
如何為Hadoop叢集選擇正確的硬體
當我們想搭建一個Hadoop大資料平臺時,碰到的第一個問題就是我們到底該如何選擇硬體。
雖然Hadoop被設計為可以執行在標準的X86硬體上,但在選擇具體伺服器配置的時候其實沒那麼簡單。為已知的工作負載或者應用場景選擇硬體時,往往都要綜合考慮效能因素和價效比,才能選擇合適的硬體。比如,對於IO密集型的工作負載,使用者往往需要為每個CPU core匹配更多的儲存或更高的吞吐(more spindles per core)。
通過本文,您將學習到如何根據工作負載來選擇硬體,包括一些其他您需要考慮的因素。

1.計算和儲存
過去的十年,業界基本已經形成了刀片和SANs(Storage Area Networks)的標準,從而滿足網格和處理密集型的工作負載。這種模式對於許多標準應用(比如Web伺服器,應用伺服器,較小的結構化資料和資料搬運)還都是適用的,但是隨著資料量和使用者資料的增長,基礎設施的需求也發生了變化。Web伺服器現在已經有了快取層,資料庫藉助本地磁碟開始支援海量併發,資料搬運的壓力迫使我們需要更多的在本地處理資料。
“很多人在搭建Hadoop叢集時都沒有去真正瞭解過工作負載”
硬體供應商更新了對應的產品來滿足相應的需求,包括儲存刀片,SAS(Serial Attached SCSI)交換機,外掛的SATA陣列和容量更大的機架。然而,Hadoop是基於一個全新的儲存和處理資料的方式,儘量避免資料傳輸。Hadoop通過軟體層來實現大資料的處理以及可靠性,而不像一個SAN儲存所有資料,如果計算則傳輸到一系列刀片進行計算。
Hadoop將資料分散式儲存在各臺伺服器上,使用檔案副本來保證資料不丟以及容錯。這樣一個計算請求可以直接分發到儲存資料的相應伺服器並開始進行本地計算。由於Hadoop叢集的每臺節點都會儲存和處理資料,所以你就需要考慮怎樣為叢集裡的這些伺服器選擇合適的配置。
2.為什麼跟工作負載有關係
在很多情況下,MapReduce/Spark都會遭遇瓶頸,比如從磁碟或者網路讀取資料(IO-bound的作業),或者在CPU處理大量資料時(CPU-bound的作業)。IO-bound的作業的一個例子是排序,一般需要很少的處理(簡單的比較)卻需要大量的讀寫磁碟。CPU-bound的作業的一個例子是分類(classification),一些資料往往需要很複雜的處理。
典型的IO-bound的工作負載如下:
- 索引(Indexing)
- 分組(Grouping)
- 資料匯入匯出
- 資料傳輸和轉換
典型的CPU-bound工作負載如下:
- 聚類和分類(Clustering/Classification)
- 複雜的文字挖掘
- 自然語言處理
- 特徵提取
我們需要完全瞭解工作負載,才能夠正確的選擇合適的Hadoop硬體。很多人因為從來沒有研究過工作負載,往往會導致Hadoop執行的作業是基於不合適的硬體。此外,一些工作負載往往會受到一些其他的限制。比如因為選擇了壓縮,本應該是IO-bound的工作負載實際卻是CPU-bound的,或者因為演算法選擇不同而使MapReduce或者Spark作業受限。由於這些原因,當您不熟悉未來將要執行的工作負載時,可以選擇一些較為均衡的硬體配置來搭建Hadoop叢集。
接下來我們就可以在叢集中執行一些MapReduce/Spark作業進行基準測試,來分析它們的bound方式。可以通過一些監控工具來確定工作負載的瓶頸。當然Cloudera Manager提供了這個功能,包括CPU,磁碟和網路負載的實時統計資訊。通過Cloudera Manager,當叢集在執行作業時,系統管理員可以通過dashboard很直觀的檢視每臺機器的效能表現。
“第一步是瞭解運維部門管理的硬體。”
除了根據工作負載來選擇硬體外,還可以與硬體廠商一起了解耗電和散熱以節省額外的開支。由於Hadoop是執行在數十,數百甚至數千個節點上,儘可能多的考慮方方面面都可以節省成本。每個硬體廠商都提供了專門的工具來監控耗電和散熱,以及如何改良的最佳實踐。
3.為CDH叢集挑選硬體
在挑選硬體的時候,第一步是瞭解您的運維部門所管理的硬體型別。運維部門往往傾向於選擇他們熟悉的硬體。但是,如果您是在搭建一個新的叢集,並且無法準確的預測叢集未來的工作負載,我們建議您還是選擇適合Hadoop較為均衡的硬體。
一個Hadoop叢集通常有4個角色:NameNode(和Standby NameNode),ResourceManager,NodeManager和DataNode。叢集中的絕大多數機器同時是NodeManager和DataNode,既用於資料儲存,又用於資料處理。
以下是較為通用和主流的NodeManager/DataNode配置:
- 12-24塊1-6TB硬碟, JBOD (Just a Bunch Of Disks)
- 2 路8核,2路10核,2路12核的CPU, 主頻至少2-2.5GHz
- 64-512GB記憶體
- 繫結的萬兆網 (儲存越多,網路吞吐就要求越高)
NameNode負責協調叢集上的資料儲存,ResourceManager則是負責協調資料處理。Standby NameNode不應該與NameNode在同一臺機器,但應該選擇與NameNode配置相同的機器。我們建議您為NameNode和ResourceManager選擇企業級的伺服器,具有冗餘電源,以及企業級的RAID1或RAID10磁碟配置。
NameNode需要的記憶體與叢集中儲存的資料塊成正比。我們常用的計算公式是叢集中100萬個塊(HDFS blocks)對應NameNode的1GB記憶體。常見的10-50臺機器規模的叢集,NameNode伺服器的記憶體配置一般選擇128GB,NameNode的堆疊一般配置為32GB或更高。另外建議務必配置NameNode和ResourceManager的HA。
以下是NameNode/ResourceManager及其Standby節點的推薦配置。磁碟的數量取決於你想冗餘備份元資料的份數。
- 4–6個1TB的硬碟,JBOD(1個是OS, 2個是NameNode的FS image [RAID 1], 1個配置給Apache ZooKeeper, 還一個是配置給Journal node)
- 2路6核,2路8核的CPU, 主頻至少2-2.5GHz
- 64-256GB的記憶體
- 繫結的萬兆網
“記住,Hadoop生態系統的設計需考慮並行環境。”
如果預期你的Hadoop叢集未來會超過20臺機器,建議叢集初始規劃就跨兩個機架,每個機櫃都配置櫃頂(TOR,top-of-rack)的10GigE交換機。隨著叢集規模的擴大,跨越多個機架時,我們在機架之上還要配置冗餘的核心交換機,頻寬一般為40GigE,用來連線所有機櫃的櫃頂(TOR)交換機。擁有兩個機架,可以讓運維團隊更好的瞭解機架內以及跨機架的網路通訊需求。Hadoop網路要求可以參考Fayson之前的文章CDH網路要求(Lenovo參考架構)。
當搭建好Hadoop集群后,我們就可以開始識別和整理執行在叢集之上的工作負載,並且為這些工作負載準備基準測試,以定位硬體的瓶頸在哪裡。經過一段時間的基準測試和監控,我們就可以瞭解需要如何增加什麼樣配置的新機器。異構的Hadoop叢集是比較常見的,特別是隨著資料量和用例數量的增加,叢集需要擴容時。所以如果因為前期並不熟悉工作負載,選擇了一些較為通用的伺服器,也並不是不能接受。Cloudera Manager支援伺服器分組,從而使異構叢集配置變的很簡單。
以下是不同的工作負載的常見機器配置:
- Light Processing Configuration,1U的機器,一般為測試,開發或者低要求的場景:2個hex-core CPUs,24-64GB記憶體,8個磁碟(1TB或者2TB)
- Balanced Compute Configuration,均衡或主流的配置,1U/2U的機器:2個hex-core CPUs,48-256GB的記憶體,12-16塊磁碟(1TB-4TB),硬碟為直通掛載
- Storage Heavy Configuration,重儲存的配置,2U的機器:2個hex-core CPUs,48-128GB的記憶體,16-24塊磁碟(2TB-6TB)。這種配置一旦多個節點或者機架故障,將對網路流量造成很大的壓力
- Compute Intensive Configuration,計算密集型的配置,2U的機器:2個hex-core CPUs,64-512GB memory,4-8塊磁碟(1TB-4TB)
注意:以上2路6核為最低的CPU配置,推薦的CPU選擇一般為2路8核,2路10核,2路12核
下圖顯示如何根據工作負載來選擇你的機器:
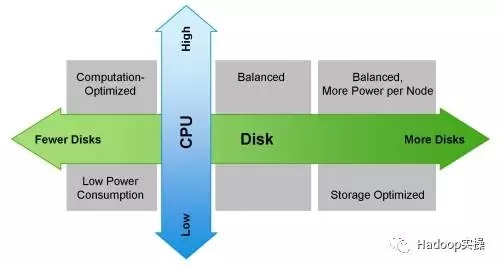
4.其他注意事項
Hadoop生態系統是一個並行環境的系統。在選擇購買處理器時,我們不建議選擇主頻(GHz)最高的晶片,這樣一般都代表了更高電源瓦數(130W+)。因為這會產生兩個問題:更高的功率消耗和需要更多的散熱。較為均衡的選擇是在主頻,價格和核數之間做一個平衡。
當存在產生大量中間結果的應用程式 – 輸出結果資料與輸入資料相當,或者需要較多的網路交換資料時,建議使用繫結的萬兆網,而不是單個萬兆網口。
當計算對記憶體要求比較高的場景,請記住,Java最多使用10%的記憶體來管理虛擬機器。建議嚴格配置Hadoop使用的堆大小的限制,從而避免記憶體交換到磁碟,因為交換會大大影響計算引擎如MapReduce/Spark的效能。
優化記憶體通道寬度也同樣重要。比如,當使用雙通道記憶體時,每臺機器都應配置一對DIMM。使用三通道記憶體時,每個機器都應該具有三倍的DIMM。同樣,四通道DIMM應該被分為四組。
5.Hadoop其他元件的考慮
Hadoop遠遠不止HDFS和MapReduce/Spark,它是一個全面的資料平臺。CDH平臺包含了很多Hadoop生態圈的其他元件。我們在做群集規劃的時候往往還需要考慮HBase,Impala和Solr等。它們都會執行在DataNode上執行,從而保證資料的本地性。
HBase是一個可靠的,列儲存資料庫,提供一致的,低延遲的隨機讀/寫訪問。Cloudera Search通過Solr實現全文檢索,Solr是基於Lucene,CDH很好的集成了Solr Cloud和Apache Tika,從而提供更多的搜尋功能。Apache Impala則可以直接執行在HDFS和HBase之上,提供互動式的低延遲SQL查詢,避免了資料的移動和轉換。
由於GC超時的問題,建議的HBase RegionServer的heap size大小一般為16GB,而不是簡單的越大越好。為了保證HBase實時查詢的SLA,可以通過Cgroups的的方式給HBase分配專門的靜態資源。
Impala是記憶體計算引擎,有時可以用到叢集80%以上的記憶體資源,因此如果要使用Impala,建議每個節點至少有128GB的記憶體。當然也可以通過Impala的動態資源池來對查詢的記憶體或使用者進行限制。
Cloudera Search在做節點規劃時比較有趣,你可以先在一個節點安裝Solr,然後裝載一些文件,建立索引,並以你期望的方式進行查詢。然後繼續裝載,直到索引建立以及查詢響應超過了你的預期,這個時候你就需要考慮擴充套件了。單個節點Solr的這些資料可以給你提供一些規劃時的參考,但不包括複製因子因素。
6.總結
選擇並採購Hadoop硬體時需要一些基準測試,應用場景測試或者Poc,以充分了解你所在企業的工作負載情況。但Hadoop叢集也支援異構的硬體配置,所以如果在不瞭解工作負載的情況下,建議選擇較為均衡的硬體配置。還需要注意一點,Hadoop平臺往往都會使用多種元件,資源的使用情況往往都會不一樣,專注於多租戶的設計包括安全管理,資源隔離和分配,將會是你成功的關鍵。