
HOG+SVM行人檢測的兩種方法
關於HOG+SVM,CSDN上有一些非常好的文章,這裡給出我覺得寫的比較好的幾篇,僅供大家參考
以上就是個人覺得寫的比較好的部落格,基本上將上面的部落格看懂了,HOG也比較理解了,如果還想輸入瞭解HOG,建議直接看OpenCV HOG的原始碼
下面,就說說使用OpenCV 中的HOG+SVM實現行人檢測的兩種方式
說明:程式執行環境為VS2013+OpenCV3.0
第一種
先說第一種方式,直接上程式碼:
///////////////////////////////////HOG+SVM識別方式2///////////////////////////////////////////////////
void Train()
{
////////////////////////////////讀入訓練樣本圖片路徑和類別///////////////////////////////////////////////////
//影象路徑和類別
vector<string> imagePath;
vector<int 這裡我想說明一下TrainData.txt,這個檔案放置了所有樣本的路徑和類別,如下:
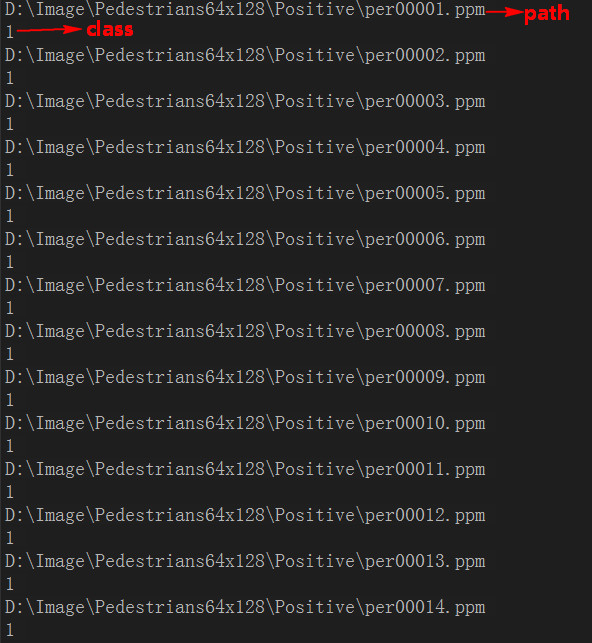
關
於如何讀取正負樣本的路徑到txt檔案,可以使用批處理檔案,批處理檔案我上傳到了CSDN,大家可以去下載
點選下載
正負樣本至少保證有1000,不能太少,否則效果就不好了,其中HOG_SVM.txt裡面包含了判別函式的引數,這個引數可以直接給HOG用
下面就是我的測試效果:
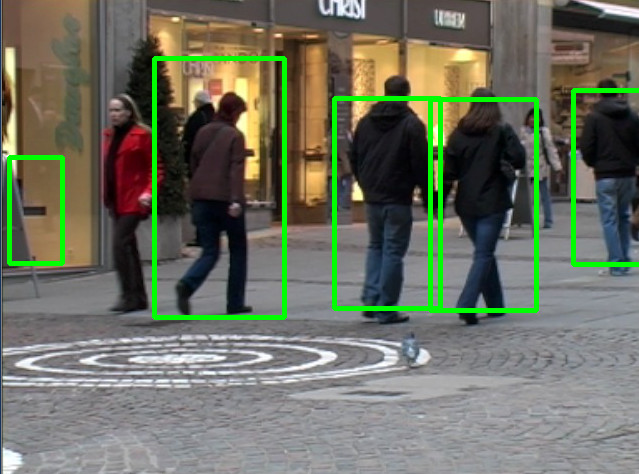

檢測效果還可以.
測試圖片我也上傳到網上了
點選下載
當然你也可以不用自己訓練分類器,直接使用OpenCV自帶的分類器,OpenCV自帶的分類器使用的是05年CVPR那篇文章中作者訓練好的分類器,下面我們就來看看效果:


圖中可以看出,OpenCV自帶的分類器效果要比自己訓練的好,主要原因大概有以下幾點
1.訓練樣本不足,我的正負樣本才900多
2.正樣本圖片不夠清晰,導致特徵提取有比較大的誤差
最近有人在執行部落格中程式的時候出現了問題,讓我看看程式,我也不太清楚什麼問題,所以我將整個程式和程式測試資料打包了一下,上傳到了CSDN上。
點選下載
解壓後,將”Pedestrians64x128”資料夾放置在D盤根目錄,然後使用HOG.cpp新建一個工程,直接可以執行。
注:環境是VS2013+OpenCV3.0.0,Release版本
第二種
下面說說第二種方式,第二種方式就是傳統的方式了,就是對於測試樣本,提取特徵,然後使用訓練好的分類器進行識別,程式碼
///////////////////////////////////HOG+SVM識別方式1///////////////////////////////////////////////////
void HOG_SVM1()
{
////////////////////////////////讀入訓練樣本圖片路徑和類別///////////////////////////////////////////////////
//影象路徑和類別
vector<string> imagePath;
vector<int> imageClass;
int numberOfLine = 0;
string buffer;
ifstream trainingData(string(FILEPATH) + "TrainData.txt", ios::in);
unsigned long n;
while (!trainingData.eof())
{
getline(trainingData, buffer);
if (!buffer.empty())
{
++numberOfLine;
if (numberOfLine % 2 == 0)
{
//讀取樣本類別
imageClass.push_back(atoi(buffer.c_str()));
}
else
{
//讀取影象路徑
imagePath.push_back(buffer);
}
}
}
trainingData.close();
////////////////////////////////獲取樣本的HOG特徵///////////////////////////////////////////////////
//樣本特徵向量矩陣
int numberOfSample = numberOfLine / 2;
Mat featureVectorOfSample(numberOfSample, 3780, CV_32FC1);//矩陣中每行為一個樣本
//樣本的類別
Mat classOfSample(numberOfSample, 1, CV_32SC1);
//開始計算訓練樣本的HOG特徵
for (vector<string>::size_type i = 0; i <= imagePath.size() - 1; ++i)
{
//讀入圖片
Mat src = imread(imagePath[i], -1);
if (src.empty())
{
cout << "can not load the image:" << imagePath[i] << endl;
continue;
}
cout << "processing" << imagePath[i] << endl;
//縮放
Mat trainImage;
resize(src, trainImage, Size(64, 128));
//提取HOG特徵
HOGDescriptor hog(Size(64, 128), Size(16, 16), Size(8, 8), Size(8, 8), 9);
vector<float> descriptors;
hog.compute(trainImage, descriptors);//這裡可以設定檢測視窗步長,如果圖片大小超過64×128,可以設定winStride
cout << "HOG dimensions:" << descriptors.size() << endl;
//儲存特徵向量矩陣中
for (vector<float>::size_type j = 0; j <= descriptors.size() - 1; ++j)
{
featureVectorOfSample.at<float>(i, j) = descriptors[j];
}
//儲存類別到類別矩陣
//!!注意類別型別一定要是int 型別的
classOfSample.at<int>(i, 0) = imageClass[i];
}
///////////////////////////////////使用SVM分類器訓練///////////////////////////////////////////////////
//設定引數
//參考3.0的Demo
Ptr<SVM> svm = SVM::create();
svm->setKernel(SVM::RBF);
svm->setType(SVM::C_SVC);
svm->setC(10);
svm->setCoef0(1.0);
svm->setP(1.0);
svm->setNu(0.5);
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_EPS, 1000, FLT_EPSILON));
//使用SVM學習
svm->train(featureVectorOfSample, ROW_SAMPLE, classOfSample);
//儲存分類器
svm->save("Classifier.xml");
///////////////////////////////////使用訓練好的分類器進行識別///////////////////////////////////////////////////
vector<string> testImagePath;
ifstream testData(string(FILEPATH) + "TestData.txt", ios::out);
while (!testData.eof())
{
getline(testData, buffer);
//讀取
if (!buffer.empty())
testImagePath.push_back(buffer);
}
testData.close();
ofstream fileOfPredictResult(string(FILEPATH) + "PredictResult.txt"); //最後識別的結果
for (vector<string>::size_type i = 0; i <= testImagePath.size() - 1; ++i)
{
//讀取測試圖片
Mat src = imread(testImagePath[i], -1);
if (src.empty())
{
cout << "Can not load the image:" << testImagePath[i] << endl;
continue;
}
//縮放
Mat testImage;
resize(src, testImage, Size(64, 64));
//測試圖片提取HOG特徵
HOGDescriptor hog(cvSize(64, 64), cvSize(16, 16), cvSize(8, 8), cvSize(8, 8), 9);
vector<float> descriptors;
hog.compute(testImage, descriptors);
cout << "HOG dimensions:" << descriptors.size() << endl;
Mat featureVectorOfTestImage(1, descriptors.size(), CV_32FC1);
for (int j = 0; j <= descriptors.size() - 1; ++j)
{
featureVectorOfTestImage.at<float>(0, j) = descriptors[j];
}
//對測試圖片進行分類並寫入檔案
int predictResult = svm->predict(featureVectorOfTestImage);
char line[512];
//printf("%s %d\r\n", testImagePath[i].c_str(), predictResult);
std::sprintf(line, "%s %d\n", testImagePath[i].c_str(), predictResult);
fileOfPredictResult << line;
}
fileOfPredictResult.close();
}
int main()
{
//HOG+SVM識別方式1:直接輸出類別
HOG_SVM1();
//HOG+SVM識別方式2:輸出圖片中的存在目標的矩形
//HOG_SVM2();
}大家可以分別使用自己的資料集測試一下上面的兩種方式,如果有上面疑問,歡迎留言討論
非常感謝您的閱讀,如果您覺得這篇文章對您有幫助,歡迎掃碼進行讚賞。
