
Spark Java版 windows本地開發環境
阿新 • • 發佈:2019-01-04
安裝IntelliJ IDEA
選擇Community版本安裝
安裝好後啟動,我這裡選擇UI主題
預設Plugins.
安裝scala外掛.
配置hadoop環境變數
下載winutils.exe
我這裡面選擇hadoop2.7.1版本
在D盤新建檔案D:\hadoop-2.7.1\bin\winutils.exe配置windows環境變數
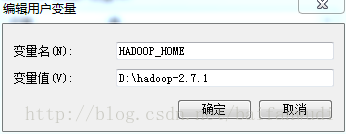
使用者變數:
新增HADOOP_HOME=D:\hadoop-2.7.1
系統變數:
Path新增%HADOOP_HOME%\bin
新建maven專案
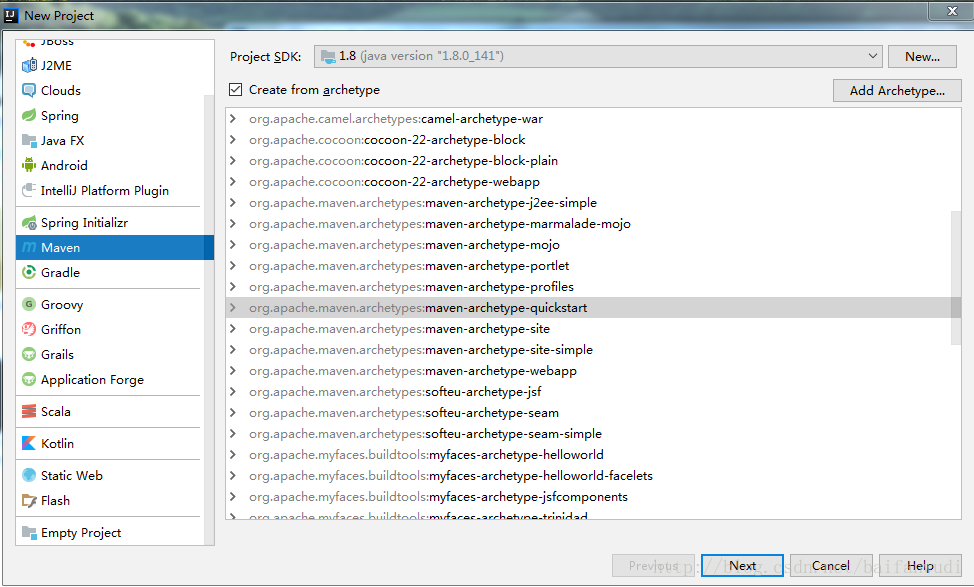
<project 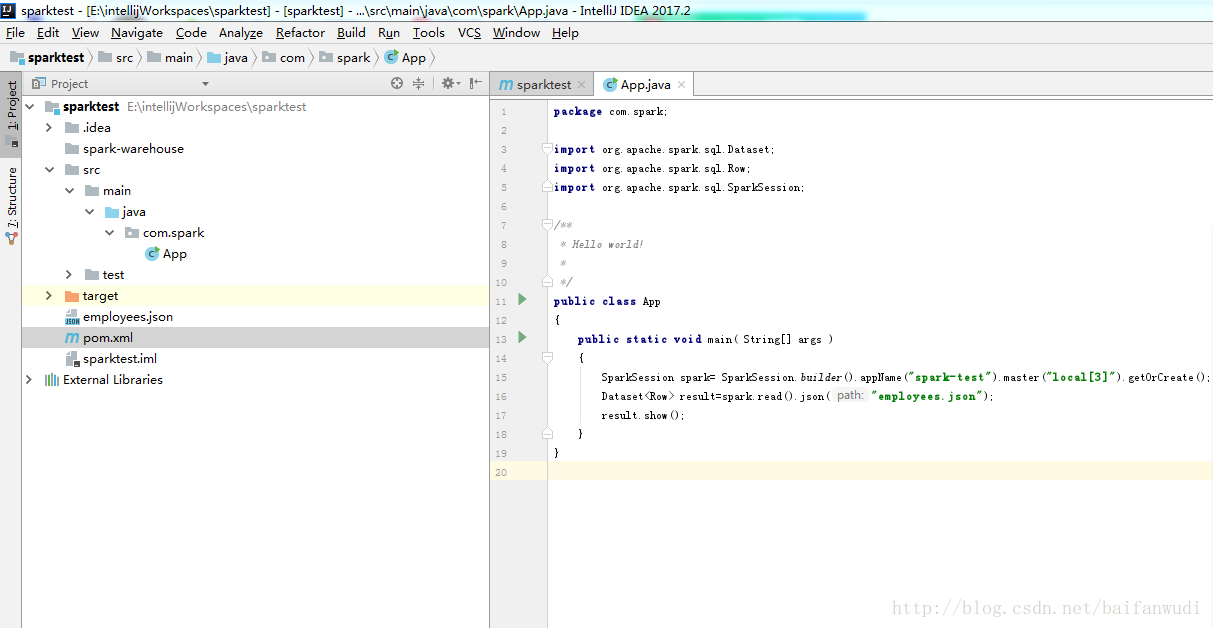
測試程式碼
package com.spark;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
SparkSession spark= SparkSession.builder().appName("spark-test").master("local[3]").getOrCreate();
Dataset<Row> result=spark.read().json("employees.json");
result.show();
result.printSchema();
spark.stop();
}
}
執行結果
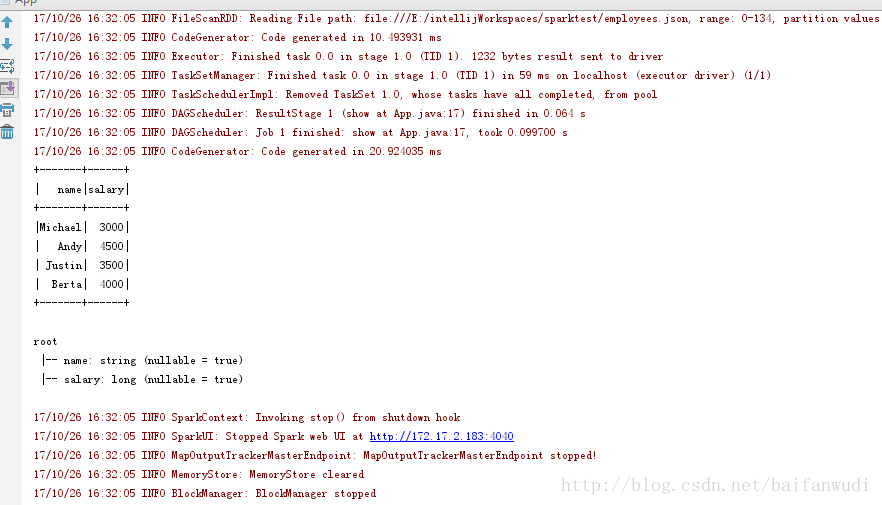
完成!