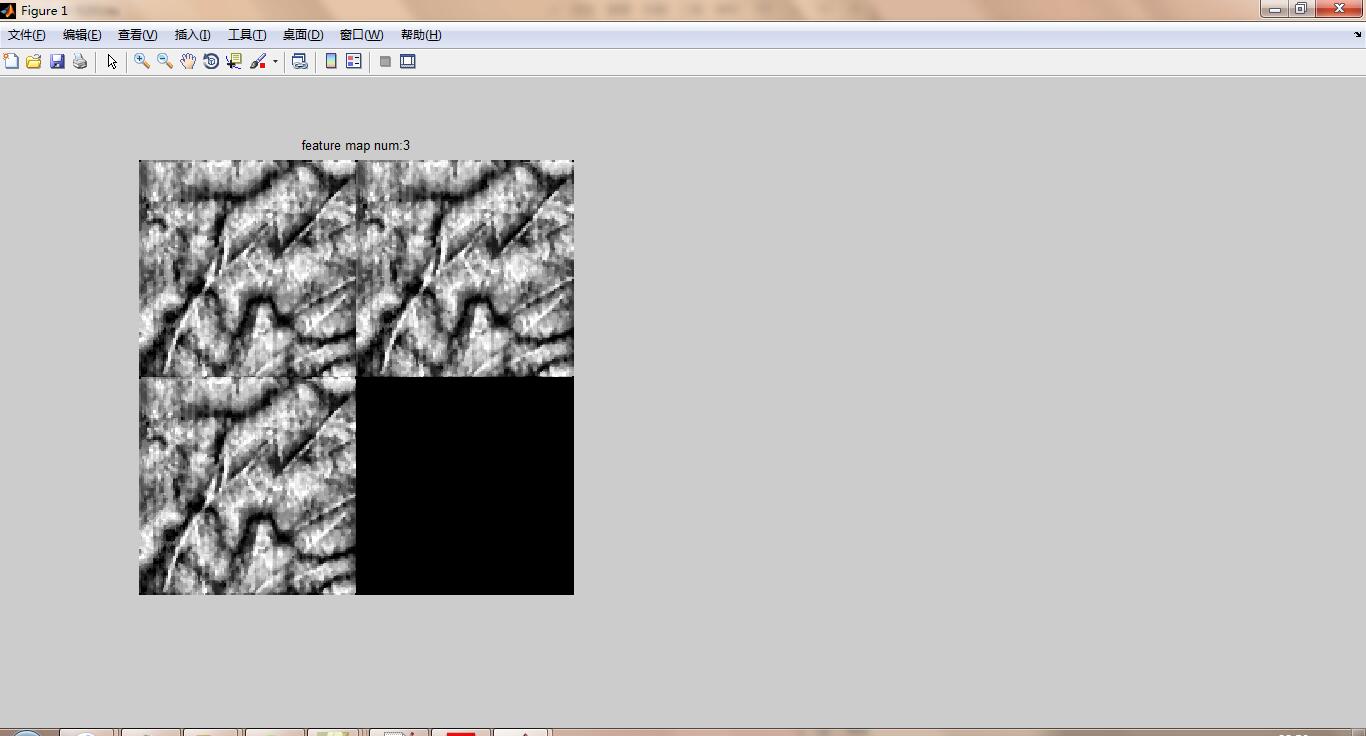
部分視覺化方法
這一部分針對指定的第crop_num張影象在第map_num層進行視覺化。注意,這一部分的視覺化包含池化層等。
function [ ] = feature_partvisual( net,mapnum,crop_num )
names=net.blob_names;
featuremap=net.blobs(names{mapnum}).get_data();%獲取指定層的特徵圖
[m_size,n_size,num,crop]=size(featuremap);%獲取特徵圖大小,長*寬*卷積核個數*通道數
row=ceil(sqrt(num));%行數
col=row;%列數
feature_map=zeros(m_size*row,n_size*col);
cout_map=1;
for i=0:row-1
for j=0:col-1
if cout_map<=num
feature_map(i*m_size+1:(i+1)*m_size,j*n_size+1:(j+1)*n_size)=(mapminmax(featuremap(:,:,cout_map,crop_num),0,1)*255)';
cout_map=cout_map+1;
end
end
end
imshow(uint8(feature_map))
str=strcat('feature map num:',num2str(cout_map-1));
title(str)
end
呼叫方法:
mapnum=1;%第幾層的feature☆☆☆☆☆☆☆☆
crop_num=1;%第幾個crop的特徵圖☆☆☆☆☆☆☆☆
feature_partvisual( net,mapnum,crop_num )中間有個處理細節是歸一化然後乘以255,是避免featuremap的數值過小,或者有負數,導致特徵圖一片漆黑;在下面的權重視覺化方法採取的是另一種處理。
讀者可以更改”☆”標誌的行中的數值去提取不同crop影象的不同層特徵圖。

全部視覺化
這一部分視覺化每一張輸入圖片在指定卷積層的特徵圖,按照每一行為儲存圖片的特徵圖為圖例。
function [ ] = feature_fullvisual( net,mapnum )
names=net.blob_names;
featuremap=net.blobs(names{mapnum}).get_data();%獲取指定層的特徵圖
[m_size,n_size,num,crop]=size(featuremap)%獲取特徵圖大小,長*寬*卷積核個數*圖片個數
row=crop;%行數
col=num;%列數
feature_map=zeros(m_size*row,n_size*col);
for i=0:row-1
for j=0:col-1
feature_map(i*m_size+1:(i+1)*m_size,j*n_size+1:(j+1)*n_size)=(mapminmax(featuremap(:,:,j+1,i+1),0,1)*255)';
end
end
figure
imshow(uint8(feature_map))
str=strcat('feature map num:',num2str(row*col));
title(str)
end 呼叫方法:
mapnum=2;%第幾層的feature☆☆☆☆☆☆☆☆
feature_fullvisual( net,mapnum ) 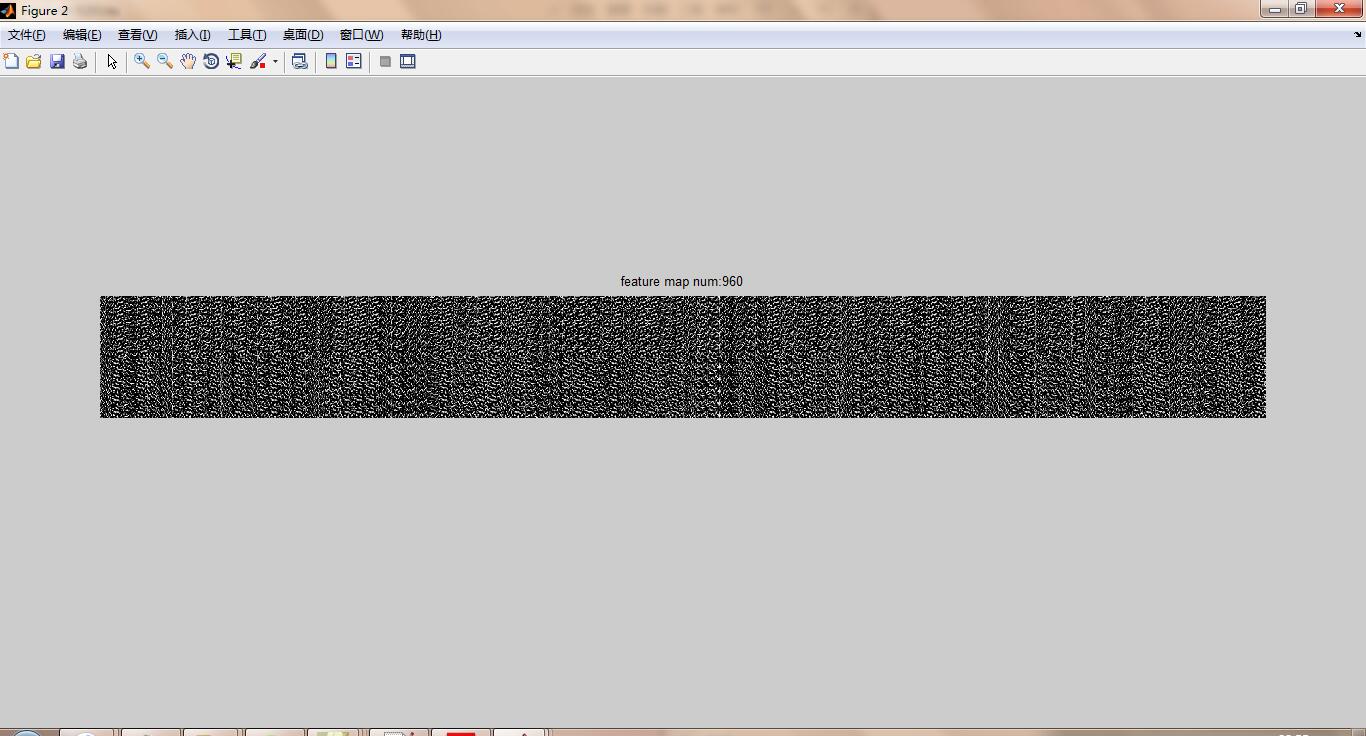
卷積核可視化
卷積核可視化中,採用的畫素放大方法與特徵圖的不一樣。特徵圖中採用歸一化mapminmax到(0,1)範圍,然後乘以255,;在下面卷積核的視覺化中採用(x-最小值)/最大值*255的方法去放大畫素。讀者可根據自己喜好決定。
權重提取方法
通過net 的layer_names 函式能夠獲取deploy.txt 對應的name 的名稱,每一個name的blob對應兩個值,分別是權重和偏置,提取方法如下:
【注】貌似僅僅卷積核能夠獲取到權重,池化層倒是沒有權重,全連線部分也是有權重的,但是沒什麼意義
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')%僅僅卷積核能獲取到權重
convlayer=[convlayer;layers{i}];
end
end
w=cell(1,length(convlayer));%儲存權重
b=cell(1,length(convlayer));%儲存偏置
for i=1:length(convlayer)
w{i}=net.layers(convlayer(i,:)).params(1).get_data();
b{i}=net.layers(convlayer(i,:)).params(2).get_data();
end 提取完畢以後觀察一下每一層的權重維度,發現也是四維,顯示一下前三個卷積核的維度:
size(w{1})
ans =
11 11 3 96
>> size(w{2})
ans =
5 5 48 256
>> size(w{3})
ans =
3 3 256 384前兩個維度不說了,卷積核的大小,第三個維度代表卷積核的左邊,也就是上一層的特徵圖的個數(對應前面說的每一個通道對應不同卷積核),第四個維度代表每一個通道對應的卷積核個數(也就是卷積核右邊下一層的特徵圖的個數)。
部分視覺化方法
那麼我們視覺化也是可選的,需要選擇哪一個特徵圖對應的卷積核,視覺化方法如下:
function [ ] = weight_partvisual( net,layer_num ,channels_num )
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')
convlayer=[convlayer;layers{i}];
end
end
w=net.layers(convlayer(layer_num,:)).params(1).get_data();
b=net.layers(convlayer(layer_num,:)).params(2).get_data();
w=w-min(min(min(min(w))));
w=w/max(max(max(max(w))))*255;
weight=w(:,:,channels_num,:);%四維,核長*核寬*核左邊輸入*核右邊輸出(核個數)
[kernel_r,kernel_c,input_num,kernel_num]=size(w);
map_row=ceil(sqrt(kernel_num));%行數
map_col=map_row;%列數
weight_map=zeros(kernel_r*map_row,kernel_c*map_col);
kernelcout_map=1;
for i=0:map_row-1
for j=0:map_col-1
if kernelcout_map<=kernel_num
weight_map(i*kernel_r+1+i:(i+1)*kernel_r+i,j*kernel_c+1+j:(j+1)*kernel_c+j)=weight(:,:,:,kernelcout_map);
kernelcout_map=kernelcout_map+1;
end
end
end
figure
imshow(uint8(weight_map))
str1=strcat('weight num:',num2str(kernelcout_map-1));
title(str1)
end 呼叫方法
layer_num=1;%想看哪一個卷積核對應的權重☆☆☆☆☆☆☆☆☆☆
channels_num=1;%想看第幾個通道對應的卷積核
weight_partvisual( net,layer_num ,channels_num ) 看看效果:
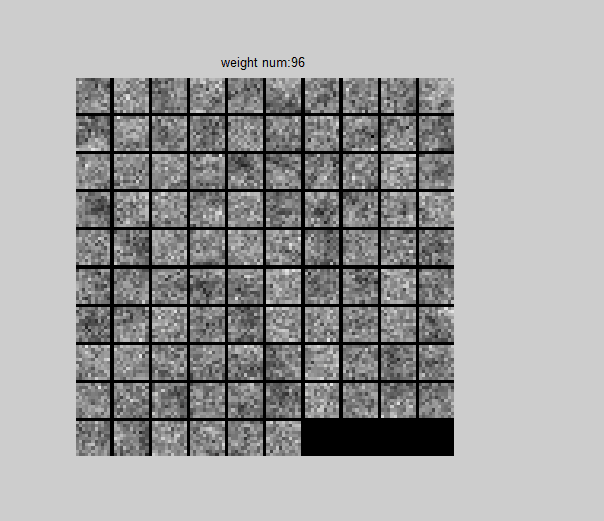

5.3、全部視覺化
將指定卷積層對應的每一個特徵圖的全部卷積核畫出
function [ ] = weight_fullvisual( net,layer_num )
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')
convlayer=[convlayer;layers{i}];
end
end
weight=net.layers(convlayer(layer_num,:)).params(1).get_data();%四維,核長*核寬*核左邊輸入*核右邊輸出(核個數)
b=net.layers(convlayer(layer_num,:)).params(2).get_data();
weight=weight-min(min(min(min(weight))));
weight=weight/max(max(max(max(weight))))*255;
[kernel_r,kernel_c,input_num,kernel_num]=size(weight);
map_row=input_num;%行數
map_col=kernel_num;%列數
weight_map=zeros(kernel_r*map_row,kernel_c*map_col);
for i=0:map_row-1
for j=0:map_col-1
weight_map(i*kernel_r+1+i:(i+1)*kernel_r+i,j*kernel_c+1+j:(j+1)*kernel_c+j)=weight(:,:,i+1,j+1);
end
end
figure
imshow(uint8(weight_map))
str1=strcat('weight num:',num2str(map_row*map_col));
title(str1)
end 
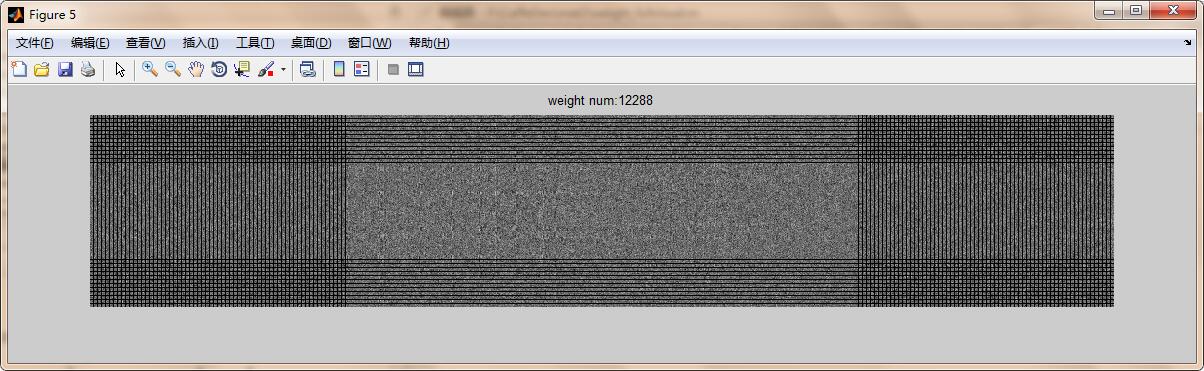
全連線討論
①首先提取出pool5的特徵圖大小
>>A=net.blobs('pool5').get_data();
>>size(A)
ans =
3 3 256 10可以發現對於每一個輸入圖片(總共十張)都有256個3*3大小的特徵圖。預先計算一下256*3*3=2304
②然後提取出fc6的特徵圖大小
>>C=net.blobs('fc6').get_data();
>>size(C)
ans =
4096 10然後發現pool5到fc6的連線並不是簡單的拉成一維向量,而是利用了一個2304*4096的權重去將pool5的特徵對映到fc6的單元中
③驗證一下是否如所想的對映方法, 只需要看看pool5到fc6的權重大小即可
>>D=net.layers('fc6').params(1).get_data();
>> size(D)
ans =
2304 4096發現果真如此,所以池化層到全連線層的確是用了一次對映而非簡單的拉成向量
嗯啊,初步成功~~