
寬字元wchar_t和窄字元char區別
1. 首先,說下窄字元char了,大家都很清楚,就是8bit表示的byte,長度固定。char字元只能表示ASII碼錶中的256個字元,包括前128個可見字元和後面的128個不可見字元。
而wchar_t則是因為char所能表示的字元數太少(256個)而應運而生的,它的長度可以8bit,16bit,32bit,長度是與不同平臺上的c庫相關的。其實這個長度是根據指定平臺上想要用的encoding編碼方式來設定的。
在win32 MSVC環境下,c庫中wchar_t的長度是2個byte,定義如下:
typedef unsigned short wchar_t; /* 16 bits */
它是按照utf-16編碼,但是因為wchar_t定義的長度只有2個位元組,所以它不能表示utf-16編碼長度為4個位元組的字元。即wchar_t只表示了utf-16的一個子集。換句話話說,就是MSVC下,wchar_t是utf-16編碼的,但是隻能表示utf-16的一個子集。按utf-16編碼時,大部分字元都以固定長度的位元組 (2位元組) 儲存.
在Linux-x86的GCC環境下,c庫中wchar_t的長度為四個位元組,用UCS-4(即utf-32編碼方式)。
wchar_t就是儲存的字元的unicode碼值的編碼值,如windows下就是unicode碼值的utf-16編碼值:
TCHAR wide[] = L"態";
在vs中watch為: [0] 24577 L'態' wchar_t,即對應的十進位制為24577,而"態"unicode表中查到的碼值為十六進位制的6001,而0x6001對應的十進位制值就是24577.
TCHAR wide[] = L"a"; 因為a的unicode值與ASCII值一樣,為97. 如果unicode碼值U小於0x10000,則U的UTF-16編碼就是U對應的16位無符號整數。
所以可知,0x6001的utf-16編碼值就是0x6001。
wchar_t w1= L'中'; //Unicode 編碼
wchar_t w2= '中'; //Ansi編碼
printf( "%0x %0x ",w1,w2);
結果:
4e2d d6d0
雖然同樣是賦值給wchar_t,但是不同的編碼則值是不同的。同時也說明了wchar_t不光是可以儲存Unicode寬字元,也可以儲存其它的編碼。但是如果是儲存的Ansi編碼,則按照寬字元的格式輸出的是什麼呢?
wchar_t c= L'中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述程式碼能正常輸出'中'字
wchar_t c= '中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述程式碼不能正常輸出'中'字,結果是什麼也沒輸出。
所以如果是需要寬字元引數的API裡傳入值為Ansi編碼值的wchar_t可能會得到不可預測的結果。
c/c++標準只是宣告wchar_t是一個可以表示字符集中的任意一個字元的足夠寬的變數型別。wchar_t可以用任何encoding編碼方式來儲存這個字元,如ANSI, or UCS-2, or UCS- 4, 甚至是SCU-128,只不過我們通常是用unicode編碼方式。wchar_t是與實現相關的。
所以為了可移植性,我們不能假定wchar_t的編碼方式,然後根據編碼方式做一些相關性操作,我們只能理解它為一個足夠寬的字元型別。
2. ANSI碼
ANSI碼(American National Standards Institute),中文:美國國家標準學會的標準碼。
我們說的ansi碼,指windows平臺的一種ascii擴充套件碼,他將ascii碼擴充套件到8bits,增加了0x80-0xff共128個字元。
對於ANSI碼錶而言,它相容ASCII碼錶,0x00~0x7F之間的字元,依舊是1個位元組代表1個字元。為使計算機支援更多語言,通常使用 0x80~0xFF 範圍的 2 個位元組來表示 1 個非英語字元。
像GB2312, BIG5, JIS 等使用ANSI碼錶的0x80~0xFF範圍的 2 個位元組來代表一個字元的各種漢字延伸編碼方式,統稱為ANSI 編碼。比如:漢字 '中' 在GB2312碼錶中,使用 [0xD6,0xD0] 這兩個位元組儲存。ANSI 編碼與UTF-8一樣,也是一種編碼方式。
ANSI用一個位元組來表示英語字元,用兩個位元組來表示一個非英語字元----這個字元位於某個字符集中的value。而字符集則可以是象GB2312,BIG5等在ASCII碼錶基礎上擴充套件的字符集。這些字符集中相容ASCII碼錶,並且加入了漢字(或繁體等)的字符集。
在vs 的c++環境下,可以通過如下方式檢視漢字的ANSI編碼值。char型別取值範圍為-128~127。-42對應的char型別資料的原碼為“10101010”,反碼為"11010101",補碼為"11010110",即十六進位制為0xD6。同理-48則為0xD0.由此我們可知,ANSI,是通過兩個窄字元char來表示一個漢字的。
當我們 在VS裡輸入一個“中”字時,其實它在GB2312裡對應的兩個字元值為0xD6和0xD0,那麼VS裡其實記錄的就是[0xD6,0xD0]這個編碼值。當我們電腦控制面板裡設定的system locale為中文的時候,[0xD6,0xD0]在VS裡就是呈現出“中”字;但是如果system locale設定為韓文時,[0xD6,0xD0]在VS裡就是呈現出的就是它所表示的韓文字。即同一個ANSI編碼值,對於不同的system locale值(不同的字符集),顯示出來的字元是不一樣的。
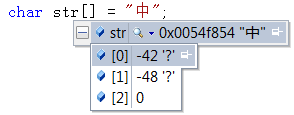
在VS工程屬性裡無論你選擇Multi-Byte Character Set 或 Unicode Character Set字符集,char str[] = "中";這個表示式裡,"中"都是ANSI編碼,編碼值都是[0xD6,0xD0]。即預設情況下,如果不加_T或L,預設情況下所有的字元都是ANSI編碼。
3. 相互轉換:
轉換的時候是與encoding相關的,轉換完後顯示是和本地的language相關的。
windows:
MultiByteToWideChar和WideCharToMultiByte, MultiByteToWideChar可將utf-8編碼的多位元組或是ANSI編碼的多位元組(即兩個位元組)等轉換為Unicode的寬字元wchar_t。例如,兩個byte的窄字元表示的ANSI漢字轉換為Unicode的寬字元wchar_t。WideCharToMultiByte可以將wchar_t轉換utf-8或ANSI 等編碼的多位元組。
linux:mbstowcs和wcstombs
MultiByteToWideChar根據介面中指定的encoding方式將source多字元轉換為對應的unicode值的寬字元;WideCharToMultiByte則剛好相反,是根據指定的encoding編碼方式將unicode字元轉換為指定的編碼方式的多字元。
char str[] = "中";
int len=MultiByteToWideChar(CP_ACP,0,str, -1, NULL,0);
wchar_t *w_string = new wchar_t[len];
memset(w_string,0,sizeof(wchar_t)*len);
MultiByteToWideChar(CP_ACP, 0, str,-1,w_string, len);
執行結果:
則len的長度為2,得到兩個寬字元。*w_string則是'中'的寬字元值,*(w_string+1)則為結束符'\0'對應的寬字元值0.
詳細的轉換過程,下面的link中有詳細描述:
另外附上一個非常不錯的文章連結: