【XML解析】(1)Java下使用JAXP中的DOM解析方式對XML文件進行解析
關於JAXP、DOM、SAX:
何為JAXP?
JAXP(JavaApi for Xml Programming) – sun公司的一套操作XML的API。
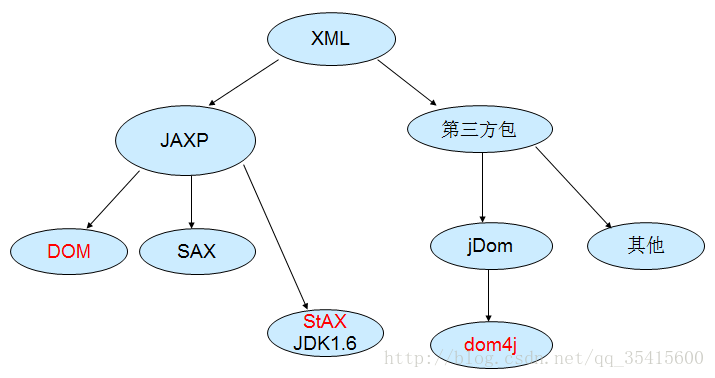
JAXP中分為三種解析方式:
DOM解析、SAX解析、StAX
DOM解析:一次性的將資料全部裝入記憶體。
SAX解析:邊讀取邊解析。
DOM、SAX、StAX關鍵詞解釋:
【DOM】:
DOM-Document Object Model-文件對像模型。是w3c組織處理xml的一種方式。
DOM的特點:
①一次將所有資料全部載入到記憶體中。
②對xml文件中的每一個節點都當成一個Node對像處理。包括元素、文字、屬性。
③org.w3c.dom包中的Document,Element,Node。
④非常方便進行修改。
⑤已經整合在了JDK中,是Sun對xml操作的標準。
⑥缺點是當文件資料量很大時,對記憶體有佔用很大。
【SAX】:
Sax – Simple Api for XML 。
①在讀取資料時分析資料,通過事件監聽器來完成。
②速度快但只適合讀取資料,僅向前讀取不可後退。
【StAX】:
①The Streaming API for XML基於流的XML程式設計介面
②StAX即可讀文件也可以寫文件。
③而SAX只可以讀取文件。
XML解析的方式分為以下幾種-圖解:
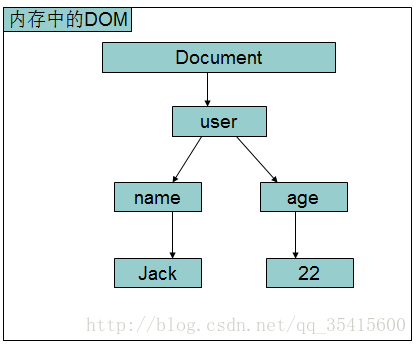
DOM解析的說明:
DOM解析一次將所有的元素全部載入到記憶體中:如有以下XML文件(users.xml):
users.xml:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="A001">
<name user.xml在記憶體中的DOM結構:
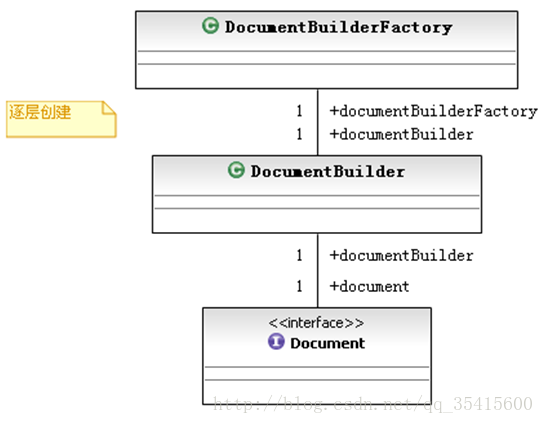
JAXP-DOM解析時候用到的Java包:
【org.w3c.dom】 – 關鍵類Document代表記憶體中的文件對像模型。

w3c是制定標準,具體的實現還是看sun公javax.xml.parsers【javax.xml.parse】– 關鍵類DocumentBuilder,文件解析對像。
【javax.xml】– 關鍵類Transformer,用於將記憶體中的文件儲存到檔案中。
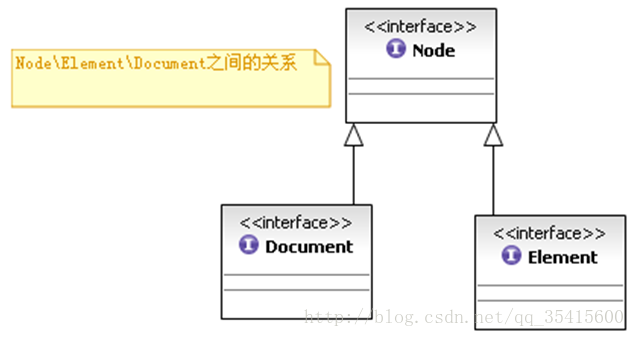
以上三個類之間的關係:
在DOM中,所有元素都是Node的子類:
DOM解析的具體實現方式:
準備XML資料:
users.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="A001">
<name>Jack</name>
<age>22</age>
</user>
<user id="A002">
<name>張三</name>
<age>21</age>
</user>
</users>建立Document物件的思路:
①首先直接找到Document類,在org.w3c.dom包中找到,我們可以看到Document是一個介面,因此需要找到此介面的具體實現類或者能夠返回出此型別的方法。
②因為w3c只是制定標準,具體類實現在sun公司的java包中,javax.xml.parsers。
③類 DocumentBuilderFactory構造方法是protected的,因此要找其中的static方法(newInstance() ),此方法返回此類型別,此時有了dbf物件。
④通過此物件dbf呼叫(newDocumentBuilder())得到DocumentBuilder類物件db。
⑤有了db物件,就可以呼叫此類(DocumentBuilder)中的parse(File f)方法就可以返回(Document)類物件dom。
建立Document物件程式碼實現:
第一步:建立工廠
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
第二步:建立解析器
DocumentBuilder db=dbf.newDocumentBuilder();
第三步:獲得dom物件
Document dom=db.parse("./xml/users.xml");
第四步:通過節點(Node)或者元素(Element)方式解析DOM樹
/....../(一)通過節點(Node)方法解析DOM樹:
第四步:首先獲取根節點
Node rootNode=dom.getFirstChild();
第五步:接著獲取此根節點的所有孩子節點
NodeList nodeList=rootNode.getChildNodes();
第六步:獲取<user>標籤的這個節點
Node userNode=nodeList.item(1);
第七步:獲取<user>節點下的<name>節點
Node nameNode=userNode.getChildNodes().item(1)
第八步:獲取此name節點的文字內容
String name=nameNode.getTextContent();(二)通過Document中的getElementsByTagName()方法解析DOM樹:
第四步:首先獲取根節點:
Node root=dom.getFirstChild();
第五步:將根節點強轉成Element元素型別
Element eroot=(Element) root;
第六步:通過標籤名獲取所有的此標籤節點
NodeList userList=eroot.getElementsByTagName("user");
第七步:將某一個標籤節點進行強轉
Element eUser1=(Element) userList.item(0);
第八步:再逐層通過標籤名獲得某個元素
NodeList nameList=eUser1.getElementsByTagName("name");
Node nameNode=nameList.item(0);
String name=nameNode.getTextContent();讀取節點中的屬性:
因為Node沒有獲取屬性的方式,所以必須將Node強制向下轉換成Element來處理。
使用:getAttribute(String name)來獲取。

獲取節點屬性程式碼實現:
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document dom=db.parse("./xml/users.xml/");
//將根節點強制轉換為元素型別
Node root=dom.getFirstChild();
Element eroot=(Element) root;
NodeList userList=eroot.getElementsByTagName("user");
Element eUser1=(Element) userList.item(0);
//獲取user節點中的屬性id
String id=eUser1.getAttribute("id");
System.out.println("id="+id);完整程式碼演示:
package cn.hncu.jaxp.dom;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 解析XML:
* 1、解析XML的方式:JAXP(DOM、StAX)、jDom(dom4j)
* 2、如何使用?
* JDK中有兩個專用於dom程式設計的包:
* (1)、org.w3c.dom -----w3c是制定標準,具體的實現還是看sun公司的javax.xml.parsers
* (2)、javax.xml.parsers -----sun公司具有開發出來解析的工具
*
*
* 入口方式:
* Document(來自org.w3c.dom)-->要用工廠方法獲得該dom物件-->工廠方法來自sun公司(javax.xml.parsers)
*
*
*/
public class DomDemo {
/*
* 獲取dom物件
*/
@Test
public void getDom() throws Exception{
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document dom=db.parse("./xml/users.xml");
System.out.println(dom);//[#document: null]
}
/*
* 通過節點的方式獲得name,age
*/
@Test
public void getName() throws Exception{
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document dom=db.parse("./xml/users.xml");
//獲得根節點
Node rootNode=dom.getFirstChild();
String rootNodeName=rootNode.getNodeName();
System.out.println("rootNodeName= "+rootNodeName);
/*
* 獲得根節點的所有孩子節點:包括空白符和標籤
* 【注意】:
* 1、通過Node中的getChildNodes(),返回型別為NodeList,獲取當前節點的所有子節點(包括文字內容和標籤節點)。
* 2、但是一般不選擇這種方式的理由:文字內容尤其是空白符也是其中的孩子節點,會產生干擾!
* 3、因此最好的方式就是:通過Element下的getElementByTagName(String name)
*/
NodeList nodeList=rootNode.getChildNodes();
for(int i=0;i<nodeList.getLength();i++){
System.out.println( nodeList.item(i).getNodeName());
}
//獲取第一個user節點下的name、age
Node userNode=nodeList.item(1);
String name=userNode.getChildNodes().item(1).getTextContent();
String age=userNode.getChildNodes().item(3).getTextContent();
System.out.println(name+","+age);
//獲取第二個user節點下的name、age
Node userNode2=nodeList.item(3);
String name2=userNode2.getChildNodes().item(1).getTextContent();
String age2=userNode2.getChildNodes().item(3).getTextContent();
System.out.println(name2+","+age2);
}
/*
* 建議採用的方式:用Element中的getElementsByTagName(String name)
* 為了使用使用Element中的方法必須將Node強轉成Element型別。
*/
@Test
public void getName2() throws Exception{
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document dom=db.parse("./xml/users.xml/");
//將根節點強制轉換為元素型別
Node root=dom.getFirstChild();
Element eroot=(Element) root;
NodeList userList=eroot.getElementsByTagName("user");
Element eUser1=(Element) userList.item(0);
//獲取user節點中的屬性id
String id=eUser1.getAttribute("id");
System.out.println("id="+id);
//獲取name
NodeList nameList=eUser1.getElementsByTagName("name");
Node nameNode=nameList.item(0);
String name=nameNode.getTextContent();
//獲取age
NodeList ageList=eUser1.getElementsByTagName("age");
Node ageNode=ageList.item(0);
String age=ageNode.getTextContent();
System.out.println(name+":"+age);
}
}
執行結果:
getName()執行結果:

getName2()執行結果: