
大資料架構的典型方法和方式
大量的IT組織如今都已自己的資料架構,因為都依賴於傳統的資料架構。處理多資料來源已不再新鮮;這些架構已經連線了多維度的資料來源例如 CRM 系統,檔案系統和其他商用系統。主要執行的關係型資料庫有 Oracle, DB2和Microsoft SQL。
如今,一般的資料分析週期是執行一些週期性指令碼直接從資料庫提取和處理資料。這些主要由 ETL工具如 Informatica 或者 Talend. 目標是將這些提煉的資料載入到資料倉庫用於將來的分析。
不幸的是,這一方法在週期結束後可能不適合商務的需要了。這些資料流水線可能需要幾個小時,幾天甚至幾周才能完成,但是商務決策的需求可能已經變了。除了處理時間,還有一些資料的自然改變使這些架構難於處理,例如 資料結構重構變化導致資料模型的重構或者資料容量導致的伸縮性考慮。
由於不是分散式系統,所以系統擴充套件比較困難。資料庫需要高效能的CPU,RAM和儲存方案,對於硬體的依賴使系統的擴充套件性部署非常昂貴。現在大多數IT組織已經切換到基於Hadoop的資料架構了。實際上,不僅是靈活性和技術成本,主要目標是一組商用主機分散處理負載,以及攝取海量的不同型別資料。
Figure 3-1 給出了這一架構的拓撲圖。
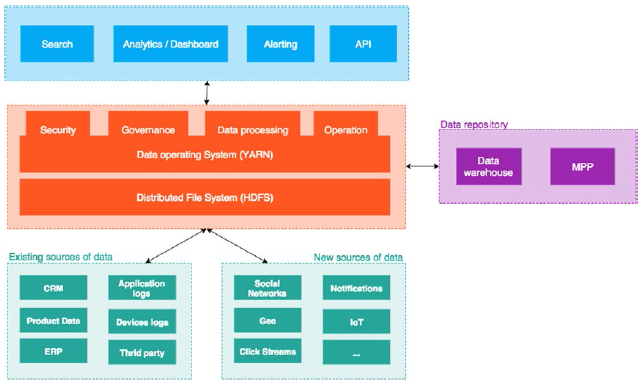
Figure 3-1. 基於Hadoop的資料架構
下面看一下資料流水線的涵蓋範圍,包含了哪些技術,以及這種型別架構的通用實踐。
處理資料來源
如 Figure 3-1所示, 資料可以來自各種內部或者外部的源,但是大資料還可以特殊地來自內部應用和裝置的日誌,例如社交網路,開放資料,甚至感測器。以社交網路為例,IT組織感興趣的資訊資料會像洪水般流入,但是其中包含了大量無用的資訊。
因此,第一是儲存資料,然後對提取的重要資訊進行處理。這些資料對銷售非常有用,尤其是當執行情感分析的時候,可以感知整個社交系統對產品或品牌的感受。
依賴於提供商,資料可能是結構化的,半結構化,或者非結構化的。Listing 3-1 給出了一個半結構化訊息的示例.
Listing 3-1. Example of the Semistructured Data of a Tweet
{
"created_at": "Fri Sep 11 12:11:59 +0000 2015",
"id": 642309610196598800,
"id_str": "642309610196598785" 從例子中可以看到,這個文件是一個JSON,有一組欄位,其中字串的元資料來描述tweet。但有些欄位非常複雜;有點陣列有時候是空的,有時候有包含了一個數據集合,也有純文字來表示tweet的內容。這就需要思考如何儲存這樣的資料。把資料放到HDFS是不足夠的;必須在技術的頂層建立一個元資料結構來支援資料結構的複雜性。這就是有時需要使用Hive的原因。
當處理海量成分混雜資料的時候,社交網路是複雜性的代表。除了資料結構,還需要將資料分類成邏輯上的子集以便增強資料處理的效果。考慮以情緒分析的例子,從大資料集的非結構化資料中得到有價值資訊的位置來組成資料。例如,通用的方法是對資料進行時間分片使資料處理更加聚焦,比方說一年資料中的某個特定周。
也必須注意到要安全地訪問資料,多數採用象 Kerberos 或其他的認證提供者。但是如果資料平臺涉及到新的使用場景,首先要處理的是多租戶技術的安全性。然後,週期性地建立資料映象以便故障發生時從中提取。所有這些考慮都是標準的,而且可以幸運地由大量供應商提供。這些開箱即用的軟體可以保證,或幫助你實現或者配置管理這些概念。
處理資料
當從源到目標的純粹傳輸時,資料傳輸時由ETL工具處理。這些工具有 Talend, Pentaho, Informatica, 或者 IBM Datastage ,這是大資料專案中最常用的軟體。但還是不夠的,還需要一些補充的工具例如Sqoop 來簡化資料匯入或匯出。在任何情況下,使用多種工具來攝取資料,通用的目標儲存是 : HDFS. HDFS 是一個Hadoop 釋出版的入口; 資料需要儲存在這樣的檔案系統中,以便於高層應用和專案的處理。
當HDFS儲存在資料中的時候,然後如何訪問和處理它們呢?
作為一個例子可能是Hive,它在HDFS中建立了一種資料結構,可以方便地訪問這些檔案。這個結構自身象一個數據表。例如, Listing 3-2 展示了一個處理tweet的結構示例。
Listing 3-2. Hive Tweet Structure
create table tweets (
created_at string,
entities struct <
hashtags: array ,
text: string>>,
media: array ,
media_url: string,
media_url_https: string,
sizes: array >,
url: string>>,
urls: array ,
url: string>>,
user_mentions: array ,
name: string,
screen_name: string>>>,
geo struct <
coordinates: array ,
type: string>,
id bigint,
id_str string,
in_reply_to_screen_name string,
in_reply_to_status_id bigint,
in_reply_to_status_id_str string,
in_reply_to_user_id int,
in_reply_to_user_id_str string,
retweeted_status struct <
created_at: string,
entities: struct <
hashtags: array ,
text: string>>,
media: array ,
media_url: string,
media_url_https: string,
sizes: array >,
url: string>>,
urls: array ,
url: string>>,
user_mentions: array ,
name: string,
screen_name: string>>>,
geo: struct <
coordinates: array ,
type: string>,
id: bigint,
id_str: string,
in_reply_to_screen_name: string,
in_reply_to_status_id: bigint,
in_reply_to_status_id_str: string,
in_reply_to_user_id: int,
in_reply_to_user_id_str: string,
source: string,
text: string,
user: struct <
id: int,
id_str: string,
name: string,
profile_image_url_https: string,
protected: boolean,
screen_name: string,
verified: boolean>>,
source string,
text string,
user struct <
id: int,
id_str: binary,
name: string,
profile_image_url_https: string,
protected: boolean,
screen_name: string,
verified: boolean>
)
PARTITIONED BY (datehour INT)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION '/user/username/tweets';可以看到,tweets 是一個表中的結構,有一個子結構來描述非結構化文件資料來源的複雜性。現在資料安全地儲存在HDFS中了, 由Hive來結構化,準備作為處理和查詢流水線的一部分。作為一個例子, Listing 3-3 展示了所選資料雜湊標籤的分佈.
Listing 3-3. Top Hashtags
SELECT
LOWER(hashtags.text),
COUNT(*) AS hashtag_count
FROM tweets
LATERAL VIEW EXPLODE(entities.hashtags) t1 AS hashtags
GROUP BY LOWER(hashtags.text)
ORDER BY hashtag_count DESC
LIMIT 15;因為提供了類SQL的查詢語言,通過Hive查詢資料非常方便。問題就是查詢時延;基本上等同於一個 MapReduce job的時延. 實際上, Hive 查詢被翻譯成一個MapReduce job執行通用的處理流水線,這導致了長時處理。
當需要實時資料傳輸時,這就成為了一個問題,例如實時觀察最多雜湊標籤的時候。對例如新興的技術如Spark來說,實時處理海量資料不再神祕。不但可以實時處理而且實現簡單。例如, Listing 3-4 展示瞭如何在MapReduce 中實現一個單詞計數功能。
Listing 3-4. MapReduce 的Word Count (from www.dattamsha.com/2014/09/hadoop-mr-vs-spark-rdd-wordcount-program/)
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Listing 3-5 展示了Spark是如何做的 (Python).
Listing 3-5. Spark的Word Count
from pyspark import SparkContext
logFile = "hdfs://localhost:9000/user/bigdatavm/input"
sc = SparkContext("spark://bigdata-vm:7077", "WordCount")
textFile = sc.textFile(logFile)
wordCounts = textFile.flatMap(lambda line:line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
wordCounts.saveAsTextFile("hdfs://localhost:9000/user/bigdatavm/output")這就需要分割架構成多個部分來處理特定的需求,一個是批處理,另一個是流處理。
架構分割
當處理海量資料的時候,Hadoop 帶來了大量的解決方案,但也為資源分配和管理儲存資料帶來了挑戰,我們總是希望在保持最小時延的同時而消減成本。和其他架構類似,資料架構滿足了SLA驅動的需求。因此, 每個job不應該均等地消耗每個資源,這就要求或者是可管理的,或者有一個優先順序系統,或者有相互獨立的架構,硬體,網路等等。
下面,將討論現代資料架構如何按照SLA需要來分割不同的使用水平。為了方便解釋 , Figure 3-2.解釋了重新分割槽。
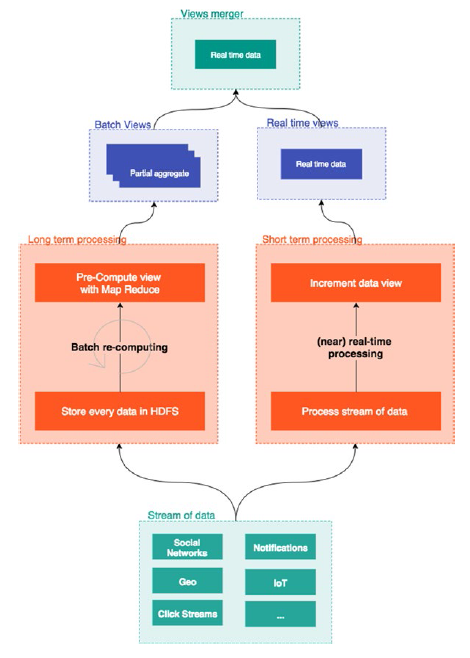
Figure 3-2. Modern data architecture
已經看到, 架構分成如下部分:
長時處理部分
短時處理部分
檢視融合部分
看一下每個部分,並解釋所影響的角色。
批處理
長時處理任務,或者批處理,是Hadoop的第一代實現,例如MapReduce, Hive, Pig, 等等. 這些jobs 趨向於處理海量資料,以及攝取資料或者聚合資料。使用HDFS作為資料的分佈和排程,依賴所使用的釋出版可以通過不同的工具來管控。
一般的, 這些任務的目標是保持資料的聚合計算結果,以及分析結果。已經說過,批處理是大資料開始實現時的頭等公民,因為這是處理資料的自然方式:提取或採集資料,然後排程任務。批處理在完成聚合計算時要花費大量的時間。這些任務主要滿足商用系統的處理需要而不是處理資料流。 批處理非常容易管理和監控,這是由於是單次執行,而流式系統需要連續監控。現在通過 YARN, 也可以管理批處理的資源分配。這種方式,使IT組織可以依賴每個批處理的SLA來分割批處理架構。
處理優先順序
當對待批處理的時候, IT組織希望對操作和處理進行總體控制,例如排程或優先處理某些任務。和大多數IT系統類似,一個數據平臺同樣開始於一個引導用例,而該用例可能影響到其他組織的其他部分,又要增加更多的用例到這個平臺上。一個簡單的轉化就是資料平臺變成了多租戶資料平臺,依賴不同的使用場景有著很多SLA。
在Hadoop 2.0和基於Yarn的架構中,多租戶技術提供特性是允許使用者訪問同樣的資料平臺但在不同叢集有著不同的處理能力。YARN 也允許執行非MapReduce應用, 所以通過 ResourceManager和YARN 容量排程器,可以跨應用型別來提供任務的優先順序。Hadoop 工作負載的分發由容量排程器完成。
這種配置優雅地安排可預測的叢集資源,給我們安全和充分利用叢集。在任務佇列可以設定任務的使用百分比。Figure 3-3 解釋了這一概念。
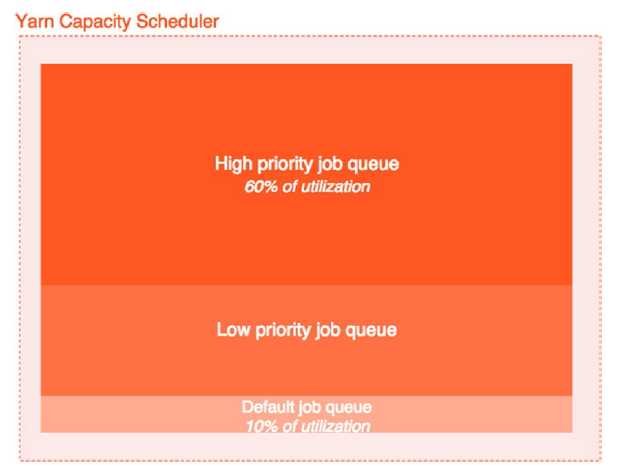
Figure 3-3. YARN job 佇列
該示例解釋了三種佇列的不同優先順序: 高,低 , 和預設. 這可以翻譯成簡單的 YARN 容量排程器配置,見 Listing 3-6.
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,highPriority,lowPriority</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.highPriority.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.lowPriority.capacity</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>10</value>
</property>每個佇列有一個最小的叢集容量,而且是彈性的。這意味著如果有空閒資源,這個佇列可以被最小化執行。當然,有可能是最大容量
見Listing 3-7.
Listing 3-7. 最大的Queue 容量
<property>
<name>yarn.scheduler.capacity.root.lowPriority.maximum-capacity</name>
<value>50</value>
</property>這一配置設定了容量, 所以一個人提交了一個(例如, 一個 MapReduce job),可以依賴所期望的需求提交到一個特殊佇列,見 Listing 3-8.
Listing 3-8. 提交一個 MapReduce Job
Configuration priorityConf = new Configuration();
priorityConf.set("mapreduce.job.queuename", queueName);通過 YARN 容量排程器, 批處理在資源管理上非常高效,在工業界有著大量的應用,例如給推薦引擎分配比非重要需求的資料處理更多的資源。但是談到了推薦,大多數IT系統 現在是一短時處理任務,以及依賴於流架構。
流處理
短時處理,或者叫流式處理, 用於攝取高吞吐量資料. 流處理方案可以處理海量資料,而且是高分佈,可伸縮,和容錯的。這種架構解決了一系列的挑戰。已經說過,一個主要目的是處理海量資料。儘管以前已經有各種流式技術,但現在是高可用,彈性和高效能的。高效能是應對資料容量,複雜性和大小的增長。
如果資料容量增長了,這些架構能夠無縫整合各種資料來源和應用,例如資料倉庫,檔案,資料歷史,社交網路,應用日誌等等。這需要提供一致性的敏捷API,面向客戶端的API,以及能夠將資訊輸出到各種渠道,例如通知引擎,搜尋引擎,和第三方應用。基本上,這樣的技術有更多實時響應的約束。
最後,從流式架構中,使用者最想得到的就是實時分析,需求很清楚,組成如下:實時發現數據,更容易地查詢資料,主動監控事件的閾值以通知使用者和應用。
流架構首先用在金融領域,這裡有著高吞吐量交易的使用場景,但是已經擴充套件到大量其他的使用場景,主要是電子商務,電信,防偽監測,和分析。從而誕生了兩個主要技術: Apache Spark 和Apache Storm.
這裡選擇了Spark,有很好的社群支援,見Figure 3-4 .
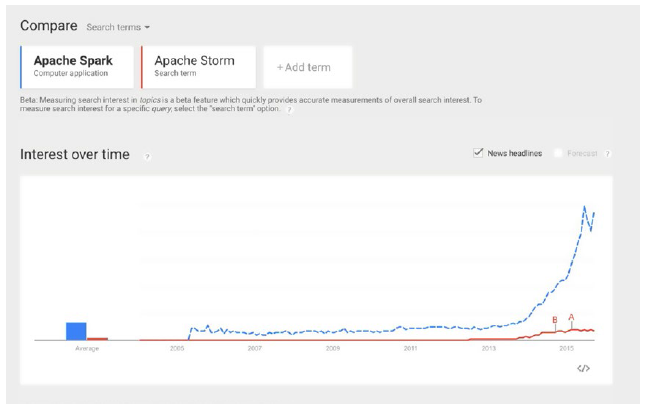
Figure 3-4. Apache Spark 和 Apache Storm的Google 趨勢
有專門的章節來描述如何將不同的技術結合起來,包括Spark的實時流處理和搜尋分析。
Lambda 架構的概念
前面談到將資料架構分成三個部分: 批處理,流處理和服務架構. 儘管批處理還是現存IT組織中資料架構的通用實踐,當還不能滿足大多數流式資料的真正需求,如果需要的話,需要將資料儲存在一個面向批處理的檔案系統中。部署一個流式架構不像IT組織批處理架構那麼簡單,與之對應,流處理架構帶來了更多的操作複雜性,架構必須要設計成吸收無用突發資料以維持較低的響應時間。
當感到Hadoop 釋出版部署麻煩的時候,開始的方法是簡化流架構以便有相同的處理API等等。
甚至如果SLA不能滿足以及不希望以數秒或數分鐘來獲取資料,需要消減部署的繁瑣性。在我看來,一個流式架構是現代資料架構的自然演進。它消減了軟體的複雜性,就像第一代大資料架構消減了硬體那樣。我們這一架構的選擇可能不是通用的,但確實是廣泛使用的,這一技術棧應該可以適應90%的使用場景。
lambda 架構是兩個世界中的最好品種。資料是暫態的,處理是實時的,可以重新計算和建立在批處理層的部分聚合資料,最後在服務層融化服務。為例實現這一正規化,選擇以下技術:
- Logstash-資料攝取和轉發
- Apache Kafka分發資料
- Logtash agent 處理日誌
- Apache Spark 流處理
- Elasticsearch 作為服務層
Figure 3-5介紹了這一架構.
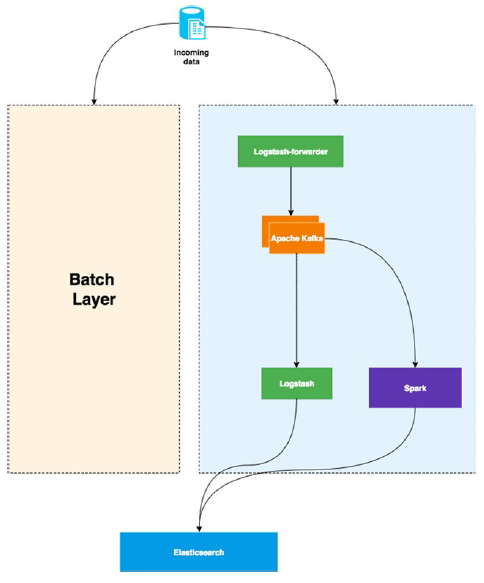
Figure 3-5. Lambda 架構的加速和服務層
lambda 架構通常用於電子商務網站來實現推薦或者安全分析等不同的目的。例如點選流資料,可以從中提取多重有意義的見解。
一方面,使用長時處理層,處理點選流,聚合資料,與其他資料來源交叉使用來建立推薦引擎。這個例子中,利用 點選流資料與其他資料來源包含的人口統計資訊的相關性,在ElasticSearch中構建索引檢視。
另一方面, 同樣的資料被用來點檢測。實際上,大多數電子商務應用都會面對安全上的威脅,一種方式是通過流處理層分析使用者的點選行為而實時地將IP地址放入黑名單。參見 Figure 3-5, 可以使用Spark 處理複雜的互相關性,或者執行機器學習程序在ElasticSearch 索引前來提取資料。