
[目標檢測|SSD實踐一]caffe-ssd基線
本次實驗利用caffe-ssd跑出了基線,主要從以下幾個方向總結。
- caffe-ssd的編譯
- caffe-ssd demo演示
- 自建資料集的資料準備
- fineTuning
- 測試分析
一、caffe基線實驗
1.1 CPU版安裝
// 依照 caffe - cpu 的安裝裝好依賴包,比如Python什麼的
// 參照 caffe - cpu部落格
https://github.com/weiliu89/caffe/tree/ssd
caffe - cpu 安裝
首先依照 caffe - cpu 的安裝裝好依賴包,比如Python什麼的。
生成Makefile.config
cp Makefile.config.example Makefile.config
修改Makefile.config的相關配置
//Step1: 取消CPU的註釋 8
CPU-ONLY := 1
//Step2: 取消BLAS的 47行
# BLAS := open
BLAS := atlas
BLAS是一個矩陣相乘的庫
BLAS (Basic Linear Algebra Subprograms)
Caffe推薦的BLAS(Basic Linear Algebra
Subprograms)有三個選擇ATLAS,Intel
MKL,OpenBLAS。其中ATLAS是caffe是預設選擇開源免費,如果沒有安裝CUDA的不太推薦使用,因為CPU多執行緒的支援不太好;Intel
MKL是商業庫要收費,我沒有試過但caffe的作者安裝的是這個庫,估計效果應該是最好的;
OpenBLAS開源免費,支援CPU多執行緒,我安裝的就是這個。
//安裝ATLS 編譯caffe - ssd
// Step:1 make -j8
make -j8
// Step:2 Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
vim ~/.bashrc
export PYTHONPATH: " /your caffe root/python/ "
source ~/.bashrc
// Step3: make py
make 1.2 GPU版安裝
1. 拷貝Makefile.config
cp Makefile.config.example Makefile.config
2. fix hdf5 naming problem
==report problem:==
./include/caffe/util/hdf5.hpp:6:18: fatal error: hdf5.h: No such file or directory
==Append== /usr/include/hdf5/serial/ to INCLUDE_DIRS at line 85 in Makefile.config.
--- INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
+++ INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/
Modify hdf5_hl and hdf5 to hdf5_serial_hl and hdf5_serial at line 173 in Makefile
--- LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5
+++ LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial3. 接著編譯
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
# 這裡報錯:找不到openblas的庫,所以需要自己安裝
AR -o .build_release/lib/libcaffe.a
LD -o .build_release/lib/libcaffe.so.1.0.0-rc3
/usr/bin/ld: cannot find -lopenblas
collect2: error: ld returned 1 exit status
Makefile:568: recipe for target '.build_release/lib/libcaffe.so.1.0.0-rc3' failed
make: *** [.build_release/lib/libcaffe.so.1.0.0-rc3] Error 1
make py
make test -j8
# (Optional)
make runtest -j8
安裝openblas
#如果有sudo許可權:
sudo apt-get install libopenblas-base
#否則
github下載原始碼
make -j 8
安裝成功後,繼續在終端輸入安裝目錄:
make install PREFIX=your_directory
根據具體的安裝路徑設定:
export LD_LIBRARY_PATH=/opt/OpenBLAS/lib4. 測試
==錯誤1==
進入caffe/python路徑
進入Python,import caffe
可能會出現如下錯誤:
ImportError: /home/chenguang/soft/anaconda2/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.21' not found (required by caffe/_caffe.so)
這個錯誤是因為缺少libgcc。
所以可以用conda安裝libgcc
conda install libgcc==錯誤2==
編譯完pycaffe後。
import caffe
ImportError: /caffe-ssd/python/caffe/../../build/lib/libcaffe.so.1.0.0-rc3 undefined symbol: ZN5cv6image....這個原因是anaconda環境的問題,詳情參見anaconda 安裝caffe,刪除anaconda,用預設的Python進行編譯。
猜想是由於anaconda opencv安裝的問題。先編譯caffe後安裝opencv。
==錯誤3==
編譯make all時發生如下錯誤。
‘type name’ declared as function returning an array
這是由於gcc版本和g++版本太低的原因,只需要升級到5以上就可以了。詳情參見gcc和g++的版本升級。
2. caffe-ssd demo演示
在github上,作者給出了ssd在Pascal VOC上的資料準備方法、訓練和測評方法。這裡我們也按照這個思路進行詳盡闡述。
2.1 資料集分析
在進行資料準備之前,我們先分析一下Pascal VOC資料集,以便之後分析得到整理資料的工作。個人認為這一部分還是非常重要的。
VOC資料是一個比較詳盡的資料集,現在主要是分為兩個部分,一個是VOC2007,一個是VOC2012。這個資料集能幹什麼呢?這個資料集能做影象分類、定位與檢測、影象語義分割。下面我們以VOC2012為例,分析一下這個資料集。如下圖所示是資料集的檔案結構。
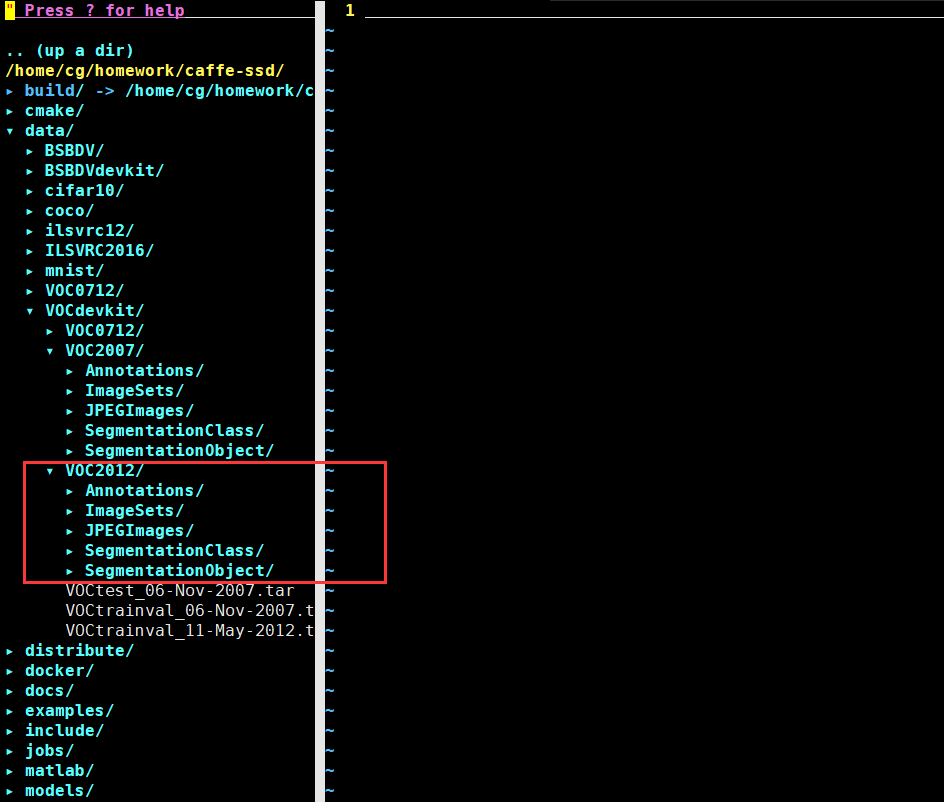
Annotation:
顧名思義,就是標註的意思。這個資料夾裡面儲存了該資料集所有影象的標註資訊。如下圖所示是每個影象的標註資訊。
1. <annotation>
2. <folder>VOC2012</folder>
3. <filename>2007_000027.jpg</filename>
4. <source>
5. <database>The VOC2007 Database</database>
6. <annotation>PASCAL VOC2007</annotation>
7. <image>flickr</image>
8. </source>
9. <size>
10. <width>486</width>
11. <height>500</height> # 影象大小
12. <depth>3</depth>
13. </size>
14. <segmented>0</segmented>
15. <object>
16. <name>person</name>
17. <pose>Unspecified</pose>
18. <truncated>0</truncated>
19. <difficult>0</difficult>
20. # 一個 bounding box的位置,而且object是人
21. <bndbox>
22. <xmin>174</xmin>
23. <ymin>101</ymin>
24. <xmax>349</xmax>
25. <ymax>351</ymax>
26. </bndbox>
27. <part>
28. <name>head</name>
29. <bndbox>
30. <xmin>169</xmin>
31. <ymin>104</ymin>
32. <xmax>209</xmax>
33. <ymax>146</ymax>
34. </bndbox>
35. </part>
ImageSets:
這個檔案裡主要按照用途(影象分類、目標檢測、姿態估計、影象語義分割)進行分類,每個裡面內容主要是按照檔名對資料集進行劃分成訓練集和訓練集。存為了txt文字格式。
2.2 資料準備
Step1:首先按照作者的提示,download資料集。如下圖所示。
1. # Download the data.
2. cd $HOME/data
3. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
4. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
5. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
6. # Extract the data.
7. tar -xvf VOCtrainval_11-May-2012.tar
8. tar -xvf VOCtrainval_06-Nov-2007.tar
9. tar -xvf VOCtest_06-Nov-2007.tar
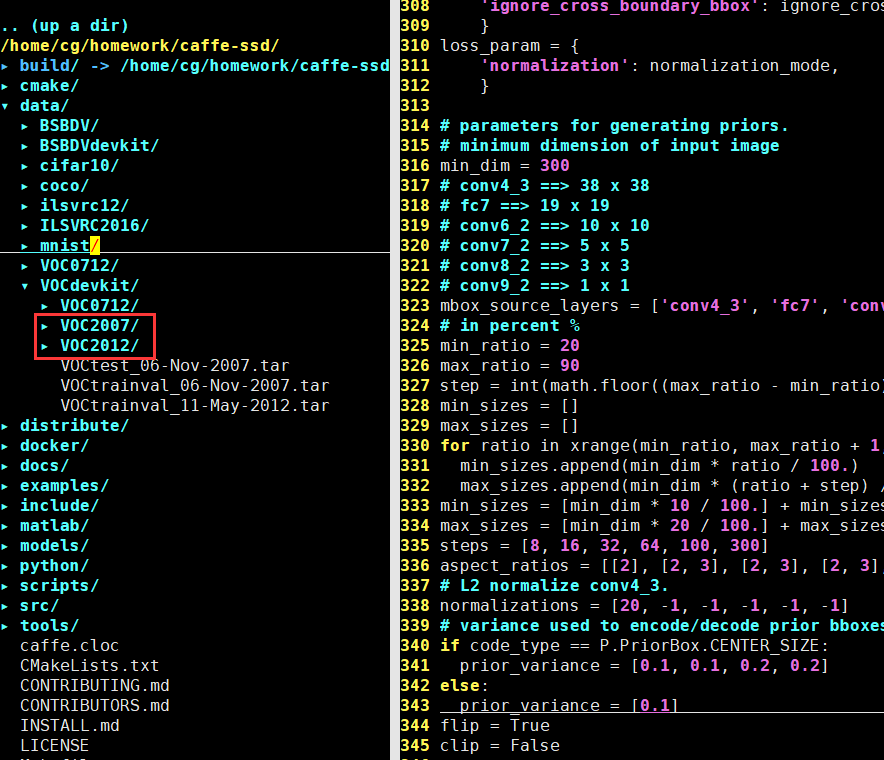
最後解壓後生成如下圖所示的檔案結構,在生成VOCdevkit以
及下面的兩個VOC2007和VOC2013資料夾。
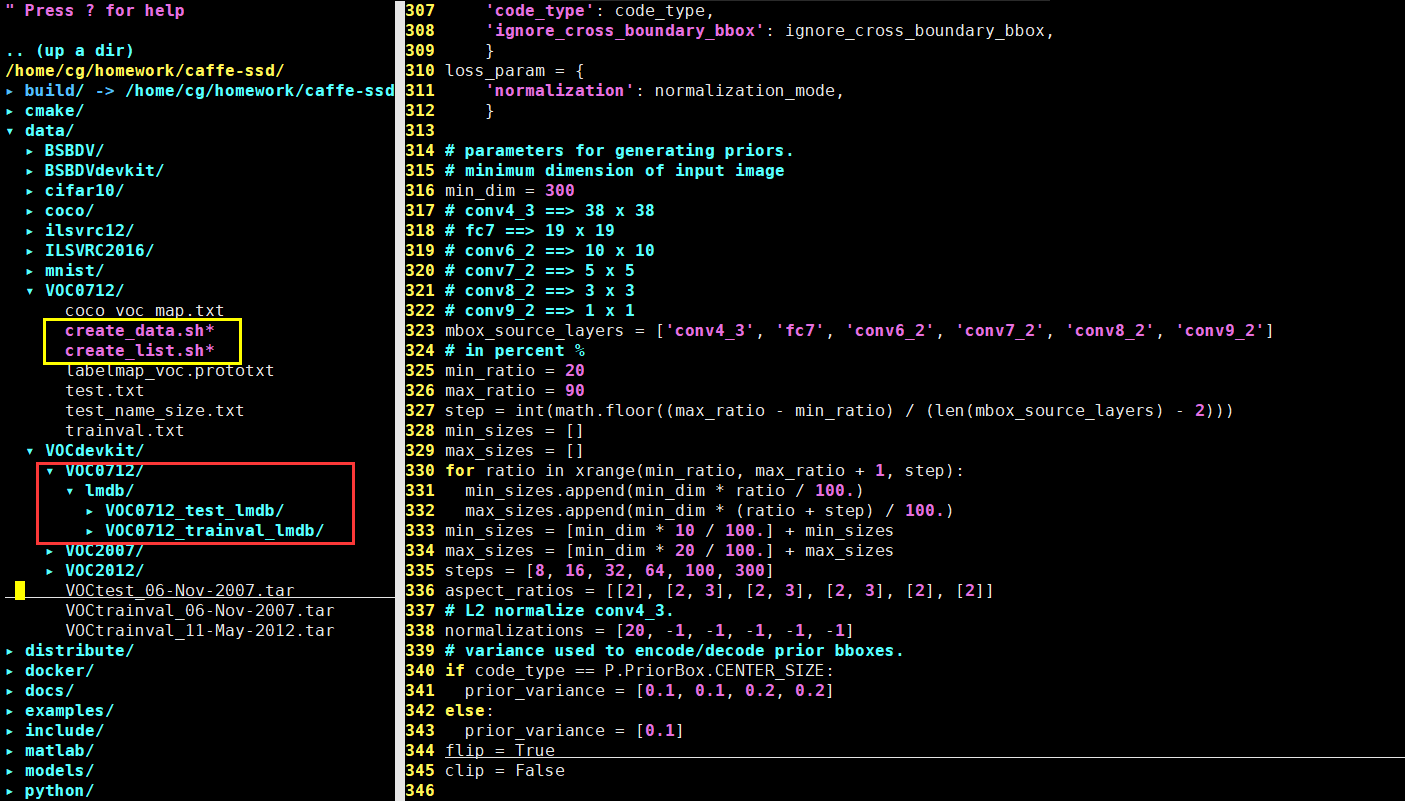
Step2:生成LMDB file
1. cd $CAFFE_ROOT
2. # Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
3. ./data/VOC0712/create_list.sh
4. # You can modify the parameters in create_data.sh if needed.
5. # It will create lmdb files for trainval and test with encoded original image:
6. # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
7. # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
8. # and make soft links at examples/VOC0712/
9. ./data/VOC0712/create_data.sh
執行如上程式碼,將在VOCdevkit中生成LMDB file,一個是test文
件,一個是train。
Step3:訓練模型下載
因為時間和機器有限,我們直接可以執行demo,看看效果(我們自己訓練的效果也不一定有人家在coco+Pascal VOC上訓練得好)。在github上有資料集,下載07++12+coco: SSD300*, SSD512*.下載好後存放在model下。
1. models/VGGNet 具體結構如下所示。
2.3 執行測試
經過上述準備後就可以進行測試了,我們用作者已經訓練好的模型,加上作者寫的指令碼。
1. # If you would like to test a model you trained, you can do:
2. python examples/ssd/score_ssd_pascal.py
但是我們準備的模型和資料夾名字可能不同,所以需要在score_ssd_pascal.py做相應的更改。具體請詳情看指令碼。如下所示就是執行的結果。
1. I1214 11:23:19.188825 54587 solver.cpp:75] Solver scaffolding done.
2. I1214 11:23:19.192239 54587 caffe.cpp:155] Finetuning from models/VGGNet/VOC0712Plus/SSD_300x300_ft/VGG_VOC0712Plus_SSD_300x300_ft_iter_160000.caffemodel
3. I1214 11:23:20.062537 54587 net.cpp:761] Ignoring source layer mbox_loss
4. I1214 11:23:20.068641 54587 caffe.cpp:251] Starting Optimization
5. I1214 11:23:20.068656 54587 solver.cpp:294] Solving VGG_VOC0712Plus_SSD_300x300_ft_train
6. I1214 11:23:20.068661 54587 solver.cpp:295] Learning Rate Policy: multistep
7. I1214 11:23:20.175591 54587 solver.cpp:332] Iteration 0, loss = 4.1508
8. I1214 11:23:20.175637 54587 solver.cpp:433] Iteration 0, Testing net (#0)
9. I1214 11:23:20.200440 54587 net.cpp:693] Ignoring source layer mbox_loss
10. I1214 11:25:45.889575 54587 solver.cpp:546] Test net output #0: detection_eval = 0.822876
11. I1214 11:25:45.889817 54587 solver.cpp:337] Optimization Done.
12. I1214 11:25:45.889824 54587 caffe.cpp:254] Optimization Done.
2.4 常見錯誤
2.4.1 記憶體溢位
check failed: error == cudaSuccess (2 vs. 0) out of memory
1. F1214 20:57:45.526288 27356 parallel.cpp:85] Check failed: error == cudaSuccess (2 vs. 0) out of memory
2. *** Check failure stack trace: ***
3. @ 0x7fcf2dcb05cd google::LogMessage::Fail()
4. @ 0x7fcf2dcb2433 google::LogMessage::SendToLog()
5. @ 0x7fcf2dcb015b google::LogMessage::Flush()
6. @ 0x7fcf2dcb2e1e google::LogMessageFatal::~LogMessageFatal()
7. @ 0x7fcf2e58d3b5 caffe::GPUParams<>::GPUParams()
8. @ 0x7fcf2e58e109 caffe::P2PSync<>::P2PSync()
9. @ 0x40ab33 train()
10. @ 0x407350 main
11. @ 0x7fcf2cc19830 __libc_start_main
12. @ 0x407b79 _start
13. @ (nil) (unknown)
14. Aborted (core dumped)
這是由於GPU視訊記憶體不夠導致的,有幾個解決方案。
- 如果是現在有程式在跑而佔用了記憶體,可以殺程序
- 更改配置檔案的batch_size和accum_batch_size
1. #Divide the mini-batch to different GPUs.
2. #batch_size = 32
3. #accum_batch_size = 32
4. batch_size = 8
5. accum_batch_size = 8
6. iter_size = accum_batch_size / batch_size
7. solver_mode = P.Solver.CPU
8. device_id = 0
2.4.2 caffe 路徑編譯
1. [[email protected] caffe]$ sh create_lmdbdata_scenetext.sh
2. Traceback (most recent call last):
3. File "/data/home/lisiqi/my_SSD/caffe/scripts/create_annoset.py", line 7, in <module>
4. from caffe.proto import caffe_pb2
5. ImportError: No module named caffe.proto
6. Traceback (most recent call last):
7. File "/data/home/lisiqi/my_SSD/caffe/scripts/create_annoset.py", line 7, in <module>
8. from caffe.proto import caffe_pb2
9. ImportError: No module named caffe.proto
可能原因:這種情況一般是沒有把caffe中的和python相關的
內容的路徑新增到python的編譯路徑中。解決辦法:將Python路徑新增到~/.bashrc中,或者在source一下。