
spring boot 學習筆記 (9) Spring Data JPA
Spring Data JPA 是 Spring Boot 體系中約定優於配置的最佳實現,大大簡化了專案中資料庫的操作
JPA 是什麼
JPA(Java Persistence API)是 Sun 官方提出的 Java 持久化規範。它為 Java 開發人員提供了一種物件 / 關聯對映工具來管理 Java 應用中的關係資料。它的出現主要是為了簡化現有的持久化開發工作和整合 ORM 技術,結束現在 Hibernate、TopLink、JDO 等 ORM 框架各自為營的局面。
值得注意的是,JPA 是在充分吸收了現有的 Hibernate、TopLink、JDO 等 ORM 框架的基礎上發展而來的,具有易於使用、伸縮性強等優點。從目前的開發社群的反應上看,JPA 受到了極大的支援和讚揚,其中就包括了 Spring 與 EJB 3.0 的開發團隊。
注意:JPA 是一套規範,不是一套產品,那麼像 Hibernate、TopLink、JDO 它們是一套產品,如果說這些產品實現了這個 JPA 規範,那麼我們就可以稱他們為 JPA 的實現產品。
Spring Data JPA
Spring Data JPA 是 Spring 基於 ORM 框架、JPA 規範的基礎上封裝的一套 JPA 應用框架,可以讓開發者用極簡的程式碼即可實現對資料的訪問和操作。它提供了包括增、刪、改、查等在內的常用功能,且易於擴充套件,學習並使用 Spring Data JPA 可以極大提高開發效率。Spring Data JPA 其實就是 Spring 基於 Hibernate 之上構建的 JPA 使用解決方案,方便在 Spring Boot 專案中使用 JPA 技術。
Spring Data JPA 讓我們解脫了 DAO 層的操作,基本上所有 CRUD 都可以依賴於它實現。
快速上手
新增依賴
<dependency> <groupId>org.Springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency>
新增配置檔案
spring.datasource.url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
#SQL 輸出
spring.jpa.show-sql=true
#format 一下 SQL 進行輸出
spring.jpa.properties.hibernate.format_sql=true
hibernate.hbm2ddl.auto 引數的作用主要用於:自動建立、更新、驗證資料庫表結構,有四個值。
- create:每次載入 Hibernate 時都會刪除上一次生成的表,然後根據 model 類再重新來生成新表,哪怕兩次沒有任何改變也要這樣執行,這就是導致資料庫表資料丟失的一個重要原因。
- create-drop:每次載入 Hibernate 時根據 model 類生成表,但是 sessionFactory 一關閉,表就自動刪除。
- update:最常用的屬性,第一次載入 Hibernate 時根據 model 類會自動建立起表的結構(前提是先建立好資料庫),以後載入 Hibernate 時根據 model 類自動更新表結構,即使表結構改變了,但表中的行仍然存在,不會刪除以前的行。要注意的是當部署到伺服器後,表結構是不會被馬上建立起來的,是要等應用第一次執行起來後才會。
- validate :每次載入 Hibernate 時,驗證建立資料庫表結構,只會和資料庫中的表進行比較,不會建立新表,但是會插入新值。
其中:
- dialect 主要是指定生成表名的儲存引擎為 InneoDB
- show-sql 是否在日誌中打印出自動生成的 SQL,方便除錯的時候檢視
實體類
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false, unique = true)
private String userName;
@Column(nullable = false)
private String passWord;
@Column(nullable = false, unique = true)
private String email;
@Column(nullable = true, unique = true)
private String nickName;
@Column(nullable = false)
private String regTime;
//省略 getter settet 方法、構造方法
}
下面對上面用的註解做一個解釋。
@Entity(name="EntityName")必須,用來標註一個數據庫對應的實體,資料庫中建立的表名預設和類名一致。其中,name 為可選,對應資料庫中一個表,使用此註解標記 Pojo 是一個 JPA 實體。@Table(name="",catalog="",schema="")可選,用來標註一個數據庫對應的實體,資料庫中建立的表名預設和類名一致。通常和 @Entity 配合使用,只能標註在實體的 class 定義處,表示實體對應的資料庫表的資訊。@Id必須,@Id 定義了對映到資料庫表的主鍵的屬性,一個實體只能有一個屬性被對映為主鍵。@GeneratedValue(strategy=GenerationType,generator="")可選,strategy: 表示主鍵生成策略,有 AUTO、INDENTITY、SEQUENCE 和 TABLE 4 種,分別表示讓 ORM 框架自動選擇,generator: 表示主鍵生成器的名稱。@Column(name = "user_code", nullable = false, length=32)可選,@Column 描述了資料庫表中該欄位的詳細定義,這對於根據 JPA 註解生成資料庫表結構的工具。name: 表示資料庫表中該欄位的名稱,預設情形屬性名稱一致;nullable: 表示該欄位是否允許為 null,預設為 true;unique: 表示該欄位是否是唯一標識,預設為 false;length: 表示該欄位的大小,僅對 String 型別的欄位有效。@Transient可選,@Transient 表示該屬性並非一個到資料庫表的欄位的對映,ORM 框架將忽略該屬性。@Enumerated可選,使用列舉的時候,我們希望資料庫中儲存的是列舉對應的 String 型別,而不是列舉的索引值,需要在屬性上面新增 @Enumerated(EnumType.STRING) 註解。
Repository 構建
建立的 Repository 只要繼承 JpaRepository 即可,就會幫我們自動生成很多內建方法。另外還有一個功能非常實用,可以根據方法名自動生產 SQL,比如 findByUserName 會自動生產一個以 userName 為引數的查詢方法,比如 findAll 會自動查詢表裡面的所有資料等。
public interface UserRepository extends JpaRepository<User, Long> {
User findByUserName(String userName);
User findByUserNameOrEmail(String username,String email);
}
我們只需要在對應的 Repository 中建立好方法,使用的時候直接將介面注入到類中呼叫即可。在 IDEA 中開啟類 UserRepository,在這個類的大括號內的區域右鍵單擊,選擇 Diagrams | Show Diagram 選項,即可開啟類圖,如下:
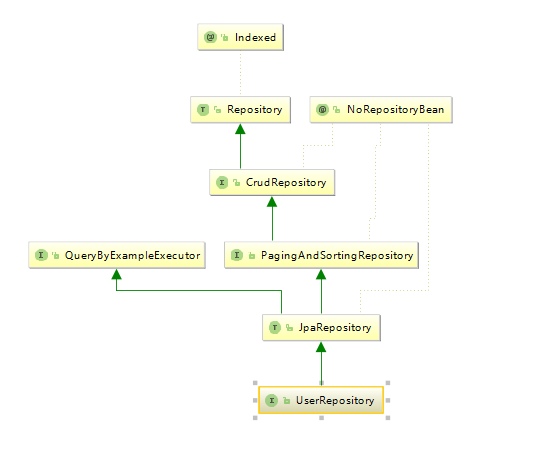
通過上圖我們發現 JpaRepository 繼承 PagingAndSortingRepository 和 QueryByExampleExecutor,PagingAndSortingRepository 類主要負責排序和分頁內容,QueryByExampleExecutor 提供了很多示例的查詢方法,如下:
public interface QueryByExampleExecutor<T> {
<S extends T> S findOne(Example<S> example); //根據“例項”查詢一個物件
<S extends T> Iterable<S> findAll(Example<S> example); //根據“例項”查詢一批物件
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort); //根據“例項”查詢一批物件,且排序
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable); //根據“例項”查詢一批物件,且排序和分頁
<S extends T> long count(Example<S> example); //根據“例項”查詢,返回符合條件的物件個數
<S extends T> boolean exists(Example<S> example); //根據“例項”判斷是否有符合條件的物件
}
因此,繼承 JpaRepository 的會自動擁有上述這些方法和排序、分頁功能。檢視原始碼我們發現 PagingAndSortingRepository 又繼承了 CrudRepository。CrudRepository 的原始碼如下:
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
從 CrudRepository 的原始碼可以看出 CrudRepository 內建了我們最常用的增、刪、改、查的方法,方便我們去使用,因為 JpaRepository 繼承了 PagingAndSortingRepository,PagingAndSortingRepository 繼承了 CrudRepository,所以繼承 JpaRepository 的類也預設擁有了上述方法。
因此使用 JPA 操作資料庫時,只需要構建的 Repository 繼承了 JpaRepository,就會擁有了很多常用的資料庫操作方法。
測試
建立好 UserRepository 之後,當業務程式碼中需要使用時直接將此介面注入到對應的類中,在 Spring Boot 啟動時,會自動根據註解內容建立實現類並注入到目標類中。
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserRepositoryTests {
@Resource
private UserRepository userRepository;
@Test
public void test() {
Date date = new Date();
DateFormat dateFormat = DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG);
String formattedDate = dateFormat.format(date);
userRepository.save(new User("aa", "[email protected]", "aa", "aa123456",formattedDate));
userRepository.save(new User("bb", "[email protected]", "bb", "bb123456",formattedDate));
userRepository.save(new User("cc", "[email protected]", "cc", "cc123456",formattedDate));
Assert.assertEquals(9, userRepository.findAll().size());
Assert.assertEquals("bb", userRepository.findByUserNameOrEmail("bb", "[email protected]").getNickName());
userRepository.delete(userRepository.findByUserName("aa1"));
}
}
上述測試方法簡單測試了 JPA 的報錯和查詢功能,測試用例執行成功表示 JPA 的增、刪、改成功。
基本查詢
我們可以將 Spring Data JPA 查詢分為兩種,一種是 Spring Data JPA 預設實現的,另一種是需要根據查詢的情況來自行構建。
預生成方法
預生成方法就是我們上面看到的那些方法,因為繼承了 JpaRepository 而擁有了父類的這些內容。
(1)繼承 JpaRepository
public interface UserRepository extends JpaRepository<User, Long> {
}
(2)使用預設方法
@Test
public void testBaseQuery() {
userRepository.findAll();
userRepository.findById(1l);
userRepository.save(user);
userRepository.delete(user);
userRepository.count();
userRepository.existsById(1l);
// ...
}
所有父類擁有的方法都可以直接呼叫,根據方法名也可以看出它的含義。
自定義查詢
Spring Data JPA 可以根據介面方法名來實現資料庫操作,主要的語法是 findXXBy、readAXXBy、queryXXBy、countXXBy、getXXBy 後面跟屬性名稱,利用這個功能僅需要在定義的 Repository 中新增對應的方法名即可,使用時 Spring Boot 會自動幫我們實現,示例如下。
根據使用者名稱查詢使用者:
User findByUserName(String userName);
也可以加一些關鍵字 And、or:
User findByUserNameOrEmail(String username, String email);
修改、刪除、統計也是類似語法:
Long deleteById(Long id);
Long countByUserName(String userName)
基本上 SQL 體系中的關鍵詞都可以使用,如 LIKE 、IgnoreCase、OrderBy:
List<User> findByEmailLike(String email);
User findByUserNameIgnoreCase(String userName);
List<User> findByUserNameOrderByEmailDesc(String email);
可以根據查詢的條件不斷地新增和拼接,Spring Boot 都可以正確解析和執行,其他使用示例可以參考下表。
具體的關鍵字,使用方法和生產成 SQL 如下表所示
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<Age> ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<Age> age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
自定義 SQL 查詢
使用 Spring Data 大部分的 SQL 都可以根據方法名定義的方式來實現,但是由於某些原因必須使用自定義的 SQL 來查詢,Spring Data 也可以完美支援。
在 SQL 的查詢方法上面使用 @Query 註解,在註解內寫 Hql 來查詢內容。
@Query("select u from User u")
Page<User> findALL(Pageable pageable);
當然如果感覺使用原生 SQL 更習慣,它也是支援的,需要再新增一個引數 nativeQuery = true。
@Query("select * from user u where u.nick_name = ?1", nativeQuery = true)
Page<User> findByNickName(String nickName, Pageable pageable);
@Query 上面的 1 代表的是方法引數裡面的順序,如果有多個引數也可以按照這個方式新增 1、2、3....。除了按照這種方式傳參外,還可以使用 @Param 來支援。
@Query("select u from User u where u.nickName = :nickName")
Page<User> findByNickName(@Param("nickName") String nickName, Pageable pageable);
如涉及到刪除和修改需要加上 @Modifying,也可以根據需要新增 @Transactional 對事務的支援、操作超時設定等。
@Transactional(timeout = 10)
@Modifying
@Query("update User set userName = ?1 where id = ?2")
int modifyById(String userName, Long id);
@Transactional
@Modifying
@Query("delete from User where id = ?1")
void deleteById(Long id);
使用已命名的查詢
除了使用 @Query 註解外,還可以預先定義好一些查詢,併為其命名,然後再 Repository 中新增相同命名的方法。
定義命名的 Query:
@Entity
@NamedQueries({
@NamedQuery(name = "User.findByPassWord", query = "select u from User u where u.passWord = ?1"),
@NamedQuery(name = "User.findByNickName", query = "select u from User u where u.nickName = ?1"),
})
public class User {
……
}
通過 @NamedQueries 註解可以定義多個命名 Query,@NamedQuery 的 name 屬性定義了 Query 的名稱,注意加上 Entity 名稱 . 作為字首,query 屬性定義查詢語句。
定義對應的方法:
List<User> findByPassWord(String passWord);
List<User> findByNickName(String nickName);
Query 查詢策略
到此,我們有了三種方法來定義 Query:(1)通過方法名自動建立 Query,(2)通過 @Query 註解實現自定義 Query,(3)通過 @NamedQuery 註解來定義 Query。那麼,Spring Data JPA 如何來查詢這些 Query 呢?
通過配置 @EnableJpaRepositories 的 queryLookupStrategy 屬性來配置 Query 查詢策略,有如下定義。
- CREATE:嘗試從查詢方法名構造特定於儲存的查詢。一般的方法是從方法名中刪除一組已知的字首,並解析方法的其餘部分。
- USE_DECLARED_QUERY:嘗試查詢已宣告的查詢,如果找不到,則丟擲異常。查詢可以通過某個地方的註釋定義,也可以通過其他方式宣告。
- CREATE_IF_NOT_FOUND(預設):CREATE 和 USE_DECLARED_QUERY 的組合,它首先查詢一個已宣告的查詢,如果沒有找到已宣告的查詢,它將建立一個自定義方法基於名稱的查詢。它允許通過方法名進行快速查詢定義,還可以根據需要引入宣告的查詢來定製這些查詢調優。
一般情況下使用預設配置即可,如果確定專案 Query 的具體定義方式,可以更改上述配置,例如,全部使用 @Query 來定義查詢,又或者全部使用命名的查詢。
分頁查詢
Spring Data JPA 已經幫我們內建了分頁功能,在查詢的方法中,需要傳入引數 Pageable,當查詢中有多個引數的時候 Pageable 建議作為最後一個引數傳入。
@Query("select u from User u")
Page<User> findALL(Pageable pageable);
Page<User> findByNickName(String nickName, Pageable pageable);
Pageable 是 Spring 封裝的分頁實現類,使用的時候需要傳入頁數、每頁條數和排序規則,Page 是 Spring 封裝的分頁物件,封裝了總頁數、分頁資料等。返回物件除使用 Page 外,還可以使用 Slice 作為返回值。
Slice<User> findByNickNameAndEmail(String nickName, String email,Pageable pageable);
Page 和 Slice 的區別如下。
- Page 介面繼承自 Slice 介面,而 Slice 繼承自 Iterable 介面。
- Page 介面擴充套件了 Slice 介面,添加了獲取總頁數和元素總數量的方法,因此,返回 Page 介面時,必須執行兩條 SQL,一條複雜查詢分頁資料,另一條負責統計資料數量。
- 返回 Slice 結果時,查詢的 SQL 只會有查詢分頁資料這一條,不統計資料數量。
- 用途不一樣:Slice 不需要知道總頁數、總資料量,只需要知道是否有下一頁、上一頁,是否是首頁、尾頁等,比如前端滑動載入一頁可用;而 Page 知道總頁數、總資料量,可以用於展示具體的頁數資訊,比如後臺分頁查詢。
@Test
public void testPageQuery() {
int page=1,size=2;
Sort sort = new Sort(Sort.Direction.DESC, "id");
Pageable pageable = PageRequest.of(page, size, sort);
userRepository.findALL(pageable);
userRepository.findByNickName("aa", pageable);
}
- Sort,控制分頁資料的排序,可以選擇升序和降序。
- PageRequest,控制分頁的輔助類,可以設定頁碼、每頁的資料條數、排序等。
還有一些更簡潔的方式來排序和分頁查詢,如下。
限制查詢
有時候我們只需要查詢前 N 個元素,或者只取前一個實體。
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);
複雜查詢
我們可以通過 AND 或者 OR 等連線詞來不斷拼接屬性來構建多條件查詢,但如果引數大於 6 個時,方法名就會變得非常的長,並且還不能解決動態多條件查詢的場景。到這裡就需要給大家介紹另外一個利器 JpaSpecificationExecutor 了。
JpaSpecificationExecutor 是 JPA 2.0 提供的 Criteria API 的使用封裝,可以用於動態生成 Query 來滿足我們業務中的各種複雜場景。Spring Data JPA 為我們提供了 JpaSpecificationExecutor 介面,只要簡單實現 toPredicate 方法就可以實現複雜的查詢。
我們來看一下 JpaSpecificationExecutor 的原始碼:
public interface JpaSpecificationExecutor<T> {
//根據 Specification 條件查詢單個物件,注意的是,如果條件能查出來多個會報錯
T findOne(@Nullable Specification<T> spec);
//根據 Specification 條件查詢 List 結果
List<T> findAll(@Nullable Specification<T> spec);
//根據 Specification 條件,分頁查詢
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
//根據 Specification 條件,帶排序的查詢結果
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
//根據 Specification 條件,查詢數量
long count(@Nullable Specification<T> spec);
}
JpaSpecificationExecutor 的原始碼很簡單,根據 Specification 的查詢條件返回 List、Page 或者 count 資料。在使用 JpaSpecificationExecutor 構建複雜查詢場景之前,我們需要了解幾個概念:
- Root
<T>root,代表了可以查詢和操作的實體物件的根,開一個通過 get("屬性名") 來獲取對應的值。 - CriteriaQuery<?> query,代表一個 specific 的頂層查詢物件,它包含著查詢的各個部分,比如 select 、from、where、group by、order by 等。
- CriteriaBuilder cb,來構建 CritiaQuery 的構建器物件,其實就相當於條件或者是條件組合,並以 Predicate 的形式返回。
使用案例
下面的使用案例中會報錯這幾個物件的使用。
首先定義一個 UserDetail 物件,作為演示的資料模型。
@Entity
public class UserDetail {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false, unique = true)
private Long userId;
private Integer age;
private String realName;
private String status;
private String hobby;
private String introduction;
private String lastLoginIp;
}
建立 UserDetail 對應的 Repository:
public interface UserDetailRepository extends JpaSpecificationExecutor<UserDetail>,JpaRepository<UserDetail, Long> {
}
定義一個查詢 Page<UserDetail> 的介面:
public interface UserDetailService {
public Page<UserDetail> findByCondition(UserDetailParam detailParam, Pageable pageable);
}
在 UserDetailServiceImpl 中,我們來演示 JpaSpecificationExecutor 的具體使用。
@Service
public class UserDetailServiceImpl implements UserDetailService{
@Resource
private UserDetailRepository userDetailRepository;
@Override
public Page<UserDetail> findByCondition(UserDetailParam detailParam, Pageable pageable){
return userDetailRepository.findAll((root, query, cb) -> {
List<Predicate> predicates = new ArrayList<Predicate>();
//equal 示例
if (!StringUtils.isNullOrEmpty(detailParam.getIntroduction())){
predicates.add(cb.equal(root.get("introduction"),detailParam.getIntroduction()));
}
//like 示例
if (!StringUtils.isNullOrEmpty(detailParam.getRealName())){
predicates.add(cb.like(root.get("realName"),"%"+detailParam.getRealName()+"%"));
}
//between 示例
if (detailParam.getMinAge()!=null && detailParam.getMaxAge()!=null) {
Predicate agePredicate = cb.between(root.get("age"), detailParam.getMinAge(), detailParam.getMaxAge());
predicates.add(agePredicate);
}
//greaterThan 大於等於示例
if (detailParam.getMinAge()!=null){
predicates.add(cb.greaterThan(root.get("age"),detailParam.getMinAge()));
}
return query.where(predicates.toArray(new Predicate[predicates.size()])).getRestriction();
}, pageable);
}
}
上面的示例是根據不同條件來動態查詢 UserDetail 分頁資料,UserDetailParam 是引數的封裝,示例中使用了常用的大於、like、等於等示例,根據這個思路我們可以不斷擴充套件完成更復雜的動態 SQL 查詢。
使用時只需要將 UserDetailService 注入呼叫相關方法即可:
@RunWith(SpringRunner.class)
@SpringBootTest
public class JpaSpecificationTests {
@Resource
private UserDetailService userDetailService;
@Test
public void testFindByCondition() {
int page=0,size=10;
Sort sort = new Sort(Sort.Direction.DESC, "id");
Pageable pageable = PageRequest.of(page, size, sort);
UserDetailParam param=new UserDetailParam();
param.setIntroduction("程式設計師");
param.setMinAge(10);
param.setMaxAge(30);
Page<UserDetail> page1=userDetailService.findByCondition(param,pageable);
for (UserDetail userDetail:page1){
System.out.println("userDetail: "+userDetail.toString());
}
}
}
多表查詢
多表查詢在 Spring Data JPA 中有兩種實現方式,第一種是利用 Hibernate 的級聯查詢來實現,第二種是建立一個結果集的介面來接收連表查詢後的結果,這裡主要介紹第二種方式。
我們還是使用上面的 UserDetail 作為資料模型來使用,定義一個結果集的介面類,介面類的內容來自於使用者表和使用者詳情表。
public interface UserInfo {
String getUserName();
String getEmail();
String getAddress();
String getHobby();
}
在執行中 Spring 會給介面(UserInfo)自動生產一個代理類來接收返回的結果,程式碼中使用 getXX 的形式來獲取。
在 UserDetailRepository 中新增查詢的方法,返回型別設定為 UserInfo:
@Query("select u.userName as userName, u.email as email, d.introduction as introduction , d.hobby as hobby from User u , UserDetail d " +
"where u.id=d.userId and d.hobby = ?1 ")
List<UserInfo> findUserInfo(String hobby);
特別注意這裡的 SQL 是 HQL,需要寫類的名和屬性,這塊很容易出錯。
測試驗證:
@Test
public void testUserInfo() {
List<UserInfo> userInfos=userDetailRepository.findUserInfo("釣魚");
for (UserInfo userInfo:userInfos){
System.out.println("userInfo: "+userInfo.getUserName()+"-"+userInfo.getEmail()+"-"+userInfo.getHobby()+"-"+userInfo.getIntroduction());
}
}
執行測試方法後返回:
userInfo: [email protected]釣魚-程式設計師
證明關聯查詢成功,最後的返回結果來自於兩個表,按照這個思路可以進行三個或者更多表的關聯查詢。
多資料來源的使用
專案中使用多個數據源在以往工作中比較常見,微服務架構中不建議一個專案使用多個數據源。在微服務架構下,一個微服務擁有自己獨立的一個數據庫,如果此微服務要使用其他資料庫的資料,需要呼叫對應庫的微服務介面來呼叫,而不是在一個專案中連線使用多個數據庫,這樣微服務更獨立、更容易水平擴充套件。
雖然在微服務架構下,不提倡一個專案擁有多個數據源,但在 Spring Boot 體系中,專案實現多資料來源呼叫卻是一件很容易的事情
總結
Spring Data JPA 使用動態注入的原理,根據方法名動態生成方法的實現,因此根據方法名實現資料查詢,即可滿足日常絕大部分使用場景。除了這種查詢方式之外,Spring Data JPA 還支援多種自定義查詢來滿足更多複雜場景的使用,兩種方式相結合可以靈活滿足專案對 Orm 層的需求。
通過學習 Spring Data JPA 也可以看出 Spring Boot 的設計思想,80% 的需求通過預設、簡單的方式實現,滿足大部分使用場景,對於另外 20% 複雜的場景,提供另外的技術手段來解決。Spring Data JPA 中根據方法名動態實現 SQL,元件環境自動配置等細節,都是將 Spring Boot 約定優於配置的思想體現的淋淋盡致。