
IntelliJ IDEA搭建Hadoop開發環境
前言
這是關於Hadoop的系列文章。
準備
事實上,我前面搭建的關於Hadoop的開發環境已經夠用了。可是那始終是提交到本地的,任務在本地跑,總讓人感覺怪怪的。而且還依賴著HADOOP_HOME這樣的環境變數,還得選中依賴的jar包以及依賴所謂的外掛。所以我想可不可以用maven來管理我們需要的jar,然後通過一定的設定讓我們的任務提交到遠端去呢!
我先來說說本次專案的搭建需要依賴的東西:
就只是maven,沒錯,就只是maven。好了,廢話不多說迅速的開始幹活!
依賴的jar
這裡的話實際上我們只需要依賴hadoop的核心jar包即可。如下所示是我的pom中的全部依賴:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency> 之所以要依賴這個examples只是要看Hadoop為我們提供的一些基本的例子,實際上Hadoop為我們提供了非常多的例子,大家只需要搜尋最著名的WordCount就可以在同一個包下發現非常豐富的例子,實際上對這些例子只要能熟練的掌握那麼就可以很好的掌握基本知識了。畢竟官方的資料才是最好的。
好了,下面我們來看程式碼,從windows向Hadoop的linux叢集提交是有問題的,你上網一搜索,有很多帖子都會說要改什麼原始碼啊之類的,實際上,在早期的1.X版本確實存在這樣的情況。因為那時候的Hadoop從windows向linux提交存在一個bug。而現在,2.X版本已將修復。但是需要額外的設定。好了,我們來一點點的看程式碼,看和上一篇的程式碼的不同。我大致分為了兩個方面:
第一個方面就是說我們要將我們叢集的配置檔案設定到這裡來,這是非常重要的,實際上如果你通過斷點除錯就會發現,Hadoop為我們設定了預設的配置檔案。如下圖:
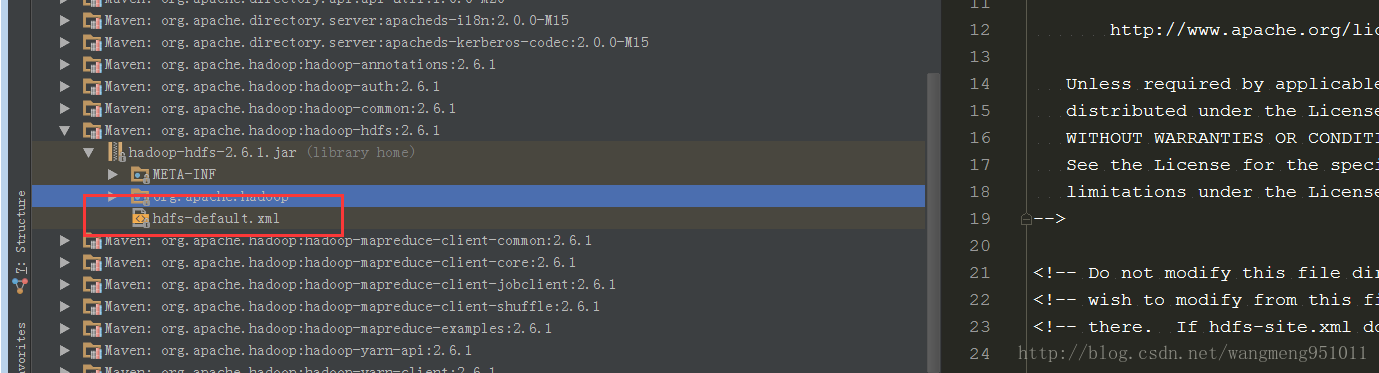
我們可以看到,在jar包裡面就有,實際上對應的四個配置檔案都有的。所以說當你不做任何事情的時候,當然是按照人家的來嘍!結果就是任務提交到本地。當然,我們可以自己設定,設定如下:
private static void setProties(JobConf conf) throws FileNotFoundException {
conf.addResource("/core-site.xml");
conf.addResource("/hdfs-site.xml");
conf.addResource("/mapred-site.xml");
conf.addResource("/yarn-site.xml");
}有了上面的設定,我們就可以提交到遠端linux了嗎?當然不行。下面進入第二步,設定一些其他的引數,我前面有講到過,跨平臺提交在1.x版本是一個bug,而後修復,但是需要通過配置的方式才可以正常提交。配置如下:
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.job.ubertask.enable", "true");
conf.setUser("hadoop");
conf.set("mapreduce.job.jar", "E:\\github\\hadoop\\target\\fulei-1.0-SNAPSHOT.jar"); 我們可以很清晰的看出來,第一個設定的引數cross-platform明顯就是跨平臺的意思啊,阿偶!當然後面的設定jar包也非常重要,因為你要提交任務到遠端,所以必須制定本地jar的位置,啊哈!這樣的話,我們快就可以提交任務到遠端了。當然,這裡的遠端大部分時候指的還是我們的虛擬機器而已。當然,如果你有云伺服器的,就更好了。啊哈!
當然,我們還需要在marped-site.xml配置如下內容,這是我從預設的配置檔案中摘出來的。
<property>
<description>If enabled, user can submit an application cross-platform
i.e. submit an application from a Windows client to a Linux/Unix server or
vice versa.
</description>
<name>mapreduce.app-submission.cross-platform</name>
<value>false</value>
</property>
<property>
<description>CLASSPATH for MR applications. A comma-separated list
of CLASSPATH entries. If mapreduce.application.framework is set then this
must specify the appropriate classpath for that archive, and the name of
the archive must be present in the classpath.
If mapreduce.app-submission.cross-platform is false, platform-specific
environment vairable expansion syntax would be used to construct the default
CLASSPATH entries.
For Linux:
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*.
For Windows:
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*.
If mapreduce.app-submission.cross-platform is true, platform-agnostic default
CLASSPATH for MR applications would be used:
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/*,
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/lib/*
Parameter expansion marker will be replaced by NodeManager on container
launch based on the underlying OS accordingly.
</description>
<name>mapreduce.application.classpath</name>
<value></value>
</property> 這個上面已經說得非常明白,如果設定了cross-platform的話,就要設值叢集上的jar的位置,否則Hadoop在提交任務後會報Classnotfound的問題。到了這裡,我們可以說已經配置完了。
我們現在來看看執行的效果如何:
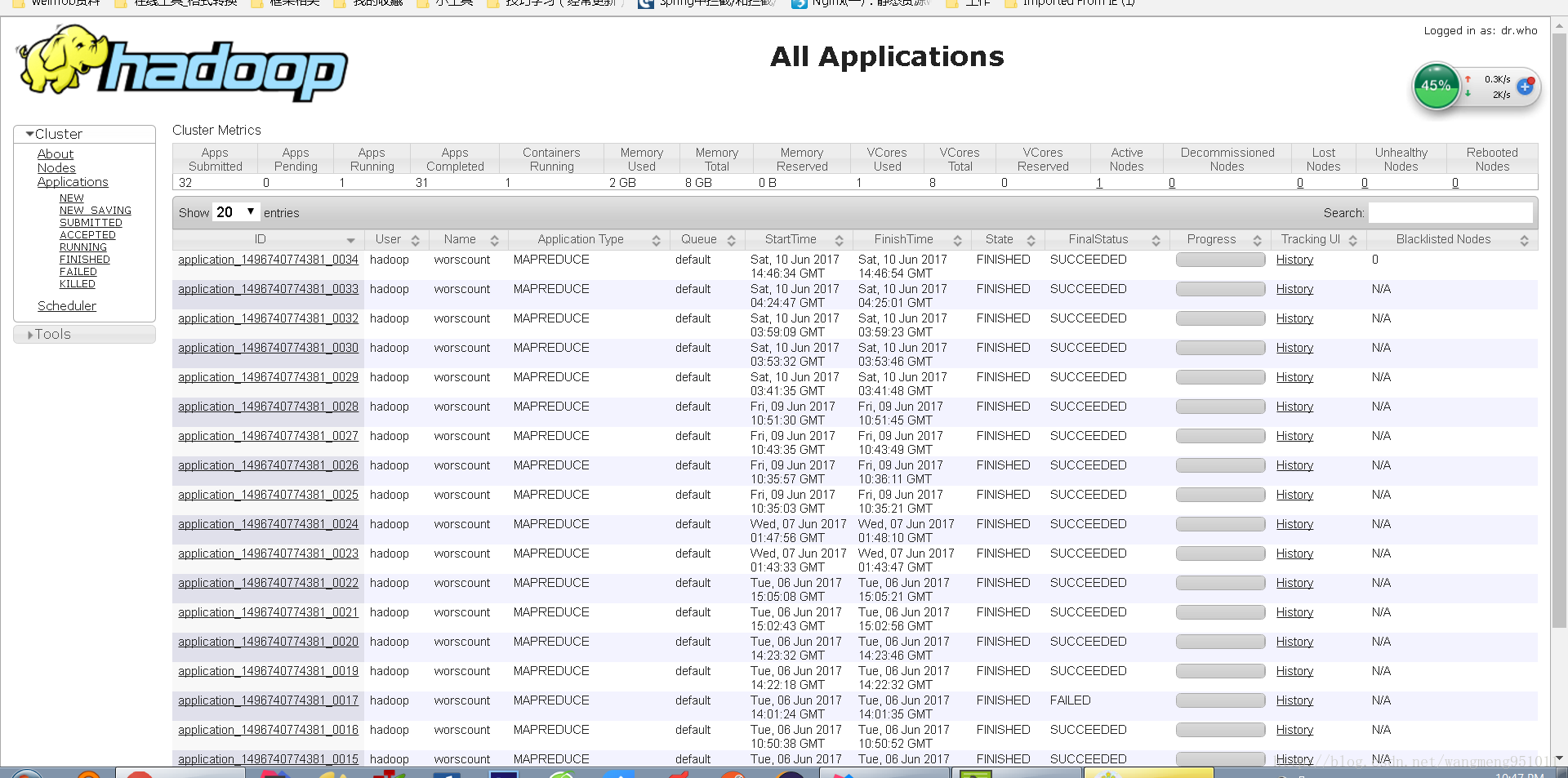
任務已經成功的執行,好了,我們現在就可以使用這一個專案隨處運行了,再也不用擔心環境問題了。哈哈
總結
阿福才疏學淺,可能有說的不夠到位的地方,希望大家看出指正!
到了這裡我們的環境基本上來說就可以確定就用這一套東西了,接下來就是mr的處理詳解了。下一篇講給大家帶來mr的處理流程。
好了,各位晚安!有什麼不懂的歡迎在評論區提問啊!