
Hive中資料壓縮(企業優化)

二 、配置mapreduce和hive中使用snappy壓縮
將snappy解壓,將Lib下的native複製到hadoop下的lib
1、 實際就是對mapreduce過程中資料進行壓縮
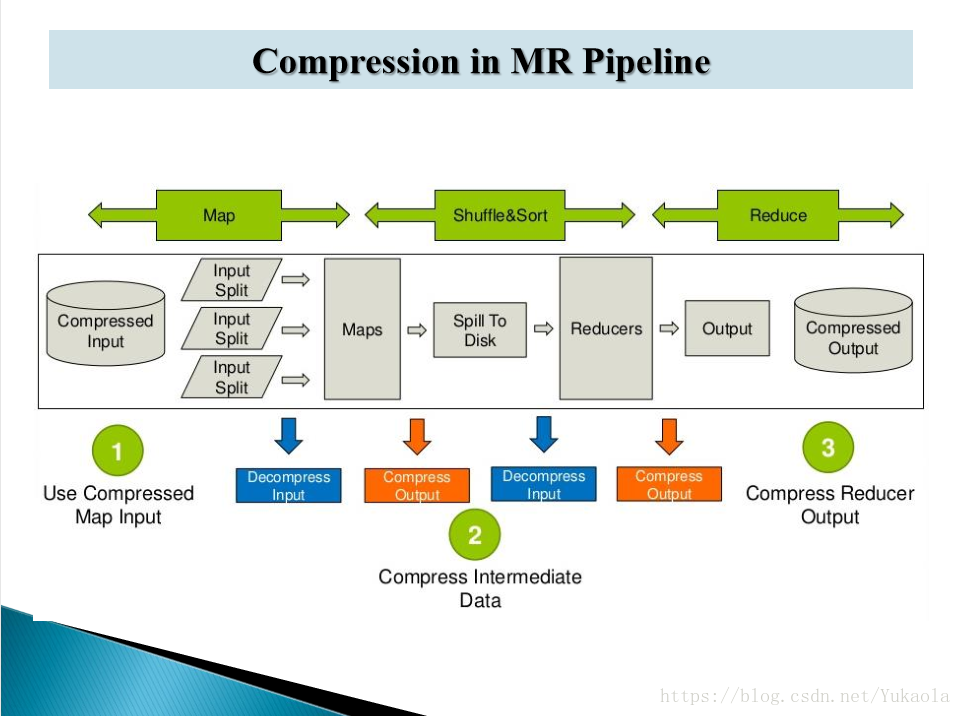
2、hadoop支援的壓縮格式

3、在mapreduce中設定壓縮

4、在hive中設定壓縮

5、資料檔案格式

資料儲存
* 按行儲存資料:TEXTFILE
* 按列儲存資料: RCFILE ORC(儲存列數較多的表) PARQUET(常用)
6、幾種儲存格式壓縮比較

6.1、建立Text表
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
載入資料到表中 load data local inpath '/home/beifeng/opt/datas/page_views.data' into table page_views ;
6.2、建立ORC表
create table page_views_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc ;
載入資料到orc表 insert into table page_views_orc select * from page_views ;
6.3、建立parquet表
create table page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET ;
載入資料到parquet表 insert into table page_views_parquet select * from page_views ;
檢視三種儲存格式的表的大小 dfs -du -h /user/hive/warehouse/page_views/ ; 相同資料量orc格式佔記憶體最小
在實際專案開發中資料儲存格式一般用orcfile格式和qarquet格式
資料壓縮格式一般用snappy格式
7、建立一張orc儲存格式表,並用snappy壓縮。預設的壓縮格式為zlib
create table page_views_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
8、Hive企業使用優化
8.1、使用 Limit 、where 、*、不走mapreduce
8.2、大表拆分-建立子表:建立表時使用As select
8.3、外部表和分割槽表結合使用
CREATE EXTERNAL TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[ROW FORMAT row_format]
8.4、資料:儲存格式和資料壓縮,在6中已講
8.5、將8.2、8.3、8.4結合起來建立一張表,該表為一張表的子表,用snappy壓縮,表格式為parquet
set parquet.compression=SNAPPY ;
create table page_views_par_snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS parquet
AS select * from page_views ;
8.6、hive高階優化——join優化Join優化官網 面試常問
資料傾斜
Common/Shuffle/Reduce Join
連線發生的階段,發生在 Reduce Task
大表對大表
每個表的資料都是從檔案中讀取的

Map Join
連線發生的階段,發生在 Map Task
小表對大表
* 大表的資料放從檔案中讀取 cid
* 小表的資料記憶體中 id
DistributedCache
SMB Join
Sort-Merge-BUCKET Join 桶的概念

設定啟用自動優化

9、執行計劃
EXPLAIN select * from emp ; 檢視一個語句的執行資訊
EXPLAIN select deptno,avg(sal) avg_sal from emp group by deptno ;
EXPLAIN EXTENDED select deptno,avg(sal) avg_sal from emp group by deptno ; 檢視一個語句的詳細執行資訊
10、Hive高階優化
對屬性進行設定
並行執行:設定job可以並行執行的個數。改為true
JVM重用:預設每個mapreduce任務都會開啟新的JVM來執行程式,開啟JVM需要時間,可設定每個 JVM執行多個任務
Reduce數目:map個數預設是根據塊大小分配。自己手動除錯Reduce個數,直到每個Reduce任務完成的時間都在一個時間範圍之內。適用每天都需要測的大量資料
推測執行:屬於mapreduce的優化,當在一定標準內mapreduce任務沒有完成,自動開啟新的任務進行執行。在使用hive時應該都設定為false

建立分割槽表時一般為手動
* bf_log_ip
load data path '' into table bf_log_ip partition(month='2015-09',day='20') ;
瞭解以下自動進行分割槽


作者:Yukaola
來源:CSDN
原文:https://blog.csdn.net/Yukaola/article/details/79763006
版權宣告:本文為博主原創文章,轉載請附上博文連結!