
騰訊2017社交廣告比賽(廣告轉化率預測)總結與分享--by Coda_Allegro
2017騰訊廣告比賽結束也有一段時間了,決賽得了23名,無比殘念(前20名有獎 )
)
一直沒時間總結一下比賽的得失。乘著懶癌沒到晚期,趕緊寫了。
順便求一波github的星星。(可恥)
---------------------------------------------
1.問題&思路分析
騰訊本次競賽的題目為移動App廣告轉化率預估(pCVR,Predicted Conversion Rate)。以移動App廣告為研究物件,預測App廣告點選後被啟用的概率:pCVR=P(conversion=1 | Ad,User,Context),即給定廣告、使用者和上下文情況下廣告被點選後發生啟用的概率。
那麼從本質上看,這就是一個二分類問題(你的點選有沒有轉化,即true/false)。只不過由於轉化這件事情機率實在是太過於低,比賽要求你給出的是轉化的概率,但這其實很好辦,很多的分類器在最後預測資料類別時其實就是用概率最大進行選擇的。典型的代表就是各種神經網路分類器,最後總是會接個Softmax的全連線層,通過輸出層概率取最大來進行預測。
那麼簡而言之,這就是個非常傳統的機器學習任務了。我們可以把這個任務切割成如下的子任務
1.提取資料特徵
2.選取合適的模型,訓練模型
3.調參與特徵篩選
4.融合
--------------------------
2.特徵提取
其實打了這個比賽後,很多人都會有這麼個感受。這其實就是半個特徵選擇大賽嘛。大佬挖掘出強特,trick。之後就可以吊打後面那些死肛統計特徵什麼的玩家了。
1.充分理解業務
2.開腦洞 -_-!!!!
這個我使用的特徵其實非常少,由於我是用一臺筆記本肛完整個比賽了。決賽資料量又爆炸。我只提取了50多維特徵。大致為一以下幾個種類。
I.基礎特徵:顧名思義,就是基礎給你的那個屬性,比如廣告位ID,使用者ID,使用者性別,年齡之類的。這些屬性其實一定程度上就能夠指導轉化率的預測了(即讓分類器學習這些屬性對於是否轉化的分佈)。當然,這種特徵練出來的只不過是baseline級別的玩意。初賽提交佔板凳用的。
II.使用者的統計特徵:這是重中之重,轉化與否都是看使用者的意願的,而提取使用者相關的特徵自然是非常重要的。這裡我給出我提取的一些有效的特徵:
1.基本統計:類似於使用者的安裝數量,點選數量。使用者安裝同類別APP的數量等等。
2.時序統計:使用者點選廣告之前的一些行為都這次點選是否轉化是具有很強的指導意義的。統計點選時間(clicktime)之前的一些特徵能夠很好的提高預測效果。例如統計clicktime之前的使用者點選量,app安裝數量之類的種種。
III.trick:喜聞樂見的環節,由於網速之類的問題,使用者可能在很短的時間類不斷的點選一個同一個廣告,利用這裡連續的記錄是很有效的。具體使用方法舉個例子,對短時間類重複的點選記錄編號(1,2,3....),記錄當前點選與前一次點選,後一次點選的時間差,亦或者同統段時間內使用者的點選量(如1分鐘內)。
*這兒必須要提一點,那就是資料洩露問題,簡而言之,就是你用了未來的資料預測當前的轉化率,或者直接用了和label相關性很強的特徵來訓練模型。後者危險性極大,直接造成線下結果超神,線上GG.很好理解,你等於用了答案在做題目-_-||||。但是前者就有意思了,理論上,實際業務你是無法提取這種特徵的,但是,這是比賽,你懂得。使用者是否重複點選,與後一條記錄的時間差,這都是未卜先知的操作,而且這些洩露特徵也是有風險的。具體自行操作感受。
IV.平滑後的轉化率:你可能會想:我要預測轉化率,那我用以前的轉化率當特徵不就OK了,你對了。但是,不全對。舉個例子,統計同一廣告位APP的歷史轉化率。由於廣告位上線有前後,上線慢的統計不充分,最後特徵基本就沒用了。使用者歷史轉化率就更危險了。大多數使用者只點擊過APP一次,歷史轉化率就是100%,你拿這個訓練其實就是用了label來訓練模型(就是前面我說的資料洩露的後者)。那種腫麼辦?
用先驗知識來給轉化率設定一個初值啊。
總結一下,就是
假設一,所有的廣告有一個自身的轉化率,這些轉化率服從一個Beta分佈。
假設二,對於某一廣告,給定轉化次數時和它自身的轉化率,它的點選次數服從一個伯努利分佈
然後用梯度下降來學習這個分佈。
-----------------------------
3.訓練集構造&分類器選擇
有了特徵,然後就是分類器的選取和訓練資料集的構造問題了。決賽資料大概有10G左右,小破本根本就玩不了。
資料是按時間劃分的(17-30天為訓練集,31天為預測集)。我們其實只需要選取28,29就足夠了。為何不選30,是因為30天資料統計有誤差(官方說法,為了題目更真實)但是我用了第30天的資料並且得到了提高。第30天其實是非常重要的一天,因為廣告具有很強的實效性,第30天是和第31天隔得最近的。它最能捕獲31天的趨勢,儘管不精確,但是30天究竟能不能用這和你的特徵有關。我個人測試的結果(不保證正確):如果大量使用統計特徵,請不要用第30天來訓練。
線下測試cross validation就夠了,但是有人會轉牛角尖,用cv,會造成使用未來的資料預測以前的資料啊。對此我想說--你trick都用了,還怕這個?。這還是和特徵有關,至少我和一些同學用CV能保證大體線上線下同步。當然,你也可以用27,28,來訓練,29來驗證。這個保險,初賽我用了這個,但是決賽資料太大,我沒用測試。
然後就是分類器了。這個又很多選擇,例如LR,RF,XGBOOST,LightGBM等等,由於不可能一個個介紹。我就說的用的吧,那就是XGBOOST和LightGBM。(初賽還用了LR,決賽沒有空,就沒訓練LR了)
--------------------------
4.模型融合
這個是最後決勝負關鍵點之一!!!(當然,我就是跪在這裡了,頭天還是16.最後一天融合被人擠到23名)。何為融合,就是把一堆分類器揉到一起嘛 。當然,這是有套路的。我這裡只介紹2種,也是我用的2種。
。當然,這是有套路的。我這裡只介紹2種,也是我用的2種。
1.加權平均:很好理解,講多個分類器的預測結果做個加權平均。看似簡單無腦,其實很有效果。但是權重不好確定,可以使用線下CV確定權重,或者線上猜權重(土豪玩法,一天就3次提交機會)但是使用加權平均保證,你用的幾個分類器線上結果不能差的太懸殊。(就是不要加入沒用的分類器)
*一個大佬告訴我的騷操作(我沒試過):給分類器設一堆隨機種子,然後訓練出一堆結果加權。。。。。。。
2.stacking:一句話解釋就是:用其他分類器預測的結果作為當前分類器的特徵。
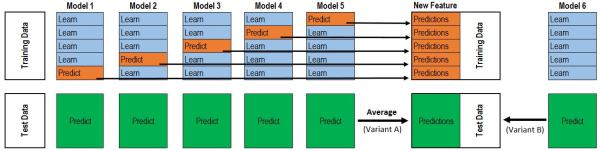
這是一張網上的圖,和我的表達可能不太符合。只看上面那半就好(下面那半的average不是我想表達的,人懶,不想畫新圖了)。
大致說下步驟:
(1)講訓練集切成n分(這兒我取5)。
(2)用1,2,3,4份訓練分類器來預測第5份的概率,用1,2,3,5訓練分類器預測第4份的概率.....(以此類推)。然後用1-5份訓練分類器預測測試集的概率
(3)講這些概率作為另一個分類器模型的特徵(在現有的特徵上面加一列概率特徵)來訓練第二層模型
這個方法要點是:用於stacking的模型儘量要差異性大,我用的xgboost和lightGBM融合效果其實不行,原因就是兩者都是樹形分類器,沒太大差別。
stacking的訓練代價很大。破機器也很難玩好。融合這一步做的好,最後一天是可以翻身的(初賽我的stacking效果很好,決賽不知道為何就GG了)。
另外,如果你發現了兩組強特,他們相關性很強,可以嘗試用他們分別訓練模型然後融合,可以得到不錯的效果。(理論上)
最後我的融合方案是:
用xgboost來stacking訓練lightGBM(Model1)
用lightGBM來stacking訓練xgboost(Model2)
訓練單模型lightGBM(Model3)
結果加權:0.25*Model1+0.25*Model3+0.5*Model2
以上就是我這次比賽全過程的細節了,基本是毫無保留了(原始碼都給你了),要是有也是人懶不想碼的無關緊要的玩意。