
大資料分析技術研究報告(三-3)
作者:朱賽凡
3) 儲存層
資料儲存層主要包括以下幾類:
一類是基於MPP資料庫叢集,這類系統特點是儲存層與上層並型計算引擎是緊耦合,屬於封閉性的系統。
二是採用分散式檔案系統,例如SharK、Stinger、HIVE、Impala、Scope等。Shark、Stinger、Hive、Imapla都採用HDFS檔案系統作為儲存層,Scope採用微軟自己開發的分散式檔案系統。此類系統特點是儲存層與上層計算引擎層之間是鬆耦合關係。
三是儲存層基於單機版本關係資料庫,例如CitusDB採用PostSQL資料庫系統、shardquery採用Mysql資料庫系統。此類系統類似於一箇中間件,也可以認為上層和底層儲存層屬於鬆耦合關係。
四是可以支援各種異構的儲存系統,例如Presto、Tenzing。Presto設計即支援HDFS也支援儲存在Mysql中的資料,但是目前只支援HDFS;Tenzing底層支援:Google File System、MySQL、Bigtable。
不同儲存系統對上層計算有一些影響,典型如Tenzing系統會利用底層儲存系統的一些特性:
(1)例如如果低層是mysql資料庫,則可以直接利用mysql索引來過濾
(2)如果底層是bigtable資料庫,則可以直接利用bigtable 範圍scan來過濾
(3)如果底層是列儲存系統,則可以只掃描需要掃描的列。
(4)如果底層是列儲存系統,且標頭檔案裡面有該列最大值和最小值,則可以利用該資訊直接跳過某些檔案的掃描。
另外需要指出的是,目前已上所有系統都有一個趨勢就是採用列式儲存。例如HIVE開發了行列混合的RCFILE檔案格式(先按行劃分,保證每行的資料不會垮機器儲存,然後再按劣儲存),shark系統開發了記憶體中的列式儲存格式,citusDB開發了專用postSQL資料庫的列式儲存引擎。
3 Druid等專用系統簡單介紹
1) JethroData系統
JethroData的特點是hadoop+index。該系統對儲存在HDFS上的結構化資料建立索引,並把索引檔案也以普通檔案方式儲存在HDFS系統,並在查詢處理時採取以下過程:
(1) 查詢主節點負責分析SQL語句後,針對sql中的where條件部分,利用索引檔案來得到符合where過濾條件後的rowid集合。
(2) 該rowid集合涉及各datanode節點,採用併發方式來讀取資料。
(3) 所有資料彙總到查詢主節點,進行彙總與計算,並將最終結果返回給客戶端。
可以看出,由於該系統設計思路是希望通過索引來加速資料選擇,因此只適合每次查詢處理只涉及少量一部分資料。
2) Druid系統
本系統是美國metamarket公司開發的面向海量資料的實時統計分析系統,以實現針對上億級別海量資料統計分析的延遲在1秒以內。該系統於2012年10月開源。該系統可以認為是一個分散式的記憶體OLAP系統。
該系統主要分析的資料為交易記錄,每條交易記錄包括三個部分:交易發生的時間點、多個維度屬性、多個數值型度量屬性。例如:

該系統設計用來可以回答以下問題“有多少個針對Justin Bieber的編輯來自San Francisco? ”、“一個月內來自Calgary的增加編輯字數的平均數是多少?”。而且要求:能夠在高併發環境下,在1秒以內完成任意維度組合的統計,且保證系統高可用;還系統還要能夠具備實時資料分析能力,也就是能夠查詢分析到最新的資料,延時時間為秒級。
為了達到上述目標,該公司先後通過測試發現關係資料庫技術和NOSQL資料庫都無法滿足其需求。關係型資料庫由於磁碟io瓶頸導致效能無法滿足需求,而NOSQL資料庫雖然可以採用預計算方法來達到高效能,但是預計算無法滿足分析需求靈活多變。
為解決該問題,該公司自己開發DRUID系統,主要技術思路如下:
(1)將原始資料(alpha資料)進行一定粒度合併,合併成beta資料。
(2)將beta資料全部放入記憶體,並通過分散式記憶體方式解決單臺伺服器記憶體
上限問題。
(3) 針對緯度屬性建立索引,以加速資料的選取。
(4) 採用分散式方式進行並行統計,為了保證分散式統計高效,該系統不支援join,而且對聚合計算不支援中位數等無法分佈計算的聚合計算函式。
(5) 利用資料複製解決系統高可靠性問題。
4 本章總結
1) MPP並行資料庫得益於流水線的執行以及基於統計優化等方面,使得MPP並行資料庫的執行效率是最高的。但缺點包括:
n 資料匯入時間長,匯入時要做各種預處理,例如一些統計資訊;
n 執行引擎和儲存緊耦合導致資料難以被其他分析引擎進行分析;
n 基於樹型結構執行計劃,導致MPP並行資料庫表達能力有限,更適合做統計與查詢,而不適合資料分析處理;
n 容錯性差,特別是一個任務涉及資料量越大,該缺陷越明顯。
2)HIVE、Tenzing、Shark、SCOPE、Stinger等系統可以認為基本屬於同一類系統。這類系統共同特點是:”通用平行計算引擎框架+SQL解析層”。並且可以將HIVE、Tenzing看成是基於第一代系統,而Shark、Scope、Stinger是第二代系統。這一類系統特點如下:
n 儲存層、執行引擎層、SQL解析層三者分離,可以方便替換執行引擎,對使用者而言,同一份資料可以採用不同並行執行引擎來分析。
n 在執行效率方面,由於儲存和上層分離因此一半隻能具備邏輯優化能力,另外由於Tree結構執行計劃更容易採用流水線執行方式,因此這類系統執行效率總體來講不如MPP關係資料庫,它們之間排序是MPP資料庫 > 第二代系統 > 第一代系統。
n 在執行效率方面,另外一點是這類系統一般內建對索引的支援不是太好或者不支援。
n 在大規模計算容錯方面,這類系統要優於MPP關係資料庫。
3)Impala、Dremel等可以認為屬於同一類系統,此類系統介於前兩者系統之間。這類系統特點是:
n 和MPP資料庫類似,基於Tree結構執行計劃,專注於查詢統計,因此效率高於第二類系統,但是可能和第二類系統的第二代相當。
n 與MPP資料庫不同的是這類系統只是一個引擎,與儲存系統鬆耦合。也就是SQL解析層與執行層緊偶合,然後和儲存層鬆藕合。
n 只適合做中間結果越來越小查詢分析,中間結果都放記憶體,對記憶體要求較高,例如無法實現大表之間的join。
因此,在大型網際網路企業中,資料量太大,就會出現所謂“高價值、低密度”情況,反映到資料處理上,網際網路企業不會長期儲存原始資料,而是會把原始資料先經過一部分預處理,經過部分提煉後,把提煉後資料進行長期儲存和分析。也就是如下流程:
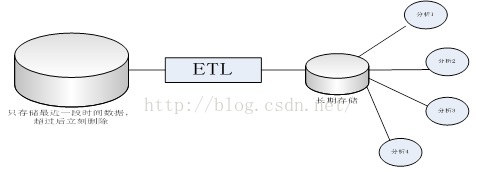
例如淘寶,把每天資料直接寫入Hadoop平臺,然後通過每天執行相對固定mapreduce作業來做ETL,然後在計算結果基礎上為提供各種分析功能。其中海量原始資料經過固定ETL後被刪除,由於只使用一次,因此沒有必要花很大精力把這些資料整理成適合分析與挖掘格式。例如在這種場景下,索引也沒有太大的價值,因此沒有必要花費大量代價來建立索引。
MPP並行資料庫,適合儲存高密度價值資料,並且是長期儲存和多次使用,所以MPP並行資料庫會花大量經歷在Load階段,把資料處理成適合分析格式 。
通過上述系統地介紹與比較,我們可以得出一個這樣結論:在大資料領域,沒有一個通用的解決方案,而需要根據具體業務場景,選擇合適的技術!
4)通過上述系統研究,我們可以發現一點就是Join操作,特別是大表之間join操作是最消耗資源,也是最優化難度較高的操作,特別是在並行join的實現難度較大。例如Druid和Dremel等都基本放棄了join操作。
因此個人認為應該從業務上和從資料預處理方面,通過適當資料冗餘來儘量避免在分析過程過程中執行join操作。