
Yolo的搭建和在Windows下封裝以及工程應用
概述
最近一直在研究基於深度學習的目標檢測這一塊,之前用過faster_rcnn和R-FCN,相對來說檢測的準確率應該是可以的,但是實際的檢測速度還是很不理想的,考慮實際工程的需求,所以後來想著用yolo來做目標檢測,經過測試發現yolo確實是在檢測速度上有很大的提高,但是除錯了原始碼發現只是yolo的底層檢測函式是滿足實時的要求,而它基於視訊的目標檢測的demo我測試了一下大概是16FPS左右(不知道是不是我的原因,認識了一個網友,說他的測試能達到很高的幀率。),我是完全按照官網步驟測試的。後來測試了一張圖片(1902*1080)發現整個測試的時間大約是0.4s左右,根本無法滿足實時的要求,最後自己優化底層的程式碼並封裝了一下yolo,最後的測試結果是0.06s左右(1902*1080)。下面將詳細描述yolo的整個學習過程和步驟。
yolo的darknet安裝
不管是安裝yolo的v1還是v2的版本過程都是一樣的,其對應的版本都可以去官網上面去下載:
http://pjreddie.com/darknet/yolo/
Yolo是很少依賴第三方庫的,底層都是基於c語言寫的,為了顯示檢測結果和加速檢測時間效率需要安裝opencv和cuda。我主要是以前一直在用caffe,所以之前就安裝過opencv和cuda。這裡我說明一下,網上有的說opencv的版本必須是opencv2.4.10的版本,我個人覺得並不一定,我的linux下面的opencv就是3.0,Windows下面用的是2.4.9的版本都是能用的,cuda用的是7.5的。這裡就不累贅的說opencv和cuda的安裝過程了,要是沒有安裝的可以去網上找找相關的資料(很多的),也可以去看看我之前的部落格。
下面的安裝步驟是基於Linux下面的:
1. 安裝Git
sudo apt-get install git2. 安裝darknet
在你想要安裝的檔案終端下輸入:
git clone http://github.com/pjreddie/darknet.git或者直接下載yolo對應的版本包,直接解壓就行。
切換到darknet檔案下:
執行:
cd darknet修改Makefile檔案,為了使其支援opencv和cuda:
修改如下:
OPENCV=1
NVCC = /usr/local/cuda-7.5/bin/nvcc (這裡的路徑是你cuda的nvcc的路徑)
GPU=1 (要是沒有GPU這裡可以不用,也就是GPU=0,yolo也支援cpu版本只不過速度有點慢) 儲存退出,執行如下:
sudo make –j4等待編譯的完成。編譯完成後可以測試一下安裝是否成功。
測試:這裡測試的命令是v2版本的
sudo ./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg我都是按照官網上的步驟來的,測試的結果如下:
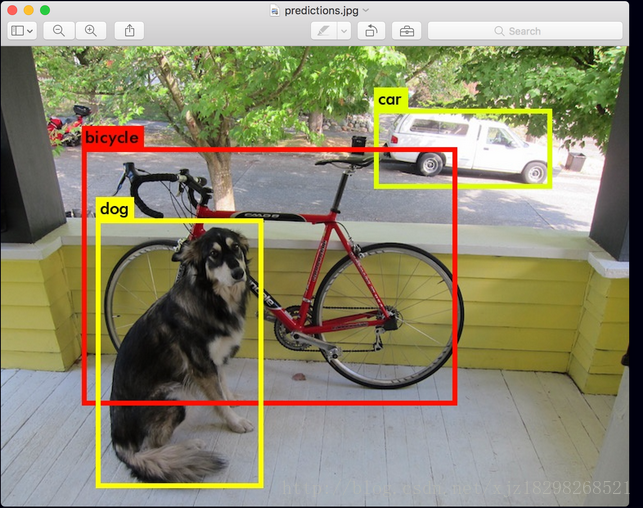
yolo訓練自己的資料(voc2007格式的)
v1和v2兩個版本訓練的過程都是不一樣的,下面將分開介紹。
V1版本的訓練
V1的訓練過程我主要是參考了在目標檢測方面的有很深研究的小鹹魚的部落格:
http://blog.csdn.net/sinat_30071459/article/details/53100791
訓練的步驟內容如下:
由於以前我研究過其它的深度學習的目標檢測的網路模型,用的是也是voc2007格式的資料。所以,我們和作者一樣,將VOC資料集轉成YOLO訓練所需格式,轉換過程很簡單,因為作者提供了轉換的python程式碼:darknet\scripts\voc_label.py
(1)將資料集拷貝到darknet\scripts下
(2)我們開啟voc_label.py並修改該程式碼:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["head","top","bag","down","shoes"] classes根據你的資料集類別改。還有需要注意的是,程式碼裡寫的資料夾是VOCdevkit,我們的可能是VOCdevkit2007,修改成VOCdevkit即可。
然後,終端進入darknet\scripts,執行:
sudo python voc_label.py 此後可以看到,VOCdevkit\VOC2007裡多了一個labels資料夾(如下),裡面有每張圖片的標註檔案(檔案內容形如0 0.488888888889 0.289256198347 0.977777777778 0.429752066116;其中前面的0表示head,1表示top,即前面你寫的classes的順序,以此類推。後面為包圍框資訊,作了轉換)。
darknet\scripts下多了2007_train.txt、2007_val.txt和2007_test.txt三個檔案(如下),這三個檔案是資料集中圖片的路徑。由於yolo訓練只需要一個txt檔案,檔案中包含所有你想要訓練的圖片的路徑,因此,我們可以用2007_train.txt、2007_val.txt和2007_test.txt包含的圖片均用來訓練,因此執行:
sudo cat 2007_* > train.txt 現在,我們已經將資料集中的訓練集和驗證集全都放在一個txt檔案中,這些圖片用來作為YOLO的訓練圖片。
3.修改程式碼
(1) 修改darknet\src\yolo.c
char *voc_names[] = {"head","top","bag","down","shoes"} 改成你的資料集類別;
char *train_images = "/home/luj/darknet/scripts/train.txt";
char *backup_directory = "/home//luj/darknet/backup/"; train_images應該指向我們剛得到的train.txt;backup_directory指向的路徑是訓練過程中生成的weights檔案儲存的路徑(可以在darknet下新建資料夾backup然後指向它)。這兩個路徑按自己系統修改即可。
draw_detections(im, l.side*l.side*l.n, thresh, boxes, probs, voc_names, alphabet, 5);
else if(0==strcmp(argv[2], "demo")) demo(cfg, weights, thresh, cam_index,filename, voc_names,5, frame_skip, prefix);類別數改為你的資料集類別數(例如我的有5類)。
(2)修改darknet\src\yolo_kernels.cu
draw_detections(det, l.side*l.side*l.n, demo_thresh, boxes, probs, voc_names, voc_labels, 5); 最後的引數改為你的資料集類別數(同上)。
(3)修改darknet\cfg\tiny-yolo.cfg
本文以訓練tiny模型為例,因此修改的是tiny-yolo.cfg檔案,其他模型修改類似。
1. output= 735 // 該值為side*side*(2*5+類別數),yolo.train.cfg則是side*side*(3*5+類別數)
2. activation=linear
4. [detection]
5. classes= 5 //資料集類別
6. coords=4
7. rescore=1
8. side=7 /////
9. num=2
10. softmax=0
11. sqrt=1
12. jitter=.2 主要修改兩個地方。side預設是7也可修改
其他的一些引數可以按自己需求修改,比如學習率、max_batches等。
4.下載預訓練模型:
注:經過多次訓練的經驗,我發現有時候不用預訓練的模型,直接進行訓練最後得到的模型的效果也很好。
5.訓練
在dartnet下執行:
./darknet yolo train cfg/tiny-yolo.cfg darknet.conv.weights 一切正常的話,就開始訓練了。
6.測試和結果
執行:
./darknet yolo test cfg/tiny-yolo.cfg backup/tiny-yolo_final.weights 然後輸入一張測試圖片,結果大致如下:

V2版本的訓練
由於V2版本是在yolo v1的基礎上進行了改進,所以v2版本的訓練跟v1版本的不一樣。
這裡參考的部落格是:
http://blog.csdn.net/ch_liu23/article/details/53558549
訓練內容如下:
按darknet的說明編譯好後,接下來在darknet-master/scripts資料夾中新建資料夾VOCdevkit,然後將整個VOC2007資料夾都拷到VOCdevkit資料夾下。
然後,需要利用scripts資料夾中的voc_label.py檔案生成一系列訓練檔案和label,具體操作如下:
首先需要修改voc_label.py中的程式碼,這裡主要修改資料集名,以及類別資訊,我的是VOC2007,並且所有樣本用來訓練,沒有val或test,並且只檢測人,故只有一類目標,因此按如下設定
1. import xml.etree.ElementTree as ET
2. import pickle
3. import os
4. from os import listdir, getcwd
5. from os.path import join
6.
7. #sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
8.
9. #classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
10.
11. sets=[('2007', 'train')]
12. classes = [ "person"]
13.
14.
15. def convert(size, box):
16. dw = 1./size[0]
17. dh = 1./size[1]
18. x = (box[0] + box[1])/2.0
19. y = (box[2] + box[3])/2.0
20. w = box[1] - box[0]
21. h = box[3] - box[2]
22. x = x*dw
23. w = w*dw
24. y = y*dh
25. h = h*dh
26. return (x,y,w,h)
27.
28. def convert_annotation(year, image_id):
29. in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) #(如果使用的不是VOC而是自設定資料集名字,則這裡需要修改)
30. out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') #(同上)
31. tree=ET.parse(in_file)
32. root = tree.getroot()
33. size = root.find('size')
34. w = int(size.find('width').text)
35. h = int(size.find('height').text)
36.
37. for obj in root.iter('object'):
38. difficult = obj.find('difficult').text
39. cls = obj.find('name').text
40. if cls not in classes or int(difficult) == 1:
41. continue
42. cls_id = classes.index(cls)
43. xmlbox = obj.find('bndbox')
44. b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
45. bb = convert((w,h), b)
46. out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
47.
48. wd = getcwd()
49.
50. for year, image_set in sets:
51. if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
52. os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
53. image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
54. list_file = open('%s_%s.txt'%(year, image_set), 'w')
55. for image_id in image_ids:
56. list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
57. convert_annotation(year, image_id)
58. list_file.close() 修改好後在該目錄下執行命令:python voc_label.py,之後則在資料夾scripts\VOCdevkit\VOC2007下生成了資料夾lable,該資料夾下的畫風是這樣的
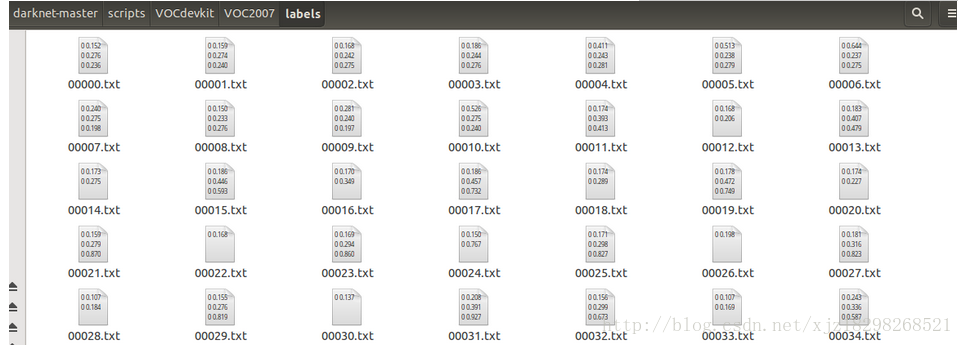
2.配置檔案修改
做好了上述準備,就可以根據不同的網路設定(cfg檔案)來訓練了。在資料夾cfg中有很多cfg檔案,應該跟caffe中的prototxt檔案是一個意思。這裡以tiny-yolo-voc.cfg為例,該網路是yolo-voc的簡版,相對速度會快些。主要修改引數如下
1. [convolutional]
2. size=1
3. stride=1
4. pad=1
5. filters=30 //修改最後一層卷積層核引數個數,計算公式是依舊自己資料的類別數filter=num×(classes + coords + 1)=5×(1+4+1)=30
6. activation=linear
7.
8. [region]
9. anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
10. bias_match=1
11. classes=1 //類別數,本例為1類
12. coords=4
13. num=5
14. softmax=1
15. jitter=.2
16. rescore=1
17.
18. object_scale=5
19. noobject_scale=1
20. class_scale=1
21. coord_scale=1
22.
23. absolute=1
24. thresh = .6
25. random=1 另外也可根據需要修改learning_rate、max_batches等引數。這裡歪個樓吐槽一下其他網路配置,一開始是想用tiny.cfg來訓練的官網作者說它夠小也夠快,但是它的網路配置最後幾層是這樣的畫風:
1. [convolutional]
2. filters=1000
3. size=1
4. stride=1
5. pad=1
6. activation=linear
7.
8. [avgpool]
9.
10. [softmax]
11. groups=1
12.
13. [cost]
14. type=sse 這裡沒有類別數,完全不知道怎麼修改,強行把最後一層卷積層卷積核個數修改又跑不通會出錯,如有大神知道還望賜教。
Back to the point。修改好了cfg檔案之後,就需要修改兩個檔案,首先是data檔案下的voc.names。開啟voc.names檔案可以看到有20類的名稱,本例中只有一類,檢測人,因此將原來所有內容清空,僅寫上person並儲存。名字仍然用這個名字,如果喜歡用其他名字則請按一開始製作自己資料集的時候的名字來修改。
接著需要修改cfg資料夾中的voc.data檔案。也是按自己需求修改,我的修改之後是這樣的畫風:
1. classes= 1 //類別數
2. train = /home/kinglch/darknet-master/scripts/2007_train.txt//訓練樣本的絕對路徑檔案,也就是上文2.1中最後生成的
3. //valid = /home/pjreddie/data/voc/2007_test.txt //本例未用到
4. names = data/voc.names //上一步修改的voc.names檔案
5. backup = /home/kinglch/darknet-master/results/ //指示訓練後生成的權重放在哪 修改後按原名儲存最好,接下來就可以訓練了。
ps:yolo v1中這些細節是直接在原始碼的yolo.c中修改的,原始碼如下
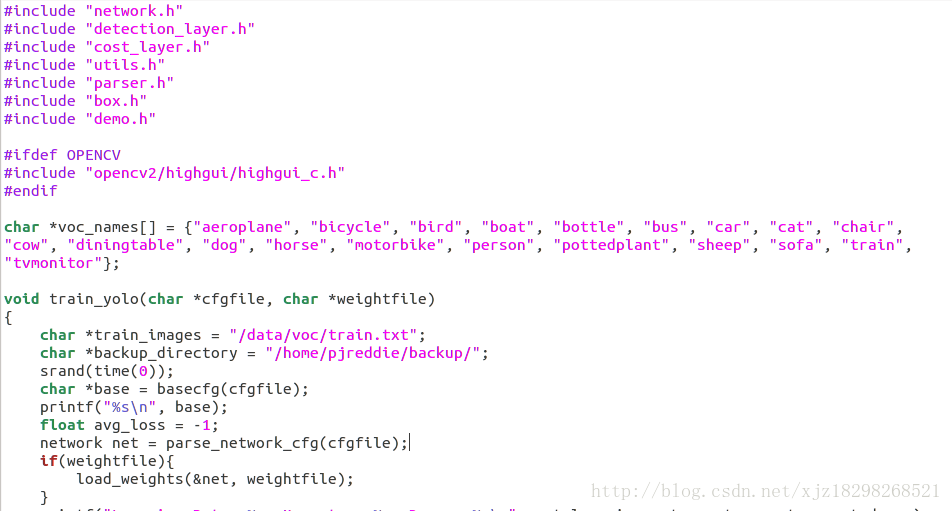
比如這裡的類別,訓練樣本的路徑檔案和模型儲存路徑均在此指定,修改後從新編譯。而yolov2似乎擯棄了這種做法,所以訓練的命令也與v1版本的不一樣。
3.執行訓練
上面完成了就可以命令訓練了,可以在官網上找到一些預訓練的模型作為引數初始值,也可以直接訓練,訓練命令為
/darknet detector train ./cfg/voc.data cfg/tiny-yolo-voc.cfg 如果用官網的預訓練模型darknet.conv.weights做初始化,則訓練命令為
/darknet detector train ./cfg/voc.data .cfg/tiny-yolo-voc.cfg darknet.conv.weights 不過我沒試成功,加上這個模型直接就除了final,不知道啥情況。當然也可以用自己訓練的模型做引數初始化,萬一訓練的時候被人終端了,可以再用訓練好的模型接上去接著訓練。
訓練過程中會根據迭代次數儲存訓練的權重模型,然後就可以拿來測試了,測試的命令同理:
/darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg results/tiny-yolo-voc_6000.weights data/images.jpg

Windows下封裝yolo並呼叫
這裡說明一下:我是參考了小鹹魚的部落格的,也是隻把別人的開源的工程下載下來除錯通了,他實現了yolo的dll封裝並呼叫,也提供了封裝的工程程式碼。但是他的工程只是檢測的一個demo,可能是無法滿足工程上實時的目標檢測。我在他的基礎上改了底層的程式碼和重新封裝了dll。下面我將從兩個方面講解整個工程dll的封裝以及呼叫過程。
小鹹魚工程的實踐過程
這裡貼出小鹹魚的部落格地址:http://blog.csdn.net/sinat_30071459/article/details/53161113
我除錯了他的工程,我主要用的是GPU版,測試的結果跟他是一樣的效果。
* Dll工程直接呼叫的配置過程如下:*
下載他的封裝好的工程,直接配置opencv就行,Opencv的配置過程就和你以前使用opencv的配置過程一樣。至於cuda和pthread的配置,小鹹魚在封裝dll的時候已經配置好了,你直接就可以跑了。
注:我這裡將我自己調DLL的工程上傳到csdn上,工程中的yolo模型主要是對行人進行檢測,直接下載下來就可以,DLL是我基於小鹹魚進行DLL的工程進行修改了,在速度上比之前的快。
下載網址:http://download.csdn.net/detail/xjz18298268521/9780949
(ps:由於工程比較大,CSND上傳的資源大小有限,所以我就把資源上傳到百度雲盤裡了,雲盤的連結和密碼上傳到了csdn上了。)
封裝dll工程的配置過程:
下載他的封裝dll的工程,用vs2013開啟,主要是配置opencv和cuda以及pthread庫。
Opencv的配置過程就和你以前使用opencv的配置過程一樣。cuda和pthread的配置過程幾乎和opencv的是一樣,cuda要配置的標頭檔案和lib檔案的路徑主要是在你安裝的路徑下,pthread的標頭檔案和庫檔案工程中都自帶了,你直接給包含進來就可以了。要是不會可以給我留言。配置大致如下:
1.新增可執行檔案
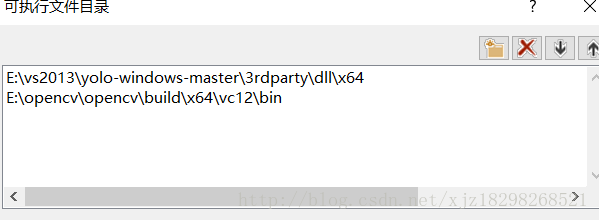
2.新增包含目錄
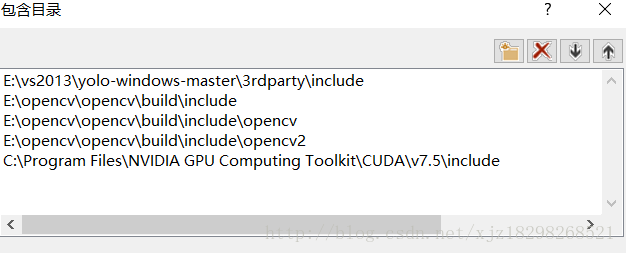
3.新增lib庫檔案
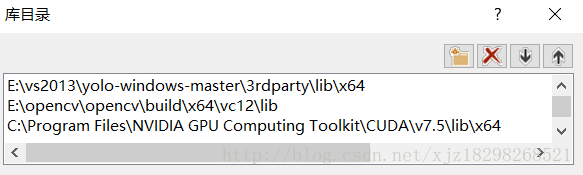
4.新增聯結器中的輸入
5.配置c/c++中的前處理器
自己封裝dll的工程
如果你也除錯了小鹹魚的工程,你會發現他封裝的工程在檢測效率上大約是0.4-0.6s左右一張圖片,無法滿足實時的效果。而且他的工程只是一個test的dll,是遍歷一個資料夾測試檔案下所有的圖片,無法對視訊進行有效的檢測。而且存在一個問題就是他的dll是c語言來寫的,想要用c++來呼叫的話還是比較麻煩的。我修改的思路如下:
**1. 重構底層程式碼:
問題一:**
經過測試發現底層最耗時的是圖片的load和resize,這兩個函式佔用的時間大概是0.4s左右有點耗時;
問題二:
模型每次載入的時間比較長;
解決:
我將模型的初始化單獨摘出來,放在初始化函式中,每次只需要模型載入一次,解決每次載入模型需要消耗的時間,將dll工程封裝為兩個介面,一個用於模型載入,一個是檢測函式。
我重新寫了底層的程式碼,改寫了圖片的load和resize函式,我將這兩個函式的單獨摘出來,放在dll工程外面,也就是呼叫dll的介面是讀入圖片和resize圖片,並利用opencv的指標訪問將圖片資料裝換成yolo檢測模型需要的資料格式,並用指標作為引數傳入進去。
我用一個char指標按照我定義的規則將檢測座標以及數目的結果作為引數傳出來,並按照規則在外面進行解析。外面調介面的函式是基於c++來寫的。
2. 封裝的介面有兩個
一個是yolo模型的載入函式介面,一個是yolo檢測函式的介面,如下圖所示:
