
PyTorch: 序列到序列模型(Seq2Seq)實現機器翻譯實戰
簡介
在這個專案中,我們將使用PyTorch框架實現一個神經網路,這個網路實現法文翻譯成英文。這個專案是Sean Robertson寫的稍微複雜一點的教程,但對學習PyTorch還是有很大的幫助。
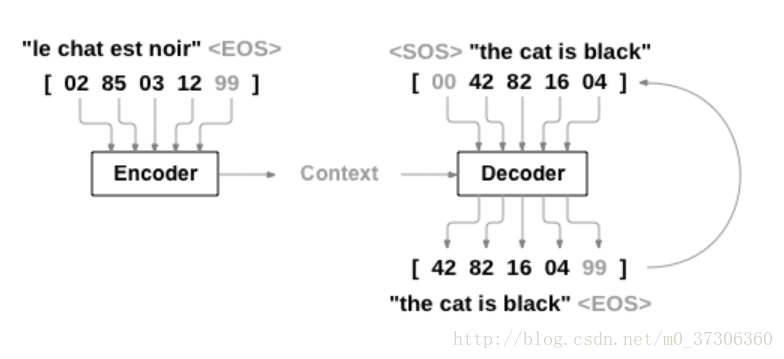
本文通過序列網路的這種簡單而強大的思想來實現的,其中包括兩個迴圈神經網路一起工作以將一個序列轉換為另一個序列。 編碼器網路(Encode)將輸入序列壓縮成向量,解碼器網路(Decode)將該向量展開為新的序列。為了改進這個模型,我們將使用一個注意機制,讓解碼器學習把注意力集中在輸入序列的特定範圍上。
資料集
這個專案的資料是一組數以千計的英語到法語的翻譯對。作者選取了其中部分資料構建本文的訓練資料集(data / eng-fra.txt)。 該檔案是一個製表符分隔的翻譯對列表(下載地址:

我們才有one-hot vector初始化詞,與前面分類名詞不同的是,這裡把單詞看作一個獨立的語言粒度:
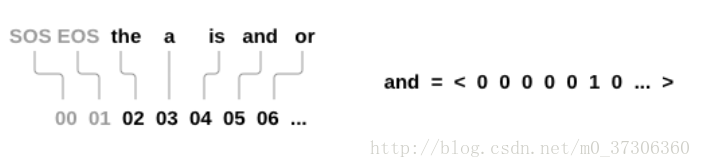
我們需要每個單詞的唯一索引作為以後網路的輸入(inputs)和目標(targets)。 為此,我們使用名為Lang的助手類,它具有詞→索引(word2index)和索引→詞(index2word)字典,以及每個單詞word2count的計數以用於稍後替換罕見詞語。
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name) 要讀取資料檔案,我們將檔案分割成幾行,然後將行分成兩部分。 這些檔案都是英文→其他語言,所以如果我們想從其他語言翻譯→英文,我添加了reverse標誌來反轉對。
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs本文資料預處理過程是:
1.讀取文字檔案並拆分成行,將行拆分成對
2.使文字標準化,按照長度和內容進行過濾
3.從成對的句子中構建單詞列表
Seq2Seq模型
Seq2Seq(Sequence to Sequence network or Encoder Decoder network)是由兩個稱為編碼器和解碼器的RNN組成的模型。 編碼器讀取輸入序列並輸出單個向量,解碼器讀取該向量以產生輸出序列。
與單個RNN的序列預測不同,每個輸入對應於一個輸出,seq2seq模型無需考慮序列長度和順序,這使得它成為兩種語言之間翻譯的理想選擇。使用seq2seq模型,編碼器會建立一個單一的向量,在理想的情況下,將輸入序列的“含義”編碼為單個向量 - 句子的N維空間中的單個點。
The Encoder
seq2seq網路的編碼器是一個RNN,它為輸入句子中的每個單詞輸出一些值。 對於每個輸入單詞,編碼器輸出一個向量和一個隱藏狀態,這個隱藏狀態和下一個單詞構成下一步的輸入。
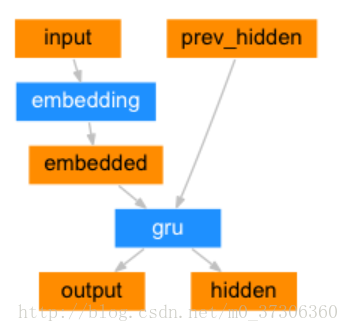
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
The Decoder
解碼器是另一個RNN,它接收編碼器輸出向量並輸出一個字序列來建立翻譯。
在最簡單的seq2seq解碼器中,我們只使用編碼器的最後一個輸出。 這個最後的輸出有時被稱為上下文向量,因為它從整個序列編碼上下文。 該上下文向量被用作解碼器的初始隱藏狀態。如果僅在編碼器和解碼器之間傳遞上下文向量,則該單個向量承擔編碼整個句子的負擔。注意力(Attention Decoder)允許解碼器網路針對解碼器自身輸出的每一步“聚焦”編碼器輸出的不同部分。首先我們計算一組注意力權重。 這些將被乘以編碼器輸出向量以建立加權組合。
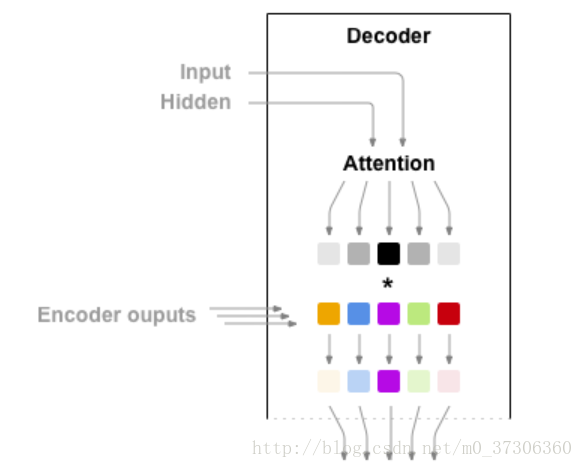
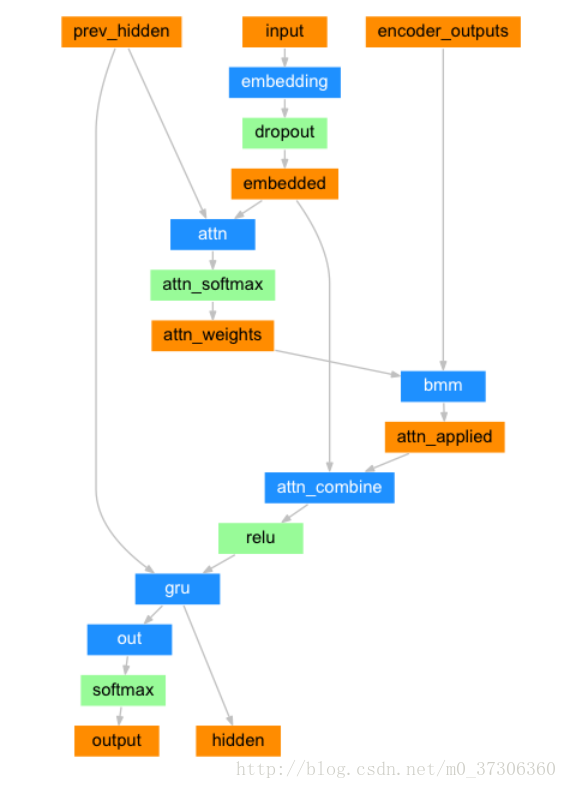
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result訓練和測試模型
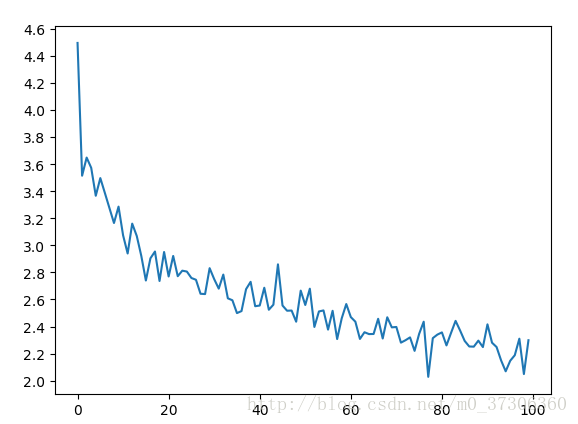
loss 圖:
評估與訓練大部分相同,但沒有目標(target),因此我們只是將解碼器的預測反饋給每一步的自身。 每當它預測到一個單詞時,我們就會將它新增到輸出字串中,並且當生成EOS字元就停止。 我們還儲存解碼器的注意力輸出以供稍後顯示。
視覺化Attention,這個機制的一個有用特性是其高度可解釋的輸出。 因為它用於對輸入序列的特定編碼器輸出進行加權,所以我們可以想象在每個時間步驟中網路最集中的位置。這裡將注意力輸出顯示為矩陣,其中列是輸入步驟,行是輸出步驟:
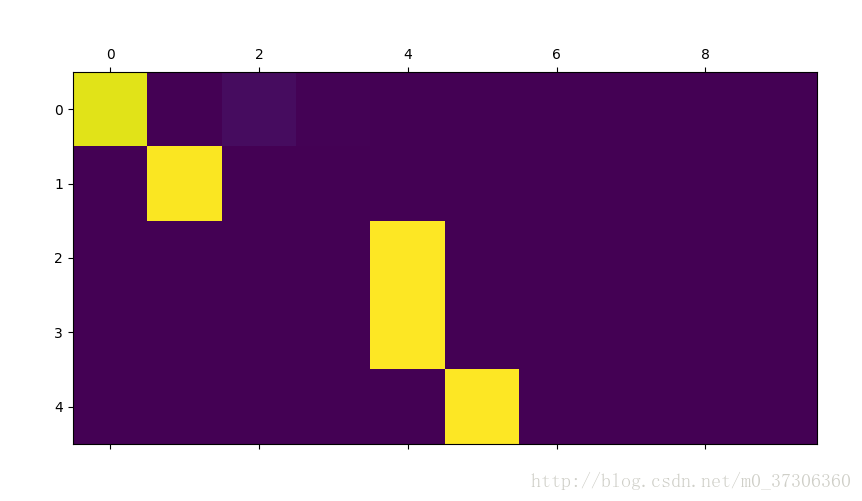
更好的觀看體驗,我們額外用了幾個資料對:
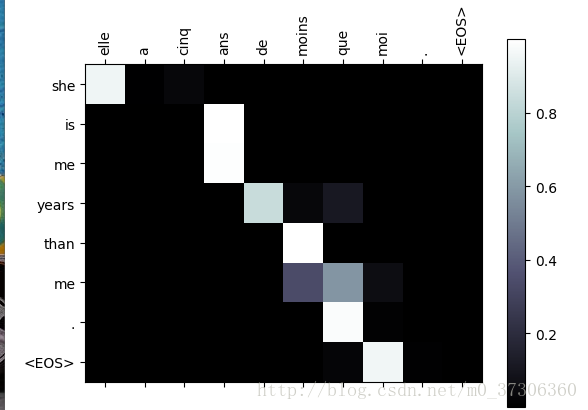
注意:所以的程式碼基本上為教程上的,我跑通的程式碼稍微會上傳到github上。