
Spark(二)Spark安裝入門
目錄:
2、Spark安裝入門
2.1、Spark安裝部署
2.1.1、Spark下載:
下載地址:http://spark.apache.org/downloads.html

為了方便也可以進入到家目錄下使用命令下載:
[[email protected] ~]$ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.6.tgz
2.1.2、安裝前準備:
檔案解壓與改名:
[[email protected] ~]$ tar –zxvf spark-2.2.0-bin-hadoop2.6.tgz –C ./spark-2.2.0
2.1.3、配置環境變數:

2.1.4、配置Spark環境:
開啟spark-2.2.0資料夾:
[[email protected] spark-2.2.0]$ cd spark-2.2.0
此處需要配置的檔案為兩個:
spark-env.sh和slaves
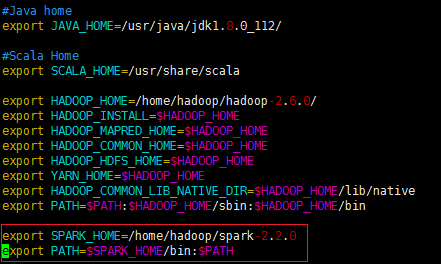
首先我們把快取的檔案spark-env.sh.template改為spark識別的檔案spark-env.sh
[[email protected] spark-2.2.0]$ cp conf/spark-env.sh.template conf /spark-env.sh
1、修改spark-env.sh檔案:
[[email protected] spark-2.2.0]$ vi conf/spark-env.sh
在末尾加上:

變數說明:
—JAVA_HOME:Java安裝目錄
—SCALA_HOME:Scale安裝目錄
—SPARK_MASTER_IP:spark叢集的Master節點的ip地址
—SPARK_WORKER_MEMORY:每個worker節點能夠最大分配給exectors的記憶體大小
2、修改slaves檔案:
[[email protected] spark-2.2.0]$ vi conf/slaves.template
由於是單機版,可直接在末尾加上localhost
![]()
2.1.5、啟動Spark叢集
1、啟動Hadoop的HDFS檔案系統:
start-dfs.sh
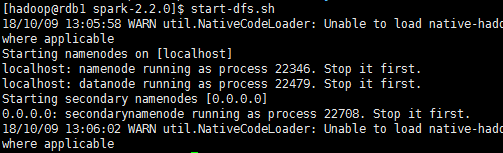
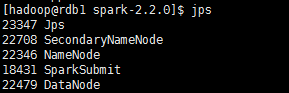
啟動之後使用jps命令可以檢視到rdb1已經啟動了namenode,說明Hadoop的HDFS檔案系統已經啟動了。
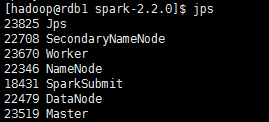
2、啟動Spark:
因為hadoop/sbin以及spark/sbin均配置到了系統的環境中,它們同一個資料夾下存在同樣的start-all.sh檔案。最好是開啟spark-2.2.0,在資料夾下面開啟該檔案。
./sbin/start-all.sh

成功開啟後使用jps在rdb1單節點上可以檢視新開啟的Master和Worker程序。
成功開啟Spark叢集之後可以進入Spark的WebUI介面,可以通過:SparkMaster_IP:8080訪問,
可見有一個正在執行的Worker節點。

3、開啟Spark-shell
使用spark-shell便可開啟Spark的shell。

成功開啟後,我們也可以通過SparkMaster_IP:4040訪問WebUI檢視當前執行的任務。

2.2、Spark中的Scale的shell
Spark帶有互動式的shell,可以作即時資料分析。Spark shell和其他的shell工具不一樣的是,在其他shell工具中你只能使用單機的硬碟和記憶體來操作資料,而Spark shell可用來與分散式儲存在許多機器的記憶體或者硬碟上的資料進行互動,並且處理過程的分發由Spark自動控制完成。
由於 Spark 能夠在工作節點上把資料讀取到記憶體中,所以許多分散式計算都可以在幾秒鐘之內完成,哪怕是那種在十幾個節點上處理 TB 級別的資料的計算。這就使得一般需要在shell 中完成的那些互動式的即時探索性分析變得非常適合 Spark。Spark 提供 Python 以及Scala 的增強版 shell,支援與叢集的連線。
開啟Scale版本的shell:bin/spark-shell。
在 Spark 中,我們通過對分散式資料集的操作來表達我們的計算意圖,這些計算會自動地在叢集上並行進行。這樣的資料集被稱為彈性分散式資料集(resilient distributed dataset),簡稱 RDD。RDD 是 Spark 對分散式資料和計算的基本抽象
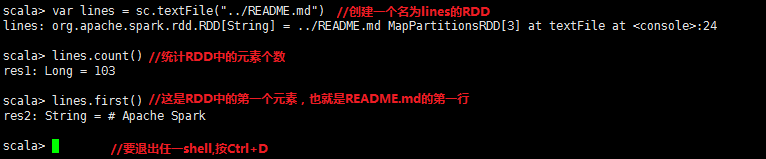
首先使用shell從本地檔案中建立一個RDD來做一些簡單的即時統計。
//Scale行數統計
2.3、Spark核心概念簡介
從上層來看,每個Spark應用都由一個驅動器程式(driver program)來發起叢集上的並行操作。驅動器程式包含應用的main函式,並且定義了叢集上的分散式資料集,還對這些資料集應用了相關操作。在前面的例子裡,實際的驅動器程式就是Spark shell本身,你只需要輸入想要執行的操作就可以了。
驅動器程式同一個SparkContext物件來訪問Spark。這個物件代表對計算叢集的連線。shell啟動時已經自動建立了一個SparkContext物件,是一個叫做sc的變數。
檢視變數sc:
![]()
一旦有了SparkContext,就可以用它來建立RDD。呼叫sc.textFile()來建立一個代表檔案中各行文字的RDD。我們可以在這些行上進行各種操作,比如count()。
要執行這些操作,驅動器程式一般要管理多個執行器(executor)節點。比如,我們要在叢集上執行count()操作,要麼不同的節點會統計檔案的不同部分的行數。由於我們剛才是在本地模式下執行Spark shell,因此所有的工作會在單節點上執行,但你可以將這個shell連線到叢集上來進行並行的資料分析。
spark如何在叢集上執行:

最後,我們有很多用來傳遞函式的API,可以將對應操作執行在叢集上。比如,可以擴充套件我們的README示例,篩選出檔案中包含某個特定單詞的行。以“Python”這個單詞為例,Scale版本例子如下:

Spark API最神奇的地方就在於像filter這樣基於函式的操作也會在叢集上並行執行。也就是說,Spark會自動將函式(比如line.contains(“Python”))發到各個執行器節點上。這樣就可以在單一的驅動器程式中程式設計,並且程式碼自動執行在多個節點上。
2.4、獨立應用
這與shell中使用的區別在於需要自行初始化SparkContext。
連線Spark過程在各語言中並不一樣。在Java和Scale中,只需要給你的應用新增一個對於spark-core的maven依賴。
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>2.2.0</version>
<scope>provided</scope>
</dependency>2.4.1、初始化SparkContext
一旦完成了應用與Spark的連線,接下來就需要在你的程式中匯入Spark包並且建立SparkContext。你可以通過先建立一個SparkConf物件來配置你的應用。然後基於這個SparkConf建立一個SparkContext物件。
在Java中初始化Spark:
SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“My App”);
JavaSparkContext sc = new JavaSparkContext(conf);
建立SparkContext只需要傳遞兩個引數:
叢集URL:告訴Spark如何連線到叢集上。
應用名:當連線到叢集時,這個值可以幫助我們在叢集管理器的使用者介面中找到我們的應用。
在初始化SparkContext之後,可以使用我們前面展示的所有方法(比如利用文字檔案)來建立RDD並操作它們。
最後,關閉Spark可以呼叫SparkContext的stop()方法,或者直接退出應用(比如System.exit(0))。
2.4.2、構建獨立應用
Java版本單詞數統計應用:
