
瀏覽器載入、解析、渲染的過程
最近在學習效能優化,學習了雅虎軍規 ,可是覺著有點雲裡霧裡的,因為裡面有些東西雖然自己也一直在使用,但是感覺不太明白所以然,比如減少DNS查詢,css和js檔案的順序。所以就花了時間去了解瀏覽器的工作,有一篇經典的文章《how browsers work》 ,講的很詳細,也有中文譯本 。不過就是文章有點太長,也講了一堆東西,還是自己總結一下。
為什麼要了解瀏覽器載入、解析、渲染這個過程?
好,我們先說一下,為什麼要了解這些呢?如果想寫出一個最佳實踐的頁面,就要好好了解。
- 瞭解瀏覽器如何進行載入,可以在引用外部樣式檔案,外部js時,將他們放到合適的位置,使瀏覽器以最快的速度將檔案載入完畢。
- 瞭解瀏覽器如何進行解析,可以在構建DOM結構,組織css選擇器時,選擇最優的寫法,提高瀏覽器的解析速率。
- 瞭解瀏覽器如何進行渲染,明白渲染的過程,在設定元素屬性,編寫js檔案時,可以減少”reflow“”repaint“的消耗。
正文開始
一、瀏覽器的主要功能
瀏覽器的主要功能是將使用者選擇的web資源呈現出來,它需要從伺服器請求資源,並將其顯示在瀏覽器視窗中,資源的格式通常是HTML,也包括PDF、image及其他格式。使用者用URI(Uniform Resource Identifier統一資源識別符號)來指定所請求資源的位置,通過DNS查詢,將網址轉換為IP地址。整個瀏覽器工作的流程,
1、輸入網址。
2、瀏覽器查詢域名的IP地址。
3. 瀏覽器給web伺服器傳送一個HTTP請求
4. 網站服務的永久重定向響應
5. 瀏覽器跟蹤重定向地址 現在,瀏覽器知道了要訪問的正確地址,所以它會發送另一個獲取請求。
6. 伺服器“處理”請求,伺服器接收到獲取請求,然後處理並返回一個響應。
7. 伺服器發回一個HTML響應
8. 瀏覽器開始顯示HTML
9. 瀏覽器傳送請求,以獲取嵌入在HTML中的物件。在瀏覽器顯示HTML時,它會注意到需要獲取其他地址內容的標籤。這時,瀏覽器會發送一個獲取請求來重新獲得這些檔案。這些檔案就包括CSS/JS/圖片等資源,這些資源的地址都要經歷一個和HTML讀取類似的過程。所以瀏覽器會在DNS中查詢這些域名,傳送請求,重定向等等…
那麼,一個頁面,究竟是如何從我們輸入一個網址到最後完整的呈現在我們面前的呢?還需要了解一下瀏覽器是如何渲染的:
二、瀏覽器的渲染
下面是渲染引擎在取得內容之後的基本流程:
解析html以構建dom樹 -> 構建render樹 -> 佈局render樹 -> 繪製render樹
先來看個圖:
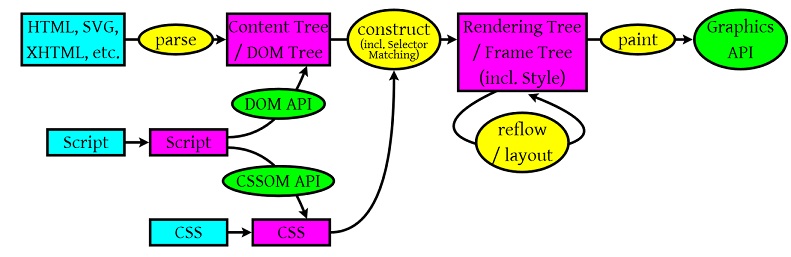
所以,瀏覽器會解析三個東西:
(1) HTML/SVG/XHTML,解析這三種檔案會產生一個 DOM Tree。
(2) CSS,解析 CSS 會產生 CSS 規則樹。
(3) Javascript指令碼,主要是通過 DOM API 和 CSSOM API 來操作 DOM Tree 和 CSS Rule Tree.
我今天又糾結了一上午,到底是怎麼解析怎麼渲染的,我的疑問在於,瀏覽器到底是先解析生成了DOM樹,然後再載入CSS JS檔案進行渲染,還是在生成DOM的過程中,遇到了 link script 然後就載入CSS JS,邊載入邊渲染。我有這種疑問的原因在於,看網上的帖子,說的根本不一樣好嘛! 比如這篇 我想說,這個寫的讓我直接懵逼,真的是直接懵逼啊,學習的過程中,總會遇到困難,但這次,讓我真的好難啊。不過正因為不懂才繼續查資料繼續學習嘛 ==!我又查了一上午,自己測試測試測試,然後覺著,我好像是明白點了。真的推薦大家去認真看《how browsers work》這篇文章,學習不懂得知識的時候,還是要從比較權威的資料看起比較好,也不要像我今天這樣,無頭蒼蠅亂查。
那麼就來說一下圖中的過程,我是按照自己的理解來說,如果有誤,歡迎指正。
當瀏覽器獲得一個html檔案時,會
“自上而下”載入,並在載入過程中進行解析渲染。
解析:
1. 瀏覽器會將HTML解析成一個DOM樹,DOM 樹的構建過程是一個深度遍歷過程:當前節點的所有子節點都構建好後才會去構建當前節點的下一個兄弟節點。
2. 將CSS解析成 CSS Rule Tree 。
3. 根據DOM樹和CSSOM來構造 Rendering Tree。注意:Rendering Tree 渲染樹並不等同於 DOM 樹,因為一些像 Header 或 display:none 的東西就沒必要放在渲染樹中了。
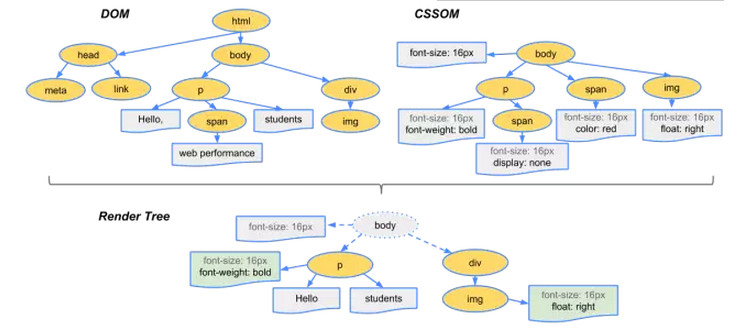
4.有了Render Tree,瀏覽器已經能知道網頁中有哪些節點、各個節點的CSS定義以及他們的從屬關係。下一步操作稱之為Layout,顧名思義就是計算出每個節點在螢幕中的位置。
5.再下一步就是繪製,即遍歷render樹,並使用UI後端層繪製每個節點。
重點來了:
上述這個過程是逐步完成的,為了更好的使用者體驗,渲染引擎將會盡可能早的將內容呈現到螢幕上,並不會等到所有的html都解析完成之後再去構建和佈局render樹。它是解析完一部分內容就顯示一部分內容,同時,可能還在通過網路下載其餘內容。(這段話是《how browsers work》裡面講的,讓我茅塞頓開)
幾個概念:
(1)Reflow(迴流):瀏覽器要花時間去渲染,當它發現了某個部分發生了變化影響了佈局,那就需要倒回去重新渲染。
(2)Repaint(重繪):如果只是改變了某個元素的背景顏色,文字顏色等,不影響元素周圍或內部佈局的屬性,將只會引起瀏覽器的repaint,重畫某一部分。
Reflow要比Repaint更花費時間,也就更影響效能。所以在寫程式碼的時候,要儘量避免過多的Reflow。
reflow的原因:
(1)頁面初始化的時候;
(2)操作DOM時;
(3)某些元素的尺寸變了;
(4)如果 CSS 的屬性發生變化了。
減少 reflow/repaint
(1)不要一條一條地修改 DOM 的樣式。與其這樣,還不如預先定義好 css 的 class,然後修改 DOM 的 className。
(2)不要把 DOM 結點的屬性值放在一個迴圈裡當成迴圈裡的變數。
(3)為動畫的 HTML 元件使用 fixed 或 absoult 的 position,那麼修改他們的 CSS 是不會 reflow 的。
(4)千萬不要使用 table 佈局。因為可能很小的一個小改動會造成整個 table 的重新佈局。
我應該是已經把網上所有的關於瀏覽器載入 解析 渲染過程的文章都看全了,其中寫的比較好的一個版本是下面這個:
1. 使用者輸入網址(假設是個html頁面,並且是第一次訪問),瀏覽器向伺服器發出請求,伺服器返回html檔案;
2. 瀏覽器開始載入html程式碼,發現<head>標籤內有一個<link>標籤引用外部CSS檔案;
3. 瀏覽器又發出CSS檔案的請求,伺服器返回這個CSS檔案;
4. 瀏覽器繼續載入html中<body>部分的程式碼,並且CSS檔案已經拿到手了,可以開始渲染頁面了;
5. 瀏覽器在程式碼中發現一個<img>標籤引用了一張圖片,向伺服器發出請求。此時瀏覽器不會等到圖片下載完,而是繼續渲染後面的程式碼;
6. 伺服器返回圖片檔案,由於圖片佔用了一定面積,影響了後面段落的排布,因此瀏覽器需要回過頭來重新渲染這部分程式碼;
7. 瀏覽器發現了一個包含一行Javascript程式碼的<script>標籤,趕快執行它;
8. Javascript指令碼執行了這條語句,它命令瀏覽器隱藏掉程式碼中的某個<div> (style.display=”none”)。突然少了這麼一個元素,瀏覽器不得不重新渲染這部分程式碼;
9. 終於等到了</html>的到來,瀏覽器淚流滿面……
10. 等等,還沒完,使用者點了一下介面中的“換膚”按鈕,Javascript讓瀏覽器換了一下<link>標籤的CSS路徑;
11. 瀏覽器召集了在座的各位<div><span><ul><li>們,“大夥兒收拾收拾行李,咱得重新來過……”,瀏覽器向伺服器請求了新的CSS檔案,重新渲染頁面。
與討論主題相關的其他思考
編寫CSS時應該注意:
CSS選擇符是從右到左進行匹配的。從右到左!所以,#nav li 我們以為這是一條很簡單的規則,秒秒鐘就能匹配到想要的元素,但是,但是,但是,是從右往左匹配啊,所以,會去找所有的li,然後再去確定它的父元素是不是#nav。,因此,寫css的時候需要注意:
- dom深度儘量淺。
- 減少inline javascript、css的數量。
- 使用現代合法的css屬性。
- 不要為id選擇器指定類名或是標籤,因為id可以唯一確定一個元素。
- 避免後代選擇符,儘量使用子選擇符。原因:子元素匹配符的概率要大於後代元素匹配符。後代選擇符;#tp p{} 子選擇符:#tp>p{}
- 避免使用萬用字元,舉一個例子,.mod .hd *{font-size:14px;} 根據匹配順序,將首先匹配萬用字元,也就是說先匹配出萬用字元,然後匹配.hd(就是要對dom樹上的所有節點進行遍歷他的父級元素),然後匹配.mod,這樣的效能耗費可想而知.
關於script標籤的位置
現在,我們大都會將script標籤放在body結束標籤之前,那原因是什麼呢?我今天也做了一個測試。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>測試js程式碼位置</title>
<script type="text/javascript">
var item = document.getElementById("item");
cosole.log(item);
</script>
</head>
<body>
<div id="item" width="100px" height="100px">
你好
</div>
</body>
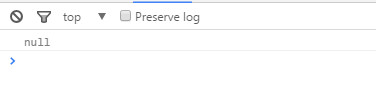
</html>上述程式碼中有一段js程式碼,要在控制檯列印一個元素,我把script標籤放在head裡,控制檯裡打印出來的是null。
我又把js程式碼放在body結束標籤之前,打印出來的就是div元素了
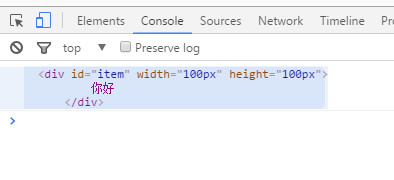
所以,通過這個簡單的例子我們可以看到,js程式碼在載入完後,是立即執行的。
我又做了一個測試,在js程式碼裡面寫了一個死迴圈,把它放在head標籤中,
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>測試js程式碼位置</title>
<script type="text/javascript">
var item = document.getElementById("item");
while(true){
console.log(1);
}
</script>
</head>
<body>
<div id="item" width="100px" height="100px">
你好
</div>
</body>
</html>頁面是這樣的:
一直在執行那個列印1的死迴圈,後面的body都沒有載入渲染出來。所以,這個小例子,我們可以看出,js的下載和執行會阻塞Dom樹的構建。
所以,Javascript的載入和執行的特點:
(1)載入後馬上執行;
(2)執行時會阻塞頁面後續的內容(包括頁面的渲染、其它資源的下載)。原因:因為瀏覽器需要一個穩定的DOM樹結構,而JS中很有可能有 程式碼直接改變了DOM樹結構,比如使用 document.write 或 appendChild,甚至是直接使用的location.href進行跳轉,瀏覽器為了防止出現JS修 改DOM樹,需要重新構建DOM樹的情況,所以 就會阻塞其他的下載和呈現。
減少 JavaScript 對效能的影響的方法:
- 將所有的script標籤放到頁面底部,也就是body閉合標籤之前,這能確保在指令碼執行前頁面已經完成了DOM樹渲染。
- 儘可能地合併指令碼。頁面中的script標籤越少,載入也就越快,響應也越迅速。無論是外鏈指令碼還是內嵌指令碼都是如此。
- 採用無阻塞下載 JavaScript 指令碼的方法:
(1)使用script標籤的 defer 屬性(僅適用於 IE 和 Firefox 3.5 以上版本);
(2)使用動態建立的script元素來下載並執行程式碼;
好了,寫到這裡吧,我想靜靜。