
新手的caffe學習總結(影象識別)
公司要往影象識別方面拓展業務,奈何沒有人對這方面有哪怕稍微深入點的瞭解,本人榮挑重擔,從只知道AI這個名詞的小白開始學習深度學習。到現在學習caffe接近兩個月了,中間走了很多彎路,遇到很多對新手來說是難題,對熟悉這方面的人來說卻簡單到不認為是問題的問題。所以總結下來供像我這樣的新手學習
一、Linux
1、進入root許可權
執行下面的程式碼
sudo su然後提示輸入密碼,就可以進入root許可權了(root許可權相當於windows下的管理員許可權,密碼是系統的開機密碼)
2、修改檔案的許可權
有些檔案在Linux系統下顯示帶鎖的圖示,這樣的檔案不能直接修改刪除,所以一般需要修改許可權
我通常用下面的程式碼修改
chmod 777 -R /path/to/file二、caffe
1、生成日誌檔案
使用caffe生成模型的時候,我們可能想生成loss、accuracy曲線,方便檢視引數對模型好壞的影響。如果用python的方法,每次生成曲線都要重新訓練模型,非常浪費時間,所以我採用caffe自帶的檔案來完成任務
首先生成 .log檔案(此檔案會自動儲存你訓練過程中terminal顯示的內容)執行代命令如下:
time sh examples/myfile/train.sh 2>&1 | tee examples/myfile/record1.log
time:在terminal中顯示訓練花費的時間
sh examples/myfile/train.sh :執行myfiile資料夾下的train.sh檔案,(訓練模型要執行的檔案)
examples/myfile/record1.log :生成的log檔案要儲存的位置,record1是儲存的檔名
2、利用log檔案生成loss函式
命令如下:
./tools/extra/plot_training_log.py.example "0" "image.png" examples/myfile/record1.log“0” :此處可以改為0、1、2、3、4、5、6、7,用來生成不同的曲線,可以自行嘗試
“image.png” :生成的曲線儲存的位置和儲存的檔名
examples/myfile/record1.log :要呼叫的log檔案(上一步生成的log檔案)
3、修改圖片大小
命令:
for name in /home/username/caffe/data/image/train/0/*.jpg; do convert -resize 256x256\! $name $name; done4、C++方法檢視模型對圖片的識別概率
命令:
sudo ./build/examples/cpp_classification/classification.bin \
models/bvlc_reference_caffenet/deploy.prototxt \
models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel \
data/ilsvrc12/imagenet_mean.binaryproto \
data/ilsvrc12/synset_words.txt \
examples/images/cat.jpg
classification.bin :caffe自帶的圖片分類器
deploy.prototxt :類似train_val.prototxt檔案,但又不同,只用於使用模型進行影象識別的時候(沒有這個檔案或者不知道怎麼修改這個檔案,可自行百度)
bvlc_reference_caffenet.caffemodel :要使用的模型,可以替換成你自己的模型
imagenet_mean.binaryproto :對應的均值檔案
synset_words.txt :圖片類別對應的含義。訓練的資料集帶有標籤,使用模型分類的結果會給出標籤,這個檔案用來解釋標籤代表的含義
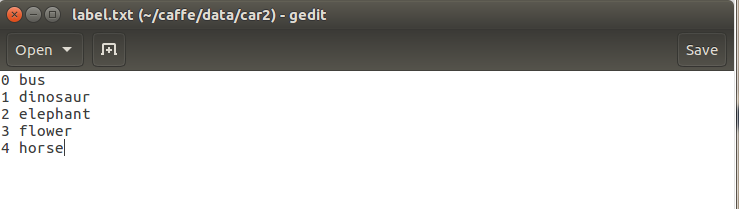
如圖,我的synset_words.txt檔案(不過我把檔名改為:label.txt。注意此檔案一定要在Linux下建立編輯完成,不能直接在windows下建立,複製到Linux下,不然輸出的概率值的格式很奇怪)