
《Processing SPARQL queries over distributed RDF graphs》——讀書筆記
這次讀論文給了我慘痛的教訓,不做筆記是不行的,越長的論文越應該做筆記!不可怠惰!
Abstract
propose techniques for processing SPARQL queries over a large RDF graph in a distributed environment.
“partial evaluation and assembly” framework.
partial evaluation——在每個子圖中找到部分匹配的答案。
assembly——centralized and distributed.
1 Introduction
語義網資料模型,(Resource Description Framework, RDF).
資料大量增長,與之相應地,計算和儲存需求增加,超出單個機器的能力。
關於distributed evaluation of SPARQL queries over large RDF datasets 大體上有三類方法。
1) Cloud-based approaches
2) Partition-based approaches divide the RDF graph Ginto a set of subgraphs (fragments) and decompose the SPARQL query Q into subqueries. These subqueries are then executed over the partitioned data using techniques similar to relational distributed databases.
3) Federated approaches
本文的策略是劃分圖但不拆解查詢。RDF圖被拆解成頂點不相交的段。每個站點都接受完整的查詢,平行計算。該方法是首次應用於該方向,中間結果少。
基於Partial Evaluation的分散式資料管理中,每個機器將儲存在自身的資料視為已知的部分s,而儲存在其他機器上的資料視為未知的部分d。然後,每個機器利用已知部分對查詢求出部分解。最後,這些區域性匹配被收集起來並通過連線操作拼成最終解。—— 來自彭鵬的知乎回答
Within the context of graph processing, the technique has been used to evaluate reachability queries and graph simulation over graphs.
但是 SPARQL is based on graph homomorphism. SPARQL query semantics is different than these (上文中的可達性查詢和圖同構).
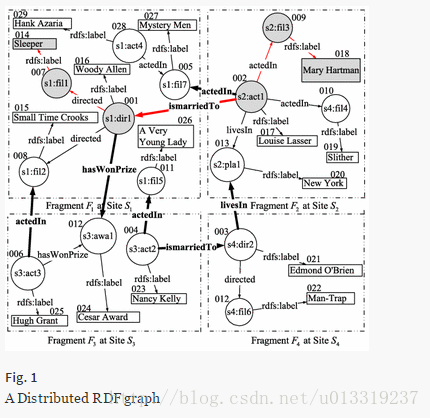
Some SPARQL query matches are contained within a fragment, which we call inner matches.
Subgraph matches that cross multiple fragments are called crossing matches.
該框架主要需要解決兩個問題:一是計算在每個站點中查詢Q的部分評價結果。二是組合這些部分匹配的結果得到答案。
方法的優點有兩方面:
一是不依賴於特定的圖的劃分策略。
二是保證中間結果的點和邊比別的方法少。
2 Related work
2.1 Distributed SPARQL query processing
2.1.1 Cloud-based approaches
HDFS-based approaches
他們將RDF三元組以flat files的格式儲存到HDFS中。進行SPARQL查詢的時候,先掃一遍HDFS檔案,然後使用MapReduce進行連線。這些方法的不同主要在於如何將RDF三元組儲存到HDFS檔案中。
SHARD 直接存到一個檔案中,每行表示一個特定主體的所有三元組。
HadoopRDF and PredicateJoin 基於謂詞劃分三元組,每個劃分存到一個檔案中。
EAGRE 將具有相似屬性的主體合成一個實體類,然後構造一個僅包含實體類及其之間連線的壓縮RDF圖。使用METIS演算法劃分圖。
No HDFS-based approaches
Besides the HDFS-based approaches, there are also some works that use other NoSQL distributed data stores to manage RDF datasets.
JenaHBase and
Trinity.RDF uses the distributed memory-cloud graph system Trinity to index and store the RDF graph.
基於雲的方法得益於雲平臺的高可擴充套件性和容錯能力,但是因MapReduce難以適配到圖計算中導致效能較低。
2.1.2 Partition-based approaches
如上文所述,就是把圖和查詢都分解。但因分解方法的不同,查詢的處理方法也不同。
GraphPartition 通過邊界點的N條鄰居來得到每個段。
WARP uses some frequent structures in workload to further extend the results of GraphPartition.
Partout…
TriAD METIS 劃分RDF圖。並且結果的塊數比site數要多。
但是有一些情況是需要根據特定的需求來劃分資料的。這些根據方法去劃分的方法不夠靈活。
2.1.3 Federated SPARQL query systems
Federated queries run SPARQL queries over multiple SPARQL endpoints. A typical example is linked data, where different RDF repositories are interconnected, providing a virtually integrated distributed database. (與文章不相關,我不做筆記了)
2.2 Partial evaluation
與第一章類似,介紹了部分評價的應用,如在分散式XML中進行XPath查詢,圖的同構查詢等等。詳細介紹了圖同構(多項式時間可解)與圖同態(完全NP問題)的區別。
3 Background and framework
Definition 1
(RDF graph) An RDF graph is denoted as
同樣的,SPARQL查詢同樣可以表示為圖。我們首次關注basic graph pattern (BGP) qurries。在第六章有詳細的討論。
Definition 2
(SPARQL BGP query) A SPARQL BGP query is denoted as
Definition 3
(SPARQL match) Consider an RDF graph G and a connected query graph Q that has n vertices
- if
vi is not a variable,f(vi) andvi have the same URI or literal value(1≤i≤n) ;- if
vi is a variable, there is no constraint overf(vi) except thatf(vi)∈{u1,..,um} ;- if there exists an edge
vivj−→− in Q, there also exists an edgef(vi)f(vj)−→−−−−−− in G. LetL(vivj−→−) denote a multi-set of labels betweenvi andvj in Q; andL(f(vi)f(vj)−→−−−−−− denote a multi-set of labels betweenf(vi) andf(vj) in G. There must exist an injective function from edge labels inL(vivj−→−) to edge labels inL(f(vi)f(vj)−→−−−−−− . Note that a variable edge label inL( 相關推薦
《Processing SPARQL queries over distributed RDF graphs》——讀書筆記
這次讀論文給了我慘痛的教訓,不做筆記是不行的,越長的論文越應該做筆記!不可怠惰! Abstract propose techniques for processing SPARQL queries over a large RDF graph in a
《Evaluating SPARQL Queries on Massive RDF Datasets》——筆記
Abstract 現在的系統大部分生成靜態分割槽,對於一些不適合現有分割槽的查詢並不友好。本文提出AdHash。 初始時,採用雜湊分割槽。快捷且可並行。 監視資料訪問模式並通過逐步重新分發和複製經常訪問的資料來動態地適應查詢負載。 Introduc
讀書筆記 - Clique-based Cooperative Multiagent Reinforcement Learning Using Factor Graphs
《Clique-based Cooperative Multiagent Reinforcement Learning Using Factor Graphs》 在許多情況下,代理不是獨立的,而是與其他代理連線,代理相互互動以共同影響環境。有時,每個代理只能獲取其附近環境的狀態以及其
Image Retrieval using Scene Graphs ——基於場景圖的影象檢索 讀書筆記
未完待續,以及今天圖片上傳一直失敗 Abstract (摘要) 這篇文章基於場景圖的概念,提出了一種新的語義影象檢索框架。場景圖表示了物件(“人”,“船”),物件的屬性(“船是白色的”),物件之間的關係(“人站在船上”)。我們使用這些場景圖來檢索與場景圖語義相關的影象
[nlp-001] Speech and Language Processing (3rd ed. draft)讀書筆記(未完待續)
0. 本書的官網主頁 ##第1章 留白 ##第2章 正則表示式、文字正則話、編輯距離 regular expression 正則表示式,從文件裡抽取指定的字串。比如,抽取“你是XXX”的姓名,或者 字串裡的價格資訊。 text normalizat
《Speech and Language Processing》讀書筆記之資訊抽取IE
Information Extraction 資訊抽取 一、概述 1.1 IE 資訊抽取就是從文字中抽取有限的幾種語義內容,是將非結構化的文字轉換為結構化資料的過程,有限的幾種語義內容主要包括:實體抽取、關係抽取、事件抽取、時序表達、模板填充等。 1.2命名實體識別(na
《代碼閱讀》讀書筆記(一)
需求 的人 一行 編碼 重要 流動 使用 分析 缺少 《代碼閱讀》讀書筆記(一) 《代碼閱讀》(《Code Reading The Open Source Perspective》)Diomidis Spinellis 著 ---------------------
《大型網站技術架構:核心原理與案例分析》-- 讀書筆記 (5) :網購秒殺系統
案例 並發 刷新 隨機 url 對策 -- 技術 動態生成 1. 秒殺活動的技術挑戰及應對策略 1.1 對現有網站業務造成沖擊 秒殺活動具有時間短,並發訪問量大的特點,必然會對現有業務造成沖擊。對策:秒殺系統獨立部署 1.2 高並發下的應用、
Java 線程第三版 第五章 極簡同步技巧 讀書筆記
prev ear ont java else 停止 第三版 不同的 結合 一、能避免同步嗎? 取得鎖會由於下面原因導致成本非常高: 取得由競爭的鎖須要在虛擬機的層面上執行很多其它的程序代碼。 要取得有競爭鎖的線程總是必須等到鎖被釋放後。 1. 寄
《Java並發編程實戰》第十章 避免活躍性危急 讀書筆記
for 分析 tac mage cas 系統 ron htm 發生 一、死鎖 所謂死鎖: 是指兩個或兩個以上的進程在運行過程中。因爭奪資源而造成的一種互相等待的現象。若無外力作用。它們都將無法推進下去。 百科百科 當兩個以上的運算單元,兩方都在等待對方停止執
css權威指南 讀書筆記
text ron :focus 表單 順序 系統 web letter 知識 網上看見推薦的書總是喜歡買回家,但是大多數時候都不會立即就看,都是在書櫥裏蒙上了一層灰塵。從畢業到現在,由於公司業務原因,寫js多余css,所以就想系統地看看css,並且做一些練習,於是就開始看《
Ajax與Comet-JavaScript高級程序設計第21章讀書筆記(1)
set activex .html 規範 sta php 協議 num 刷新 Ajax(Asynchronous Javascript + XML)技術的核心是XMLHttpRequest對象,即: XHR。雖然名字中包含XML,但它所指的僅僅是這種無須刷新頁面即可從服務器
構建之法——讀書筆記(5)
exp 時間 微軟 padding 層次結構 敏捷 參加 解決問題 企業 第七章 MSF What is MSF?——Microsoft Solution Framework(微軟解決方案框架)即一個方法論,也就是微軟推薦的軟件開發方法。 MSF基本原則: MSF沒有像敏捷
《構建之法》第四章讀書筆記
解決 更多 發現 開發 空白 知識點 相互 文字 人的 本章理論和知識點有:代碼規範、極限編程、結對編程、兩人合作的不同階段、影響他人的技巧 一、代碼規範 1、代碼風格規範。主要是文字上的規定,看似表面文章,實際上非常重要。 代碼風格的原則是:簡明,易讀,無二義性 。包括了
《java並發編程實戰》讀書筆記5--任務執行, Executor框架
調度 生產 頁面 acc 消費者模式 退出 融合 可能 第一篇 6.1 在線程中執行任務 第一步要找出清晰的任務邊界。大多數服務器應用程序都提供了一種自然的任務邊界選擇方式:以獨立的請求為邊界。 -6.6.1 串行地執行任務 最簡單的任務調度策略是在單個線程中串行地執行各項
[讀書筆記]《淘寶技術這十年》
一個 nbsp 訪問量 apr 即使 讓我 項目 tair 消息訂閱 摘錄自:http://www.cnblogs.com/me115/p/3545054.html 內容目錄: 淘寶的升級路線 淘寶創新的技術 從牛人身上看到的 這本書很有趣,故事敘述好玩,且價
《神經網絡設計》讀書筆記第一章
tails 人工 讀書筆記 進一步 結構 network 設計 消失 第一章 包括記憶在內的所有生物神經功能,都存儲在神經元及其之間的連接上。 神經網絡中關於學習的過程是 神經元之間建立新的連接或對已有連接進行修改的過程。 神經網絡的起源:M-P模型 是按照生物神經元的
《TCP/IP具體解釋》讀書筆記(21章)-TCP的超時與重傳
打開 定時器 是否 檢查 例如 技術 blog 信息 全部 TCP提供可靠的運輸層。它使用的方法之中的一個就是確認從還有一端收到的數據。但數據和確認都有可能會丟失。TCP通過在發送時設置一個定時器來解決這樣的問題。假設當定時器溢出時還沒有收到確認,它就重傳該數據。對於實現
《大數據日知錄:架構與算法》讀書筆記(多圖)
打通 導論 ges wid 技術分享 二次 思維 知識點 很好 第二次讀這本書,這次是精讀,畫了思維導圖。書很好,完整的知識結構和由淺入深的介紹,非常全面以至於知識點都梳理了三天。 作為導論式的總覽,對大數據領域有了個總體的認識,接下來可以更針對性地加強和實踐。 總體上
《javascript設計模式》讀書筆記二(封裝和隱藏信息)
mil del ims 是你 信息 私有屬性 bsp delet urn 1.為什麽要封裝和信息隱藏 做過編程的朋友們知道“耦合”這個詞。事實上封裝的效果就是為了解耦,讓類和類之間沒有太多的聯系,防止某一天改動某一類的時候,產生“多米骨諾牌效應”。 我們能夠把信息隱