
21 為什麼只修改一行的語句,鎖這麼多?
上一篇中介紹了間隙鎖和next-key lock的概念,但是沒有說明加鎖規則
加鎖規則兩個前提說明:
1 mysql後面的版本可能會改變加鎖策略,所以這個規則只限於截止到目前最新的版本,即5.x系列 <=5.7.24, 8.0系列 <=8.0.13.
2 如果大家在驗證中發現有bad case的話,請提出來,後面會進行補充。
因為間隙鎖在可重複讀隔離級別下才有效,所以本篇文章的描述,若沒有特殊說明,都是在RR隔離級別下面。
我總結的加鎖規則裡面,包含兩個”原則”,兩個”優化”和一個”bug”
1 原則1:加鎖的基本單位是next-key lock。next-key lock
2 原則2:查詢過程中訪問到的物件才會加鎖。
3 優化1:索引上的等值查詢,給唯一索引加鎖的時候,next-key lock退化為行鎖。
4 優化2:索引上的等值查詢,向右遍歷時且最後一個值不滿足等值條件的時候,next-key lock退化為間隙鎖。
5 一個bug:唯一索引上的範圍查詢會訪問到不滿足條件的第一個值為止。
建表語句和初始
CREATE TABLE `t20` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t20 values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
案例一:等值查詢間隙鎖
關於等值條件操作間隙:
| SESSION A |
SESSION B |
SESSION C |
| begin; update t20 set d=d+1 where id=7; |
|
|
|
|
insert into t20 values(8,8,8); (blocked) |
|
|
|
|
update t20 set d=d+1 where id=10; (query ok) |


由於表t20中沒有id=7的記錄,所以用上面的加鎖規則判斷一下:
1 根據原則1,加鎖單位是next-key lock,session A加鎖範圍就是(5,10]
2 同時根據優化2,這是一個等值查詢(id=7),而id=10不滿足查詢條件,next-key lock退化為間隙鎖,因此最終加鎖的範圍是(5,10)。
所以,session B要往這個間隙裡面插入id=8的記錄會被鎖住,但是session C修改id=10這行是可以的。
案例二:非唯一索引等值鎖
第二個例子是關於覆蓋索引上的鎖:
| SESSION A |
SESSION B |
SESSION C |
| begin; select id from t20 where c=5 lock in share mode; |
|
|
|
|
update t20 set d=d+1 where id=5;(query ok) |
|
|
|
|
insert into t20 values(7,7,7); (blocked) |
只在非唯一索引上的鎖
這裡session A要給索引c上c=5的這一行加上讀鎖。
1 根據原則1,加上單位是next-key lock,因此會給(0,5]加上next-key lock。
2 要注意c是普通索引,因此僅範圍c=5這一條記錄是不能馬上停下來,需要向右遍歷,查到c=10才放棄,根據原則2,訪問到的都要加鎖,因此要給(5,10]加next-key lock。
3 但是同時這個符合優化2:等值判斷,向右遍歷,最後一個值不滿足c=5這個條件,因此退化為間隙鎖(5,10).
4 根據原則2,只有訪問到的物件才會加鎖。這個查詢使用覆蓋索引,並不需要訪問主鍵索引,所以主鍵索引上沒有加任何鎖,這就是為什麼session B的update語句可以完成。
但session C要插入一個(7,7,7)的記錄,就會被session A的間隙鎖(5,10)鎖住。
需要注意,在這個例子中,lock in share mode只鎖覆蓋索引,但是如果是for update就不一樣了。執行for update時,系統會認為你接下來要更新資料,因此會順便給主鍵索引上滿足條件的行加上行鎖。
這個例子說明,鎖是加在索引上的;同時,它給我們的指導是,如果你要用lock in share mode來給行加讀鎖避免資料被更新的話,就必須得繞過覆蓋索引的優化,在查詢欄位中加入索引中不存在的欄位。比如session A的查詢語句改成select d from t where c=5 lock in share mode,可以驗證一下效果。
案例三:主鍵範圍索引
第三個例子是關於範圍查詢的
舉例之前,你可以先思考一下這個問題:對於我們這個表t20,下面這兩條語句,加鎖的範圍相同嗎?
mysql> select * from t20 where id=10 for update;
mysql> select * from t20 where id>=10 and id<11 for update;
你可能會想,id定義為int型別,這2個語句就是等價的吧,其實,他們並不是完全等價。
在邏輯上,這兩條語句肯定是等價的,但是他們的加鎖規則不太一樣,
| SESSION A |
SESSION B |
SESSION C |
| begin; select * from t20 where id>=10 and id<11 for update; |
|
|
|
|
insert into t20 values(8,8,8); (query ok) insert into t20 values(13,13,13); (blocked) |
|
|
|
|
update t20 set d=d+1 where id=15; (blocked) |
主鍵索引上範圍查詢的鎖
現在用前面的加鎖規則,來分析session A會加什麼鎖
1, 開始執行的時候,要找到第一個id=10的行,因此本該是next-key lock(5,10]。根據優化1,主鍵id上的等值條件,退化成行鎖,只加了id=10這一行的行鎖。
2, 範圍查詢就往後繼續找,找到id=15的這一行停下來,因此需要加上next-key lock(10,15]。
所以,session A這時候鎖住的範圍就是主鍵索引上,行鎖id=10和next-key lock(10,15]。這樣session B和session C的結果就可以理解。
這裡需要注意,首次session A 定位查詢id=10的行的時候,是當做等值來判斷的,而向右掃描到id=15的時候,用的是範圍查詢來判斷。
案例四:非唯一索引範圍鎖
接下來,我們在看兩個範圍查詢加鎖的例子,可以對照案例三
| SESSION A |
SESSION B |
SESSION C |
| begin; select * from t20 where c>=10 and c<11 for update; |
|
|
|
|
insert into t20 values(8,8,8); (blocked) |
|
|
|
|
update t20 set d=d+1 where c=15;(blocked) |
非唯一索引範圍鎖
這次session A 用欄位c來判斷,加鎖規則跟案例3唯一不同的是,在第一次用c=10的定位記錄時候,索引c上加上了(5,10]這個next-key lock,後,
由於索引c是非唯一索引,沒有優化規則,也就是說不會蛻變為行鎖,因此最終session A加的鎖是,索引c上的(5,10]和(10,15]這兩個next-key lock。
所以從結果上來看,session B要插入(8,8,8)這個insert語句就會被堵住。
這裡需要掃描到c=15才停止掃描,是合理的,因為innodb要掃到c=15,才知道不需要繼續往後找了。
案例五:唯一索引範圍鎖bug
前面的四個案例,我們已經用到了加鎖規則中的兩個原則和兩個優化,接下來再看一個關於加鎖規則中的bug案例。
| SESSION A |
SESSION B |
SESSION C |
| begin; select * from t20 where id>10 and id<=15 for update; |
|
|
|
|
update t20 set d=d+1 where id = 20;(blocked) |
|
|
|
|
insert into t20 values(16,16,16); (blocked) |
唯一索引範圍鎖的bug
SESSION A是一個範圍查詢,按照原則1的話,應該是索引id上只加了(10,15]這個next-key lock,並且因為id是唯一鍵,所以迴圈判斷到id=15這一行就應該停止了。
但是實現上,innodb會往前掃描到第一個不滿足條件的行為止,也就是id=20。而已由於是範圍掃描,因此索引id上的(15,20]這個next-key lock也會被鎖上。
所以你看到了,session B 要更新id=20這一行,是會被鎖住的,同樣的session C要插入id=16的一行,也會被鎖住。
照理說,這裡鎖著id=20這一行的行為,其實實際上是沒有必要的,因為掃描到id=15,就可以確定不用往後再找了,但實現上還是這麼做了。
案例六:非唯一索引上存在”等值”的例子
接下來的例子,是為了更好的說明”間隙”這個概念,這裡給表t20插入一條記錄
([email protected]:3306) [test]> insert into t20 values (30,10,30);
Query OK, 1 row affected (0.01 sec)
([email protected]:3306) [test]> select * from t20;
+----+------+------+
| id | c | d |
+----+------+------+
| 0 | 0 | 0 |
| 5 | 5 | 5 |
| 10 | 10 | 10 |
| 15 | 15 | 15 |
| 20 | 20 | 20 |
| 25 | 25 | 25 |
| 30 | 10 | 30 |
+----+------+------+
7 rows in set (0.00 sec)
新插入的這一行c=10,也就說表t20有兩個c=10的行。那麼,這時候索引c上的間隙是什麼狀態呢?要知道,由於非唯一索引上包含主鍵的值,所以是不可能存在”相同”的兩行的。

可以看到,雖然有兩個c=10,但是它們的主鍵id是不同的(分別為10和30),因此這兩個c=10的記錄之間,也是有間隙的。
圖中畫出了索引c上的主鍵id。為了跟間隙鎖的開區間形式進行區別,用(c=10,c=30)這樣的形式,來表示索引上的一行。
案例六,用delete語句來驗證,注意,delete語句加鎖的邏輯,其實跟select...for update是類似的,也就是在開始總結的兩個原則,兩個優化和一個bug。
| SESSION A |
SESSION B |
SESSION C |
| begin; delete from t20 where c=10; |
|
|
|
|
insert into t20 values(12,12,12);(blocked) |
|
|
|
|
update t20 set d=d+1 where c=15;(query ok) |
這時,session A在遍歷的時候,先訪問第一個c=10的記錄,同樣的,根據原則1,這裡加的是(c=5,id=5)到(c=10,id=10)這個next-key lock。
然後session A向右查詢,直到碰到(c=15,id=15)這一行,迴圈才結束。根據優化規則2,這是一個等值查詢,向右查詢到了不滿足的條件的行,所以會退化成(c=10,id=10)到(c=15,id=15)的間隙鎖。
也即是說,這個delete語句在索引c上的加鎖範圍,是下面藍色的區域。

這個區域左右兩邊都是虛線,表示開區間,即(c=5,id=5)和(c=15,id-15)這兩行上沒有鎖。
案例七:limit語句加鎖
例子6也有一個對照案例,場景如下
| SESSION A |
SESSION B |
| begin; delete from t20 where c=10 limit 2; |
|
|
|
insert into t20 values(12,12,12);(query ok) |
這個例子裡,session A的delete語句加了limit 2。要指定表t20裡c=10其實也就兩條記錄,因此加不加limit 2,刪除的效果都是一樣。但是在加鎖的效果卻不同。可以看到,session B的insert語言執行通過了,跟案例6的結果卻不同。
這是因為,案例七的delete語句明確加了limit 2 的限制,因此在遍歷(c=10,id=30)這一行的之後,滿足條件的語句已經有兩條,迴圈就結束了。
因此,索引c上的加鎖範圍就變成了從(c=5,id=5)到(c=10,id=30)這個前開後閉的區間,如圖所示
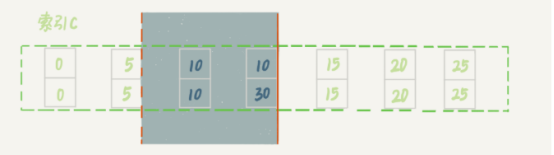
可以看到,(c=10,id=20)之後的這個間隙並沒有在加鎖範圍裡,因此insert語句插入c=12是可以成功的。
這個例子對我們實踐的指導意義就在,在刪除資料的時候儘量加limit。這樣不僅可以控制刪除資料的條數,讓操作更安全,還可以減小加鎖的範圍。
案例八:一個死鎖的例子
前面的例子中,我們在分析的時候,是按照next-key lock加鎖的邏輯來分析的,因此在分析的時候比較方便。最後在看一個例子,目的是說明:next-key lock實際上是間隙鎖和行鎖加起來的結果。
| SESSION A |
SESSION B |
| begin; select id from t20 where c=10 lock in share mode; |
|
|
|
update t20 set d=d+1 where c=10;(blocked) |
| insert into t20 values(8,8,8); |
|
|
|
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |

現在,我們按時間順序來分析一下為什麼是這樣的結果
1,session A啟動事務後執行查詢語句加lock in share mode,在索引c上加了next-key lock(5,10]和間隙鎖(10,15);
2,Session B的update語句也要在索引c上加next-key lock(5,10],進入等待;
3,然後session A再插入(8,8,8)這一行,被session B的間隙鎖鎖住,由於出現了死鎖,innodb讓session B回滾了。
你可能會問,session B的next-key lock不是還沒有申請成功嗎?
其實是這樣的。Session B的”加next-key lock(5,10]”操作,實際上分成了兩步,先是加了(5,10)的間隙鎖,加鎖成功,然後加c=10的行鎖,這時候才被鎖住的。
也就是說,我們在分析加鎖規則的時候可以用next-key lock來分析,但是要知道,具體執行的時候,是要分成間隙鎖和行鎖兩段來執行的。
小結
這裡再次說明,上面的所有案例都是在可重複讀隔離級別(rr)下驗證。同時,可重複讀隔離級遵守兩階段鎖協議,所有加鎖的資源,都是在事務提交或回滾時才釋放的。
在最後的案例中,可以清楚的知道next-key lock實際上是有加間隙鎖和行鎖實現,如果切換到rc隔離級別,就好理解,過程中去掉了間隙鎖的部分,只剩下行鎖的部分。
另外,在rc隔離級別下還有一個優化,即:語句執行過程中加上的行鎖,在語句執行完成後,就要把”不滿足條件的行”上的行鎖直接釋放了,不需要等待事務的提交。
也就是說,在rc隔離級別下,鎖的範圍更小,鎖的時間更短,這也是不少業務都預設使用rc隔離級別的原因。
在業務需要使用rr隔離級別時候,能夠更細緻的設計操作資料庫的語句,解決幻讀問題的同時,最大限度的提升系統並行處理事務的能力。