
語音識別:CD-DNN-HMM訓練過程
阿新 • • 發佈:2019-01-04

[HMM對語音訊號的序列特性進行建模,DNN對所有聚類後的狀態(聚類後的三音素狀態)的似然度進行建模。對時間上的不同點採用同樣的DNN]
HMM三大問題:
通過訓練,得到三個引數:初始狀態概率分佈pai,隱含狀態序列的轉移矩陣A(就是某個狀態轉移到另一個狀態的概率觀察序列中的這個均值或者方差的概率)和某個隱含狀態下輸出觀察值的概率分佈B。
CD-DNN-HMM包含三個組成部分:dnn,hmm,一個狀態先驗概率分佈prior。
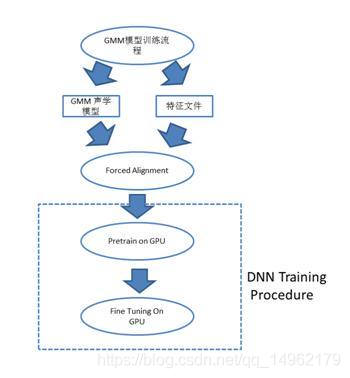
[DNN聲學模型訓練流程]
1.CD-DNN-HMM系統和GMM-HMM系統共享音素繫結結構(即Topo結構),訓練CD-DNN-HMM第一步是使用訓練資料訓練一個GMM-HMM系統作為初始化模型。
2.用訓練好的GMM-HMM模型hmm0建立一個從狀態名字到senoneID的對映,在訓練資料上採用維特比演算法生成一個狀態層面的強制對齊,利用stateTosenoneIDMap,把其中的狀態名轉變為senoneIDs。然後可以生成從特徵到senoneID的對映對(featuresenoneIDPairs)來訓練DNN。相同的featuresenoneIDPairs也被用來估計senone先驗概率。
訓練流程如下:
——訓練CD-DNN-HMM
——使用CD-DNN-HMM對訓練語料進行維特比解碼,強制對齊特徵和狀態。
——DNN訓練
dnn訓練的準則是基於後驗概率,而hmm訓練的準則是基於似然概率。