
分散式多爬蟲系統——架構設計
阿新 • • 發佈:2019-01-04
前言:
在爬蟲的開發過程中,有些業務場景需要同時抓取幾百個甚至上千個網站,此時就需要一個支援多爬蟲的框架。在設計時應該要注意以下幾點:
- 程式碼複用,功能模組化。如果針對每個網站都寫一個完整的爬蟲,那其中必定包含了許多重複的工作,不僅開發效率不高,而且到後期整個爬蟲專案會變得臃腫、難以管理。
- 易擴充套件。多爬蟲框架,這最直觀的需求就是方便擴充套件,新增一個待爬的目標網站,我只需要寫少量 必要的內容(如抓取規則、解析規則、入庫規則),這樣最快 最好。
- 健壯性、可維護性。這麼多網站同時抓取,報錯的概率更大,例如斷網、中途被防爬、爬到“髒資料”等等。所以必須要做好日誌監控,能實時監控爬蟲系統的狀態,能準確、詳細地定位報錯資訊;另外要做好各種異常處理,如果你放假回來發現爬蟲因為一個小問題已經掛掉了,那你會因為浪費了幾天時間而可惜的(雖然事實上我個人會不時地遠端檢視爬蟲狀態)。
- 分散式。多網站抓取,資料量一般也比較大,可分散式擴充套件,這也是必需的功能了。分散式,需要注意做好訊息佇列,做好多結點統一去重。
- 爬蟲優化。這就是大話題了,但最基本的,框架應該要基於非同步,或者使用協程+多程序。
- 架構簡明,要方便以後未知功能模組的新增。
需求如上,說的已經很清楚了。下面介紹一種架構設計,是去年做的了,現在分享一下。具體的程式碼實現就暫不公開了。
正文:
以下將通過解釋兩張圖來說明架構的設計思想。
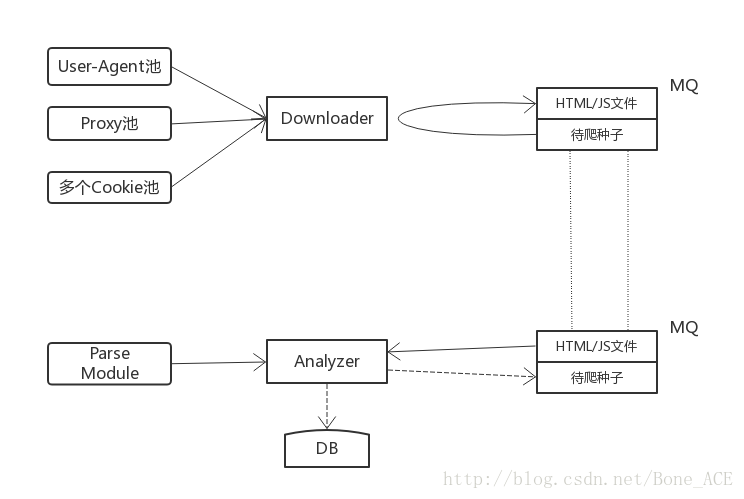
- 框架主要分成兩部分:下載器Downloader和解析器Analyzer。Downloader負責抓取網頁,Analyzer負責解析網頁併入庫。兩者之間依靠訊息佇列MQ進行通訊,兩者可以分佈在不同機器,也可分佈在同一臺機器。兩者的數量也是靈活可變的,例如可能有五臺機在做下載、兩臺機在做解析,這都是可以根據爬蟲系統的狀態及時調整的。
- 從上圖可以看到MQ有兩個管道:
HTML/JS檔案和待爬種子。Downloader從待爬種子裡拿到一條種子,根據種子資訊呼叫相應的抓取模組進行網頁抓取,然後存入HTML/JS檔案這個通道;Analyzer從HTML/JS檔案裡拿到一條網頁內容,根據裡面的資訊呼叫相應的解析模組進行解析,將目標欄位入庫,需要的話還會解析出新的待爬種子加入MQ。 - 可以看到Downloader是包含User-Agent池、Proxy池、Cookie池的,可以適應複雜網站的抓取。
- 模組的呼叫使用工廠模式。
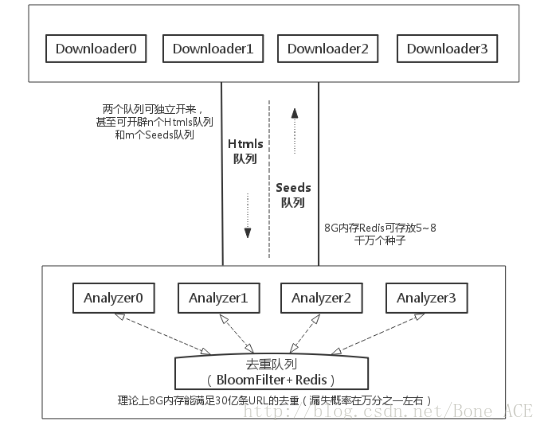
- 這張圖是上張圖的另一種表述。
- Htmls佇列和Seed是佇列可以獨立分開,甚至數量也可以多開,之間沒有聯絡。完全可以靈活地根據爬蟲狀態和硬體環境作調整。另外8G的內容可以讓Redis作為Seeds佇列存放5~8千萬個種子。
- 分散式爬蟲非常關鍵的一點:去重。可以看到多個解析器Analyzer共用一個去重佇列,才能夠保證資料的統一不重複。去重佇列可以放在一臺機上。基於Redis實現了Bloomfilter演算法(詳細見《基於Redis的Bloomfilter去重(附Python程式碼)》),理論上8G的記憶體可以滿足30億條URL的去重,如果允許漏失概率再大點的話能去重更多。
結語:
要寫一個支援分散式、多爬蟲的框架,具體的實現上還是有一定難度的。在實現主要功能以外,還要注意做到程式碼嚴謹 規範,爬蟲高效 健壯的要求。做完這些以後,你定會成長不少!
今天就分享這些,歡迎交流!