
特徵提取方法 one-hot和TF-IDF
one-hot 和 TF-IDF是目前最為常見的用於提取文字特徵的方法,本文主要介紹兩種方法的思想以及優缺點。
1. one-hot
1.1 one-hot編碼
什麼是one-hot編碼?one-hot編碼,又稱獨熱編碼、一位有效編碼。其方法是使用N位狀態暫存器來對N個狀態進行編碼,每個狀態都有它獨立的暫存器位,並且在任意時候,其中只有一位有效。舉個例子,假設我們有四個樣本(行),每個樣本有三個特徵(列),如圖:
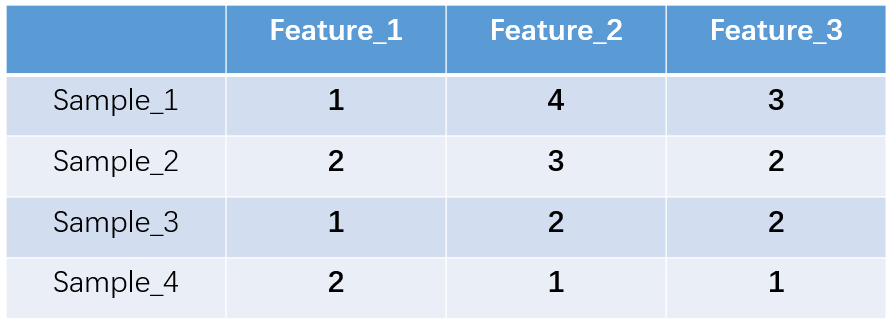
上圖中我們已經對每個特徵進行了普通的數字編碼:我們的feature_1有兩種可能的取值,比如是男/女,這裡男用1表示,女用2表示。那麼one-hot編碼是怎麼搞的呢?我們再拿feature_2來說明:
這裡feature_2 有4種取值(狀態),我們就用4個狀態位來表示這個特徵,one-hot編碼就是保證每個樣本中的單個特徵只有1位處於狀態1,其他的都是0。

對於2種狀態、三種狀態、甚至更多狀態都是這樣表示,所以我們可以得到這些樣本特徵的新表示:
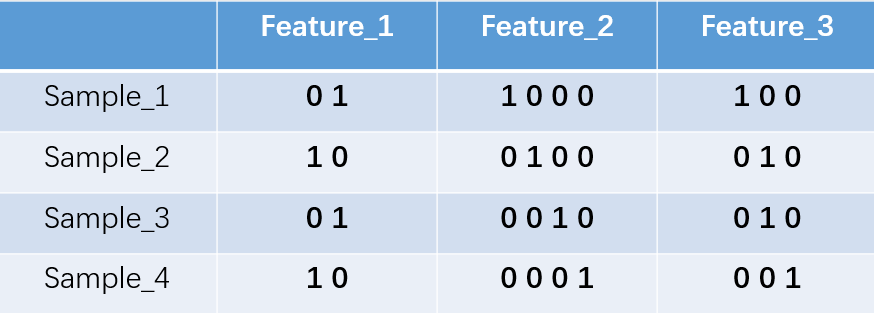
one-hot編碼將每個狀態位都看成一個特徵。對於前兩個樣本我們可以得到它的特徵向量分別為

1.2 one-hot在提取文字特徵上的應用
one hot在特徵提取上屬於詞袋模型(bag of words)。關於如何使用one-hot抽取文字特徵向量我們通過以下例子來說明。假設我們的語料庫中有三段話:
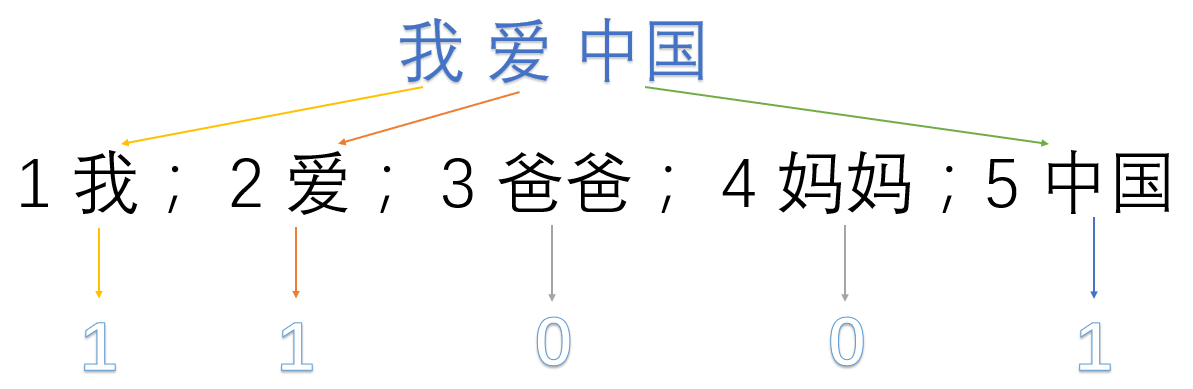
我愛中國
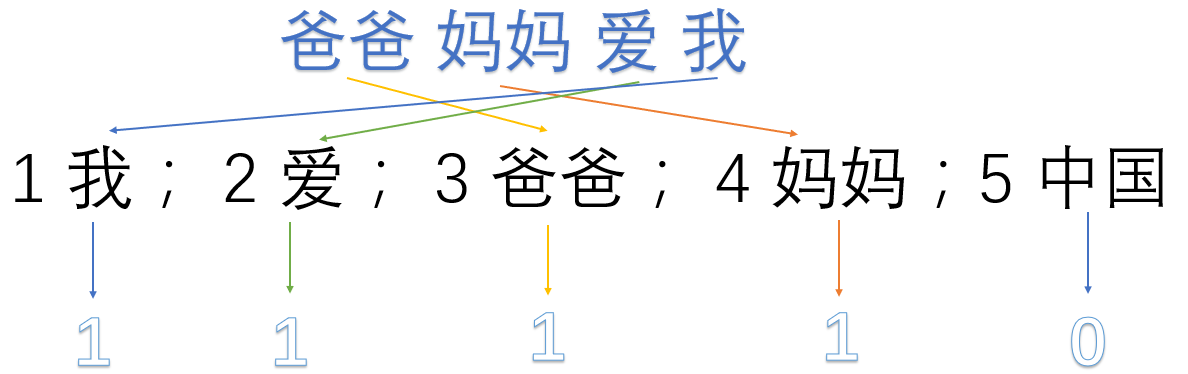
爸爸媽媽愛我
爸爸媽媽愛中國
我們首先對預料庫分離並獲取其中所有的詞,然後對每個此進行編號:
1 我; 2 愛; 3 爸爸; 4 媽媽;5 中國
然後使用one hot對每段話提取特徵向量:
 ;
; ;
;
因此我們得到了最終的特徵向量為
我愛中國 -> 1,1,0,0,1
爸爸媽媽愛我 -> 1,1,1,1,0 (缺點:詞的順序與原本不一致)
爸爸媽媽愛中國 -> 0,1,1,1,1
優缺點分析
優點:一是解決了分類器不好處理離散資料的問題,二是在一定程度上也起到了擴充特徵的作用(上面樣本特徵數從3擴充套件到了9)
缺點:在文字特徵表示上有些缺點就非常突出了。首先,它是一個詞袋模型,不考慮詞與詞之間的順序(文字中詞的順序資訊也是很重要的);其次,它假設詞與詞相互獨立(在大多數情況下,詞與詞是相互影響的);最後,它得到的特徵是離散稀疏的。
2. TF-IDF
TF-IDF是資訊檢索(IR)中最常用的一種文字表示法。演算法的思想也很簡單,就是統計每個詞出現的詞頻(TF),然後再為其附上一個權值引數(IDF)。舉個例子:
現在假設我們要統計一篇文件中的前10個關鍵詞,應該怎麼下手?首先想到的是統計一下文件中每個詞出現的頻率(TF),詞頻越高,這個詞就越重要。但是統計完你可能會發現你得到的關鍵詞基本都是“的”、“是”、“為”這樣沒有實際意義的詞(停用詞),這個問題怎麼解決呢?你可能會想到為每個詞都加一個權重,像這種”停用詞“就加一個很小的權重(甚至是置為0),這個權重就是IDF。下面再來看看公式:

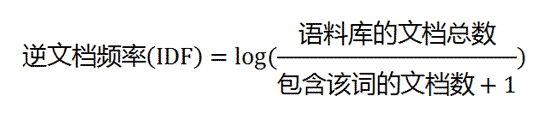
TF應該很容易理解就是計算詞頻,IDF衡量詞的常見程度。為了計算IDF我們需要事先準備一個語料庫用來模擬語言的使用環境,如果一個詞越是常見,那麼式子中分母就越大,逆文件頻率就越小越接近於0。這裡的分母+1是為了避免分母為0的情況出現。TF-IDF的計算公式如下:
![]()
根據公式很容易看出,TF-IDF的值與該詞在文章中出現的頻率成正比,與該詞在整個語料庫中出現的頻率成反比,因此可以很好的實現提取文章中關鍵詞的目的。
優缺點分析
優點:簡單快速,結果比較符合實際
缺點:單純考慮詞頻,忽略了詞與詞的位置資訊以及詞與詞之間的相互關係。