
python3 的 str與bytes
阿新 • • 發佈:2019-01-04
string and bytes
python3只有一種儲存文字資訊的資料型別:str,str是一種不可變序列,儲存的資料是Unicode的“碼位”資訊,說白了就是某個(utf-8,big-5等)編碼集中的字元。
python3的bytes或者bytearray與str不同,只能儲存‘十六進位制的0 - 255’(也就是8位(2^8))以內的編碼組成的不可修改的陣列,編碼的含義由不同的編碼方式(utf-8, big5等)決定。
白話文:string儲存的是字元列表,bytes儲存的是字元的編碼的陣列。
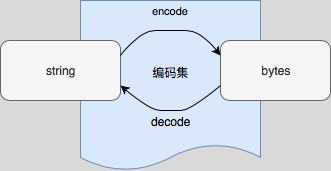
string 和 bytes之間的轉換
string和bytes之間的轉換:
>>> b = bytes('中文', 'utf-8')
>>> b
b'\xe4\xb8\xad\xe6\x96\x87'
>>> b.decode('Windows 1252')
'ä¸\xadæ–‡'
>>> b.decode('ISO8859-7')
'δΈ\xadζ\x96\x87'
>>> string = b.decode('utf-8')
>>> string
'中文'
>>> b = string.encode('utf-8')
>>