
TensorFlow學習筆記(二)之視覺化(Tensorboard)
一、Tensorboard簡介
Tensorboard是TensorFlow自帶的一個強大的視覺化工具,也是一個web應用程式套件。通過將tensorflow程式輸出的日誌檔案的資訊視覺化使得tensorflow程式的理解、除錯和優化更加簡單高效。支援其七種視覺化:
- SCALARS:展示訓練過程中的準確率、損失值、權重/偏置的變化情況
- IMAGES:展示訓練過程中及記錄的影象
- AUDIO:展示訓練過程中記錄的音訊
- GRAPHS:展示模型的資料流圖,以及各個裝置上消耗的記憶體和時間
- DISTRIBUTIONS:展示訓練過程中記錄的資料的分佈圖
- HISTOGRAMS:展示訓練過程中記錄的資料的柱狀圖
- EMBEDDINGS:展示詞向量後的投影分佈
介面展示:
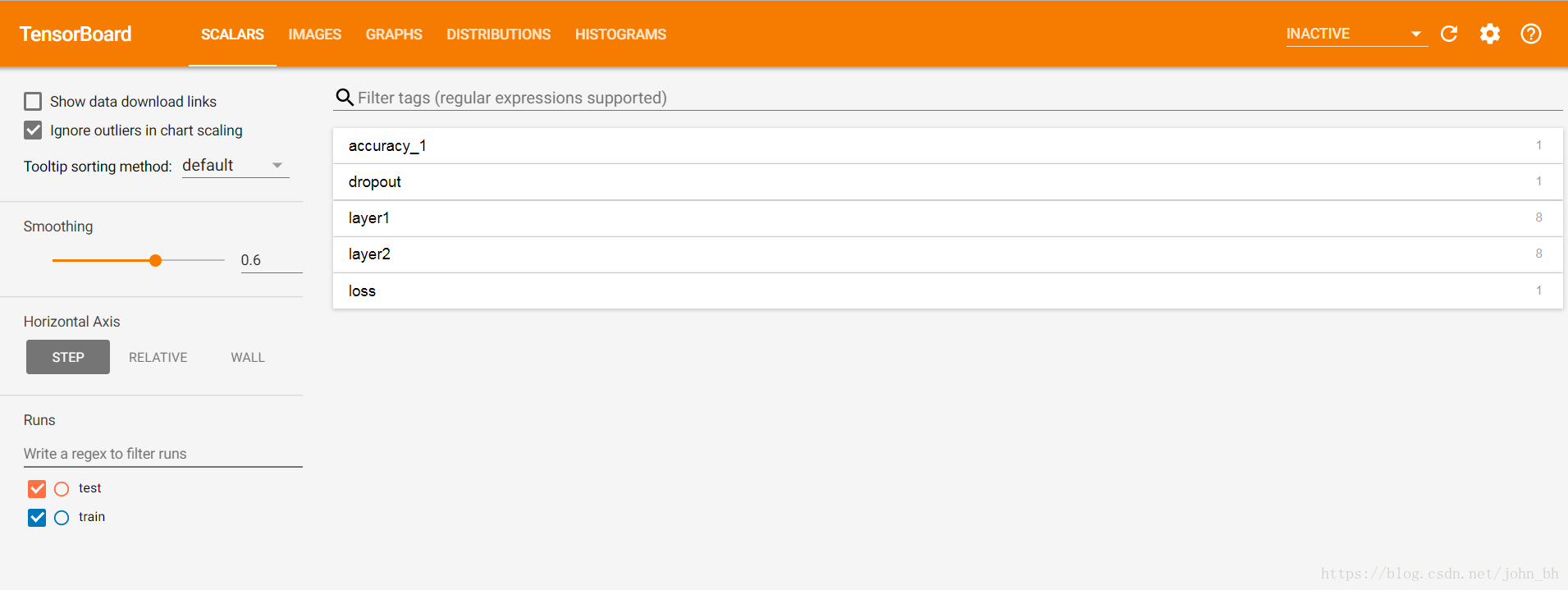
那如何啟動tensorboard呢?使用是手寫體識別的例子,原始碼如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto(allow_soft_placement=True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.33 在pycharm中執行這段程式碼,效果如下:
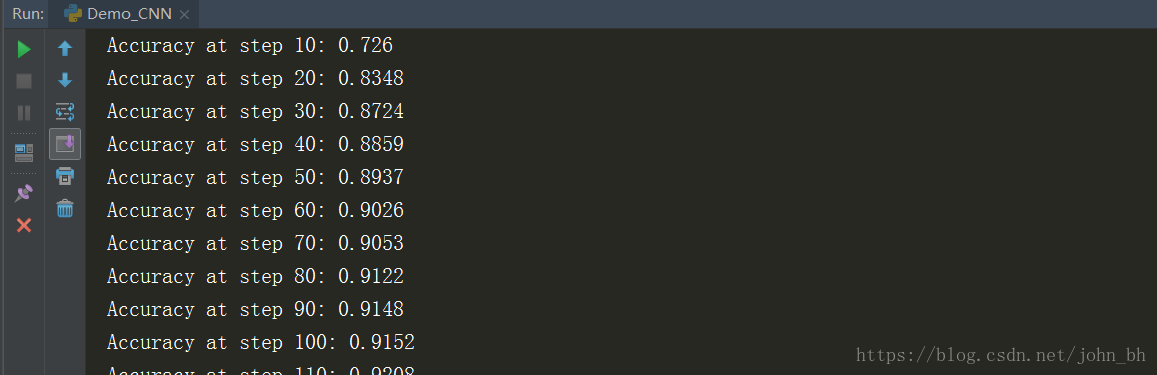
同時,在訓練的時候開啟命令列,輸入下面命令,啟動TesnorBoard:
tensorboard --logdir=./MNIST_LOG/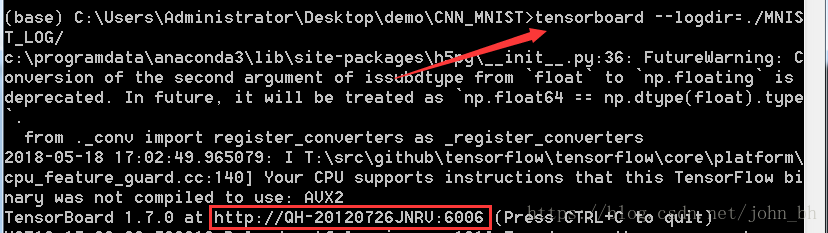
這裡生成一個連結地址,複製到遊覽器中檢視各個模組的內容。
總的來說步驟如下:
- 建立writer,寫日誌檔案:tf.summary.FileWriter(log_dir + ‘/train’, sess.graph)
- 儲存日誌檔案:writer.close()
- 執行視覺化命令,啟動服務:tensorboard –logdir /path/
二、SCALARS面板
SCALARS 面板,統計tensorflow中的標量(如:學習率、模型的總損失)隨著迭代輪數的變化情況。SCALARS 面板的左邊是一些選項,包括Split on undercores(用下劃線分開顯示)、Data downloadlinks(資料下載連結)、Smoothing(影象的曲線平滑程度)以及Horizontal Axis(水平軸)的表示,其中水平軸的表示分3 種(STEP 代表迭代次數,RELATIVE 代表按照訓練集和測試集的相對值,WALL 代表按照時間)。圖中右邊給出了準確率變化曲線。
如下圖二所示,SCALARS欄目顯示通過函式tf.summary.scalar()記錄的資料的變化趨勢。如下所示程式碼可新增到程式中,用於記錄學習率的變化情況。
tf.summary.scalar('accuracy', accuracy)
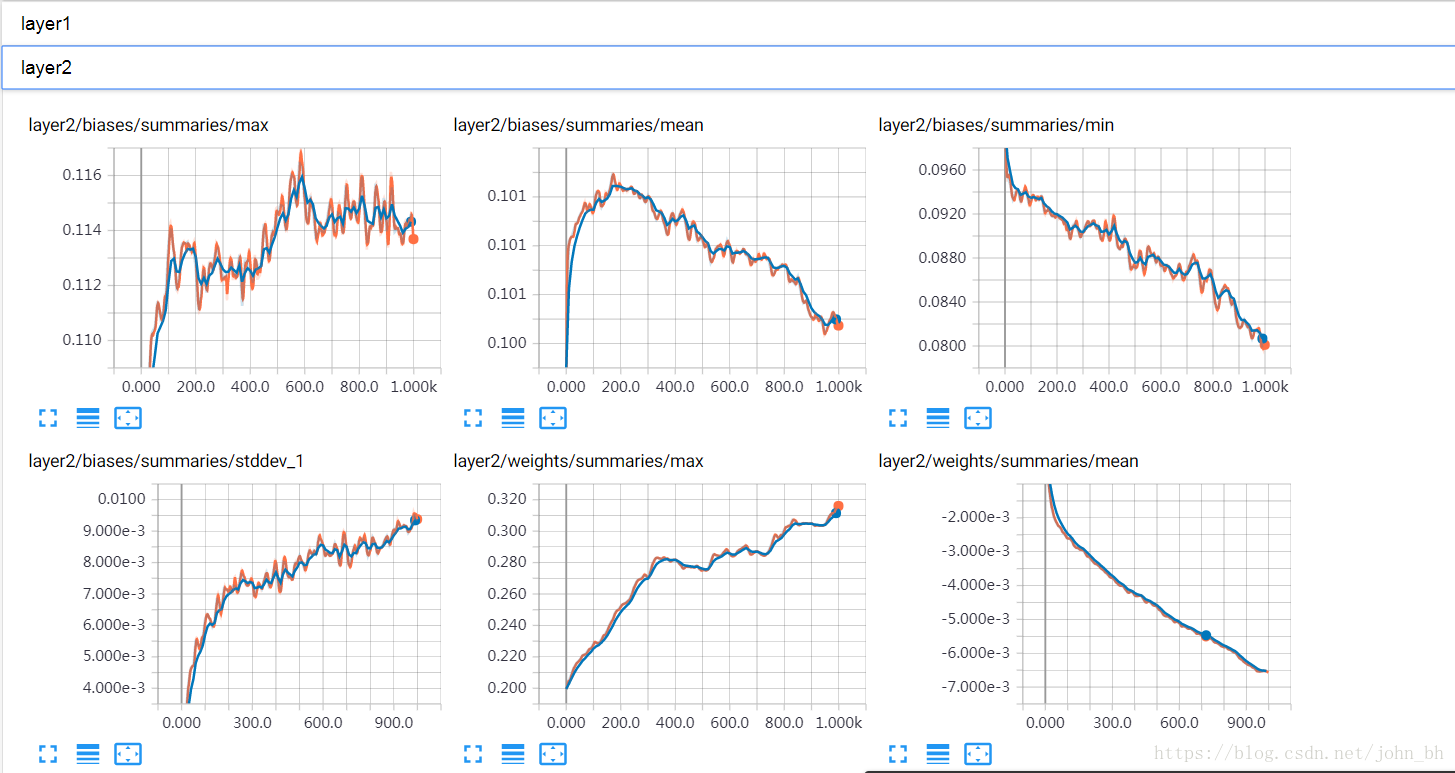
SCALARS 面板中還繪製了每一層的偏置(biases)和權重(weights)的變化曲線,包括每
次迭代中的最大值、最小值、平均值和標準差,如下圖,layer1層:
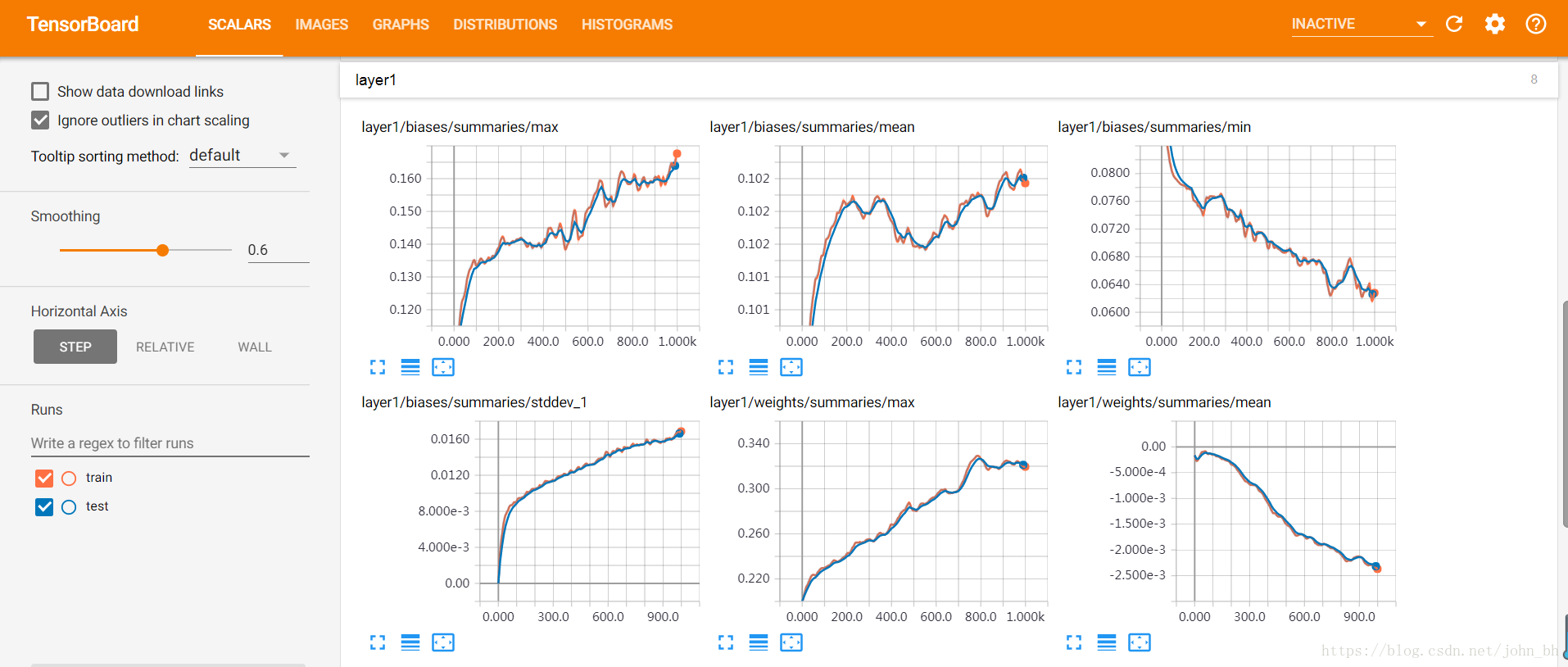
layer2層:
構建損失曲線:
tf.summary.scalar('loss', cross_entropy)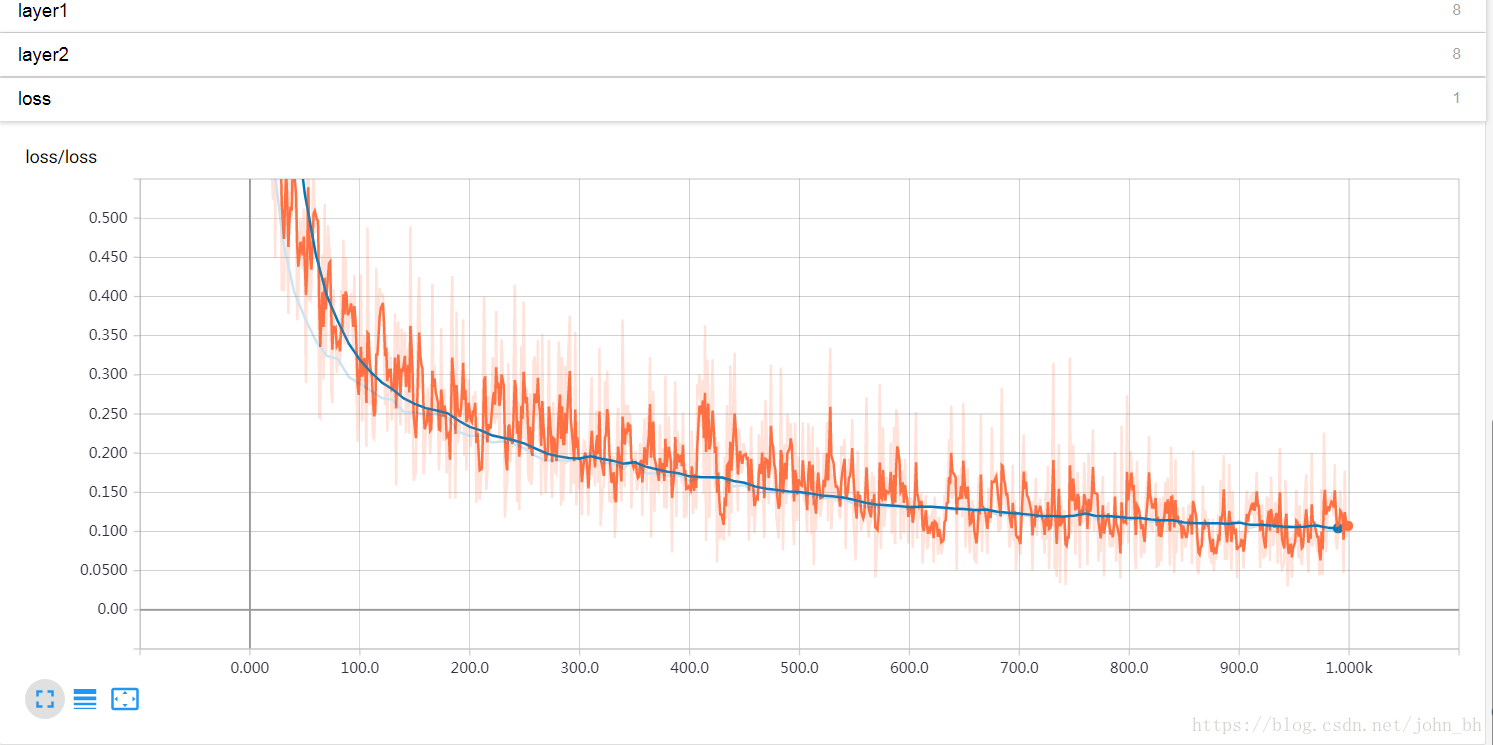
三、IMAGES面板
影象儀表盤,可以顯示通過tf.summary.image()函式來儲存的png圖片檔案。
1. # 指定圖片的資料來源為輸入資料x,展示的相對位置為[-1,28,28,1]
2. image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
3. # 將input名稱空間下的圖片放到summary中,一次展示10張
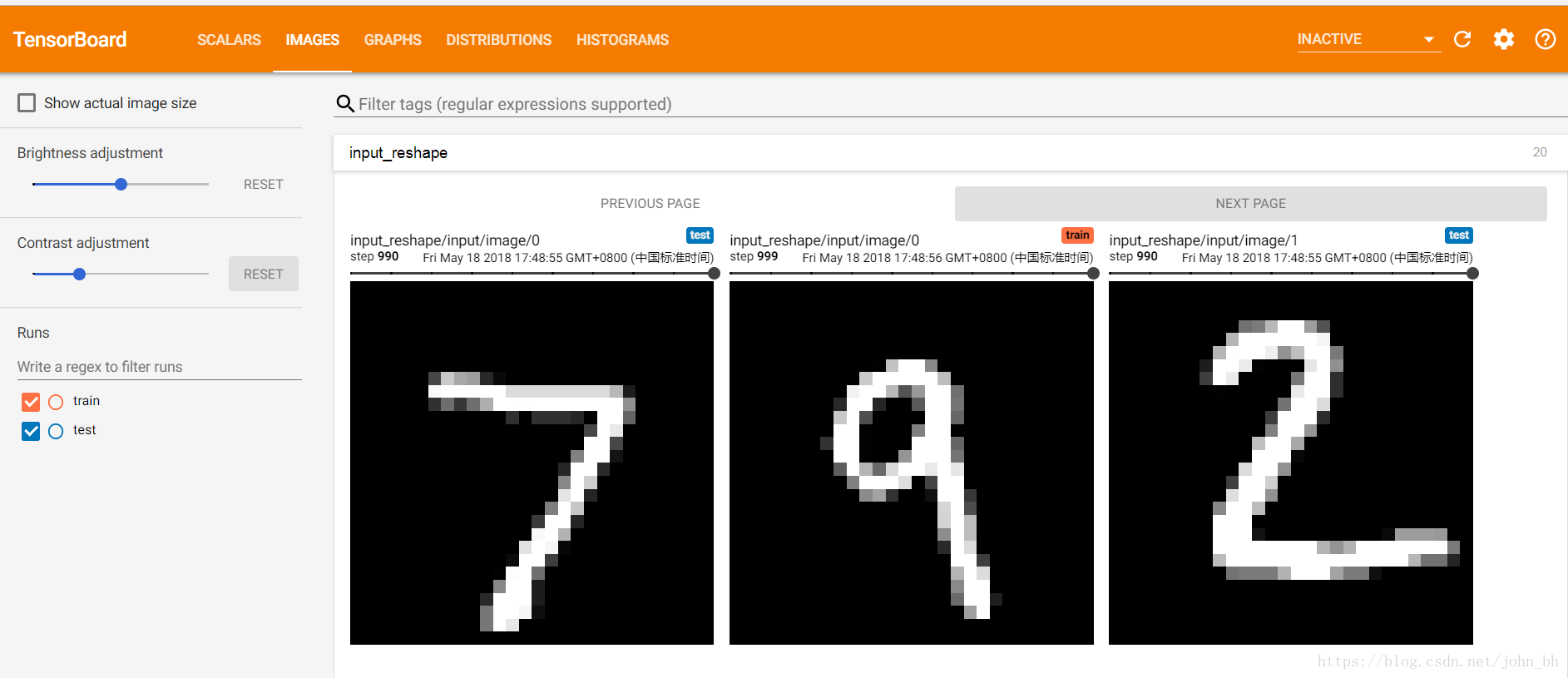
4. tf.summary.image('input', image_shaped_input , 10) 如上面程式碼,將輸入資料中的png圖片放到summary中,準備後面寫入日誌檔案。執行程式,生成日誌檔案,然後在tensorboard的IMAGES欄目下就會出現如下圖一所示的內容(實驗用的是mnist資料集)。儀表盤設定為每行對應不同的標籤,每列對應一個執行。影象儀表盤僅支援png圖片格式,可以使用它將自定義生成的視覺化影象(例如matplotlib散點圖)嵌入到tensorboard中。該儀表盤始終顯示每個標籤的最新影象。
IMAGES面板展示訓練過程中及記錄的影象,下圖展示了資料集合測試資料經過處理後圖片的樣子:
四、AUDIO
AUDIO 面板是展示訓練過程中處理的音訊資料。可嵌入音訊的小部件,用於播放通過tf.summary.audio()函式儲存的音訊。一個音訊summary要存成 的二維字元張量。其中,k為summary中記錄的音訊被剪輯的次數,每排張量是一對[encoded_audio, label],其中,encoded_audio 是在summary中指定其編碼的二進位制字串,label是一個描述音訊片段的UTF-8編碼的字串。
儀表盤設定為每行對應不同的標籤,每列對應一個執行。該儀表盤始終嵌入每個標籤的最新音訊。
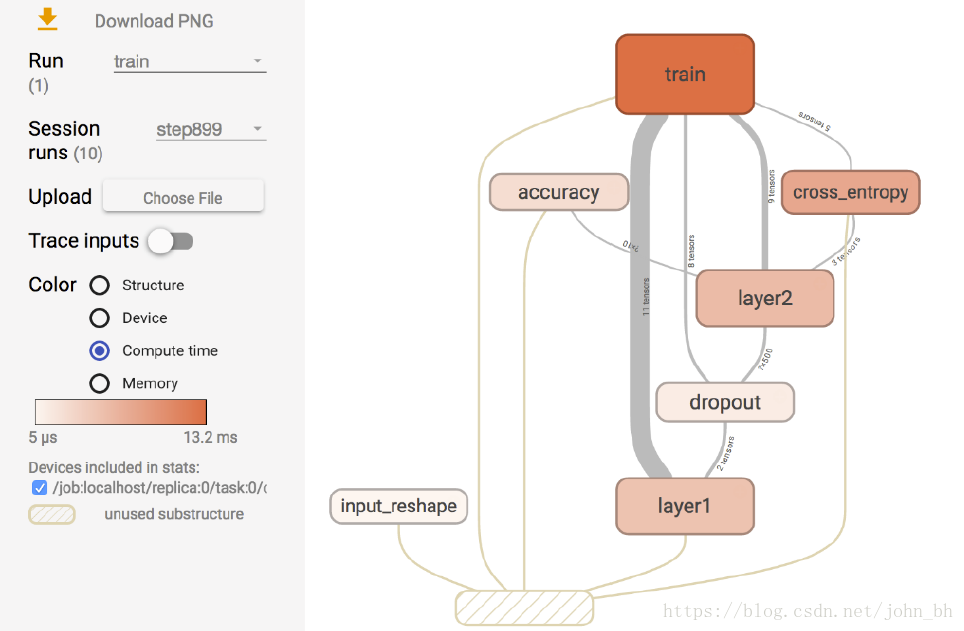
五、GRAPHS
GRAPHS 面板是對理解神經網路結構最有幫助的一個面板,它直觀地展示了資料流圖。下圖所示介面中節點之間的連線即為資料流,連線越粗,說明在兩個節點之間流動的張量(tensor)越多。
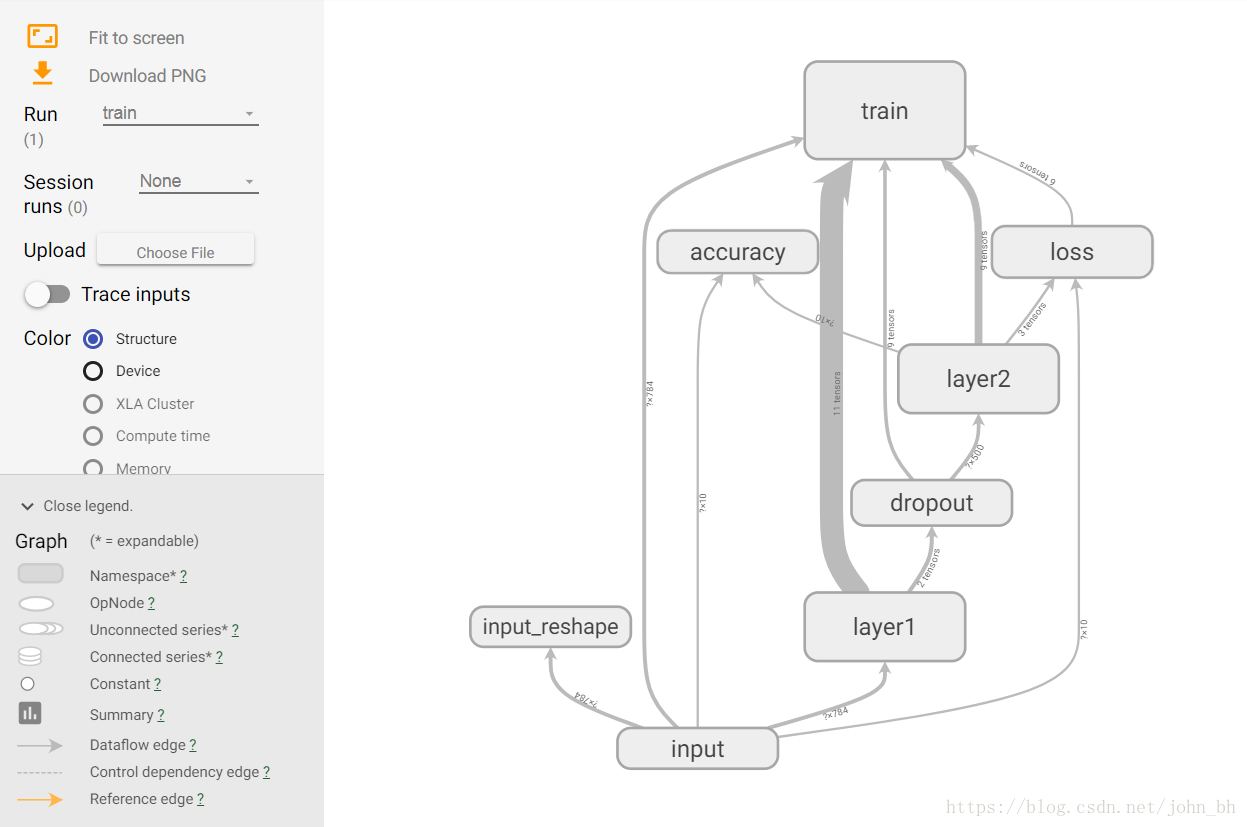
在GRAPHS 面板的左側,可以選擇迭代步驟。可以用不同Color(顏色)來表示不同的Structure(整個資料流圖的結構),或者用不同Color 來表示不同Device(裝置)。例如,當使用多個GPU 時,各個節點分別使用的GPU 不同。當我們選擇特定的某次迭代時,可以顯示出各個節點的Compute time(計算時間)以及Memory(記憶體消耗)。
六、DISTRIBUTIONS
DISTRIBUTIONS 面板和接下來要講的HISTOGRAMS 面板類似,只不過是用平面來表示來自特定層的啟用前後、權重和偏置的分佈,它顯示了一些分發的高階統計資訊。

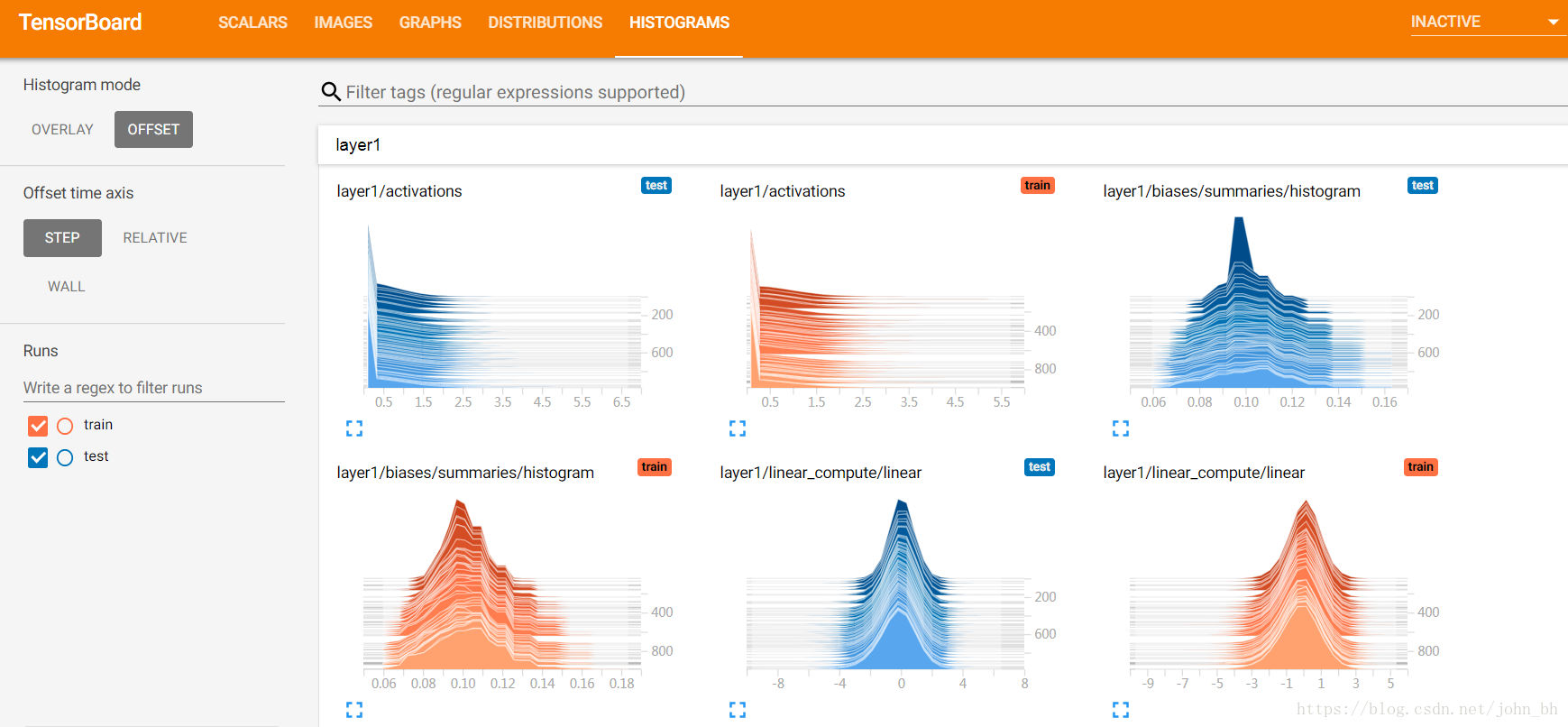
七、HISTOGRAMS
HISTOGRAMS面板,統計tensorflow中的張量隨著迭代輪數的變化情況。它用於展示通過tf.summary.histogram記錄的資料的變化趨勢。如下程式碼所示:
# 用直方圖記錄引數的分佈
tf.summary.histogram('histogram', var)
# 執行wx+b的線性計算,並且用直方圖記錄下來
tf.summary.histogram('linear', preactivate)
# 將線性輸出經過激勵函式,並將輸出也用直方圖記錄下來
tf.summary.histogram('activations', activations)
上述程式碼將神經網路中某一層的引數分佈、線性計算結果、經過激勵函式的計算結果資訊加入到日誌檔案中,執行程式生成日誌後,啟動tensorboard就可以在HISTOGRAMS欄目下看到對應的展開影象。
HISTOGRAMS 主要是立體地展現來自特定層的啟用前後、權重和偏置的分佈。
八、EMBEDDINGS
EMBEDDINGS 面板展示的是詞嵌入投影儀。(後續做詞嵌入的時候更新上…….)