
當圖變成了一棵樹(糾結的生成樹)
最小生成樹
經典演算法Kruskal演算法
int cmp(const node &c,const node &d)
{
return c.z<d.z;
}
int find(int x) //路徑壓縮(沒有按秩合併)的並查集
{
if (fa[x]!=x)
fa[x]=find(fa[x]);
return fa[x];
}
int unionn(int f1,int f2)
{
fa[f1]=f2;
}
int doit()
{
int i,j=0;
int tot=0;
for 這裡不得不提一句什麼叫
Kruskal重構樹
Kruskal重構樹可以拿來處理一些最小生成樹的邊權最值問題
形象的理解就是:
Kruskal連邊時並不直接合並兩個並查集
而是新建一個節點x
將兩個點所在子樹都連到x的兒子上
這樣生成的樹有一些十分優美的性質:
1.二叉樹(好吧意義不大)
2.原樹與新樹兩點間路徑上邊權(點權)的最大值相等
3.子節點的邊權小於等於父親節點(大根堆)
4.原樹中兩點之間路徑上邊權的最大值等於新樹上兩點的LCA的點權
看圖理解一下吧
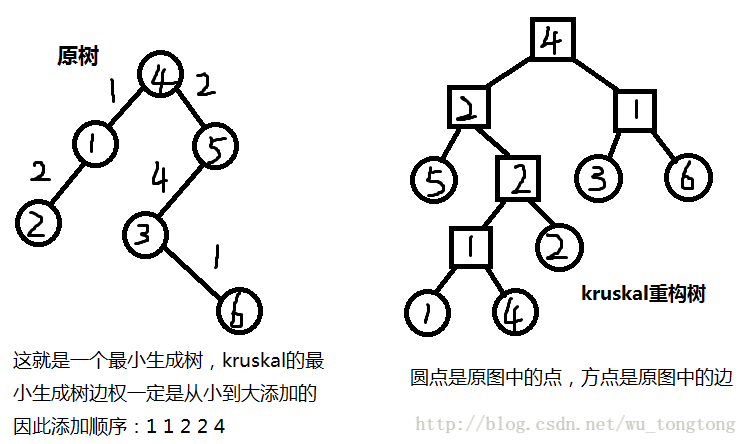
看一下性質的體現:
1.不用說了
2.原樹上2—>5:2,新樹上也是
3.不用說了
4.1—>6:4
確認滿足性質
看一下Kruskal重構樹的構建:
維護一個類似並查集的東西
其中有按秩合併和路徑壓縮
據說這樣並查集的時間複雜度才有保證
樹的記錄方式:爸爸記錄法(只記錄父親)
沒有必要把樹上的邊都連起來
結點深度只要呼叫一個記憶化搜尋就好了
(程式碼還是很醜)
int cmp(const node &a,const node &b)
{
return a.v<b.v;
}
int find(int a) //路徑壓縮
{
if (fa[a]!=a) fa[a]=find(fa[a]);
return fa[a];
}
void kruskal()
{
sort(e+1,e+1+m,cmp);
int i,o=0;
for (int i=1;i<=n;i++) fa[i]=i,size[i]=1;
for (i=1;i<=m;i++)
{
int f1=find(e[i].x);
int f2=find(e[i].y);
if (f1!=f2)
{
if (size[f1]>size[f2]) swap(f1,f2); //按秩合併
fa[f1]=f2; //並查集中的標誌節點,f1連到f2上
size[f2]=max(size[f2],size[f1]+1); //size並查集的深度
f[f1]=f2; //Kruskal重構樹中的父節點
z[f1]=e[i].v; //Kruskal重構樹中的結點值(就是原樹中的邊值)
}
}
}
int getdep(int bh)
{
if (deep[bh]) return deep[bh];
if (!f[bh]) return deep[bh]=1;
return deep[bh]=getdep(f[bh])+1;
}言歸正傳
為了更好地理解最小生成樹,
我們給出兩條性質:
性質一:切割性質
假定所有的邊權均不相同
設S為既非空集也非全集的V(點集)的子集,
邊e是滿足一個端點在S內,另一個端點不在S內的所有邊中權值最小的邊
則圖G的所有生成樹均包含e
性質二:迴路性質
假定所有的邊權均不同
設C是圖G中的任意迴路,邊e是C上權值最大的邊,
則圖G的所有生成樹不包含e
例1:
每對結點間的最小瓶頸路上的最大邊長
解:
求出最小生成樹之後:
一般來說,最樸素的用lca(n^2logn)
然而現在有了更好的做法:
用dfs把最小生成樹變成有根樹,同時計算f(u,v)
當新訪問一個結點的時候,考慮所有訪問過的老結點,
更新f(x,u)=max(f(x,v),w(u,v)),其中v是u的父結點
複雜度O(n^2)
次小生成樹
權值之和排在第二的生成樹
最樸素的求法:像次短路一樣,次小生成樹和最小生成樹不會完全一樣,
我們列舉最小生成樹上的邊並刪除,在剩下的邊裡做Kruskal,得到的生成樹中權值最小的就是次小生成樹
複雜度O(nmα(n,m))
還有一種更好的方法
列舉要加入哪條新邊
在最小生成樹上加上一條邊u-v,圖上會出現一條迴路,我們需要刪除一條邊
所以刪除的邊一定在最小生成樹中u-v的路徑上,
由迴路性質得,刪除的一定是路上的一條最長邊
所以我們像例一中一樣,求出f(u,v)
剩下的部分只需要O(m)的時間(列舉所有m-n+1條邊,O(1)求出新生成樹的權值)
時間複雜度O(n^2)
有向最小生成樹
給定一個有向帶權圖G和其中一個結點u,找到一個以u為根結點,權和最小的生成樹
有向生成樹(directed spanning tree)也叫樹形圖(arborescence)
是指一個類似樹的有向圖,滿足如下條件
- 恰好有一個入度為0的結點,稱為根結點
- 其他結點的入度均為一
- 可以從根節點到達所有其他結點
朱-劉演算法
首先是預處理:
刪除自環並判斷根結點是否可以到達其他結點,如果不是,無解
演算法主過程:
首先,給所有非根結點選擇一條全最小的入邊,
如果選出來的n-1條邊構不成圈,則可以證明這些邊形成了一個最小樹形圖
否則把每個圈縮成一個點,繼續上述過程
縮圈之後,圈上的所有邊都消失了,因此在最終答案的時候需要累加上這些邊的權值
但是這樣就有一個問題:
假設演算法在某次迭代中,把圈C縮成了結點v
則下一次迭代的時候,給v選擇的入邊將與C中的入弧衝突

如圖,圈中已經有了Y—>X,如果收縮之後我們又給X選了一條入邊Z—>X
我們就要刪除Y—>X(每個非根結點只有一個入度)
這等價於把弧Z—>X減小了Y—>X的權值