
Multi-View Gait Recognition Based on A Spatial-Temporal Deep Neural Network論文翻譯和理解
Multi-View Gait Recognition Based on A Spatial-Temporal Deep Neural Network論文翻譯和理解
翻譯格式:一句英文,一句中文
結合圖來講解
ABSTRACT
ABSTRACT This paper proposes a novel spatial-temporal deep neural network (STDNN) that is applied to multi-view gait recognition. STDNN comprises a temporal feature network (TFN) and a spatial feature network (SFN). In TFN, a feature sub-network is adopted to extract the low-level edge features of gait silhouettes. These features are input to the spatial-temporal gradient network (STGN) that adopts a spatial temporal gradient (STG) unit and long short-term memory (LSTM) unit to extract the spatial-temporal gradient features. In SFN, the spatial features of gait sequences are extracted by multilayer convolutional neural networks from a gait energy image (GEI). SFN is optimized by classification loss and verification loss jointly, which makes inter-class variations larger than intra-class variations. After training, TFN and SFN are employed to extract temporal and spatial features, respectively which are applied to multi-view gait recognition. Finally, the combined predicted probability is adopted to identify individuals by the differences in their gaits. To evaluate the performance of STDNN, extensive evaluations are carried out based on the CASIA-B, OU-ISIR and CMU MoBo datasets. The best recognition scores achieved by STDNN are 95.67% under an identical view, 93.64% under a cross-view and 92.54% under a multi-view. State-of-the-art approaches are compared with STDNN in various situations. The results show that STDNN outperforms the other methods and demonstrates the great potential of STDNN for practical applications in the future.
摘要
摘要-本文提出了一種應用於多視角步態識別的新型時空深度神經網路(STDNN)。STDNN包括時間特徵網路(TFN)和空間特徵網路(SFN)。在TFN中,採用特徵子網路來提取步態輪廓的區域性邊緣特徵,然後這些特徵被輸入到空間 - 時間梯度網路(STGN),其採用空間時間梯度(STG)單元和長短期記憶(LSTM)單元來提取空間 - 時間梯度特徵。在SFN中,步態序列的空間特徵由多層卷積神經網路從步態能量影象(GEI)提取。 SFN通過分類損失和驗證損失共同進行優化,這使得類間變化大於類內變化。經過訓練後,TFN和SFN用於提取時間和空間特徵,分別應用於多視角步態識別。最後,通過由每個個體的步態差異學習到的組合預測概率來識別個體。為了評估STDNN的效能,我們在資料集CASIA-B,OU-ISIR和CMU MoBo進行了充分的評估。在相同視角下,STDNN獲得的最佳識別率為95.67%,在交叉檢視下為93.64%,在多檢視下為92.54%。將現在領先的幾種方法與STDNN在不同條件下進行比較。結果表明,STDNN優於其他方法,並顯示了STDNN在未來實際應用中的巨大潛力。
先看總結構圖:
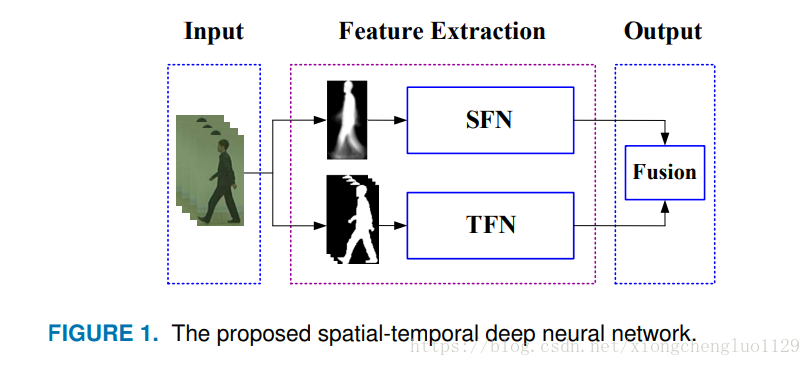
再細看看

看完了? 然後再分別來看 SFN和TFN
A. SPATIAL FEATURE NETWORK (SFN) —空間特徵網路
In this section, the proposed spatial feature network (SFN) is adopted to extract the spatial features of a gait sequence. Its working mechanism is as follows.
在這節當中,我們提出能從步態序列中提取空間特徵的空間特徵網路(SFN),它的工作原理如下:
1) Spatial Feature Extraction
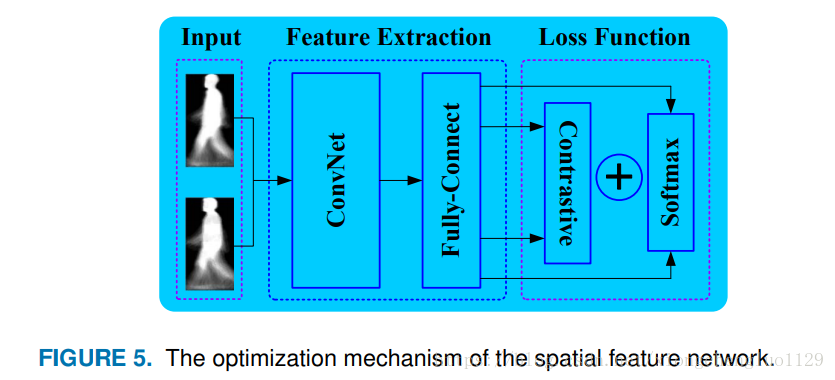
A spatial feature network comprises three parts, the input layer, the feature extraction network and the loss function layer. During the training phase, a pair of GEIs is input to the multi-layer convolutional neural networks in turn, which are adopted to extract the spatial features of a gait sequence. The last convolution layer which is connected to the fullyconnected layer, by which high dimensional feature vectors are generated. SFN is optimized based on two supervised signals, classification loss and verification loss.
空間特徵網路包括三個部分,輸入層,特徵提取網路和損失函式層。在訓練階段,依次將一對GEI輸入到多層卷積神經網路中,用來提取步態序列的空間特徵。最後一個卷積層後接一個全連線層,通過該層生成高維特徵向量。SFN基於兩個監督訊號對分類損失和驗證損失進行優化。
During the testing phase, the network optimized by the two loss functions is adopted to extract the spatial features, based on which the input GEIs pair is judged as to whether it belongs to the same subject or not. Many methods have recently been proposed to extract the effective spatial features based on convolution neural networks [24], [39].
在測試階段,用訓練好的網路來提取空間特徵,在此基礎上判斷輸入的一對GEI是否屬於同一個人。 最近提出了許多方法來提取基於卷積神經網路的有效空間特徵[24],[39]。
To extract the effective spatial features of a gait sequence, a ConvNet with four convolutional layers is designed as the base network model of the spatial feature network. Furthermore, two other kinds of CNN-based networks are selected to compare with SFN on gait recognition accuracy, which is discussed in detail in section V.C.
空間特徵網路的基礎網路模型是具有四個卷積層的ConvNet,這樣設計是為了提取步態序列的有效空間特徵。 此外,選擇另外兩種基於CNN的網路來與的SFN進行步態識別精度比較(這裡僅僅是比較他們兩個所提取空間特徵哪個更有效),這將在 V.C. 部分中詳細討論。
The process of gait spatial feature extraction comprises three parts. In the data preparation phase, GEIs are generated using the method described in section III.C. Then, the sample pair is sent to ConvNet in turn, which is adopted to extract high dimensional feature vectors. These vectors output by ConvNet are capable of representing the spatial features of the input samples, based on which softmax layer is used to predict the categories of the input samples.
步態空間特徵提取的過程包括三個部分:在資料準備階段,使用第 III.C 部分中描述的方法生成GEI。然後,將樣本對依次送入到ConvNet,用於提取高維特徵向量。 ConvNet輸出的這些向量能夠表示輸入樣本的空間特徵,softmax層基於這些向量來預測輸入樣本的類別。
GEI is a kind of small sample due to little information,which is a barrier in identifying different subjects by solely applying the aforementioned method. Inspired by the promising performance of the method proposed in [40], an additional verification signal is adopted, which not only enlarges inter-class variations but also reduces intra-class variations. The two supervisory signals are implemented using two kinds of loss functions which work together to compel SFN to focus on the identity-related feature itself, rather than other influential factors, such as wearing noise, illuminations and so on. The working mechanism of SFN is shown in Figure 5.
由於GEI所攜帶的資訊很少,僅僅應用上述方法來識別不同人的身份效果不佳。 受到[40]中提出的一種比較有前景的方法的啟發,我們採用了額外的驗證資訊,這種驗證資訊不僅能擴大類間變化而且還可以減少了類內變化。 這兩個監控訊號是由兩種損失函式實現的,由兩種損失函式共同作用來迫使SFN專注於身份相關的特徵本身,而不是其他影響因素,如佩戴物,噪聲,照明等。 SFN的工作機制如圖5所示。
The first supervisory signal is verification loss, which is adopted to reduce the intra-class variation of gait samples.
第一個監控訊號是驗證損失,用於減少步態樣本的類內變化。(好強的監督資訊)
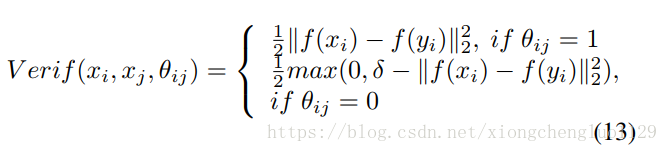
Based on the L2 norm [41], verification loss is defined in Equation (13) where and denote two input GEIs, and and denote the feature vectors output by the fully connected layer . When = 1 this means that and are from the same gait individual, and features and are enforced to be close. On the contrary, when =0 this means that and are from different persons. In this case, the features and are pushed apart. The size of the margin is denoted as , which is smaller than the distance between the features carried by different subjects.
基於L2範數[41]的驗證損失在等式(13)中定義,其中 和 表示兩個輸入GEI, 和 表示由完全連線的層Fc6輸出的特徵向量。當 = 1時,這意味著 和 是同一個人的步態能量圖,並且特徵 和 的差異會在訓練過程中逐步變小。 相反,當 = 0時,這表示 和 是不同人的步態能量圖。 在這種情況下,特徵 和 在訓練過程中差異會變大。 表示邊界的大小,其小於不同主體產生的特徵之間的距離。這裡說的就是對比損失函式的定義。
方程(15)中
的分母中
的下標
應該改為
,
= 後求和符號的起始下標應該為
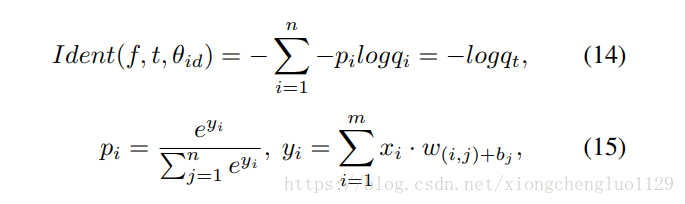
The second supervisory signal is classification loss. After being optimized by this supervisory signal, SFN is adopted to identify different subjects. This loss function is defined in Equation (14)-(15) where denotes the spatial feature vector, pi denotes the target probability distribution, when = 0 for all except = 1 for the target class . and denotes the predicted probability that the input sample belongs to a specific class. The output of the softmax layer is the probability distribution of the input samples. denotes the dimensions of the feature output by the fully-connected layer, is the input feature image, and