presto原始碼分析(hive的分割槽處理)
阿新 • • 發佈:2019-01-04
修改原始碼時遇到一個問題,就是對分割槽的處理,當遇到join查詢時,如上篇文章presto join連線時的謂詞處理所述,對於某些情況下,如果謂詞帶or,會吧分割槽欄位當做普通欄位處理,不會下推到表掃描處。但是hive是如何處理這種情況的呢?
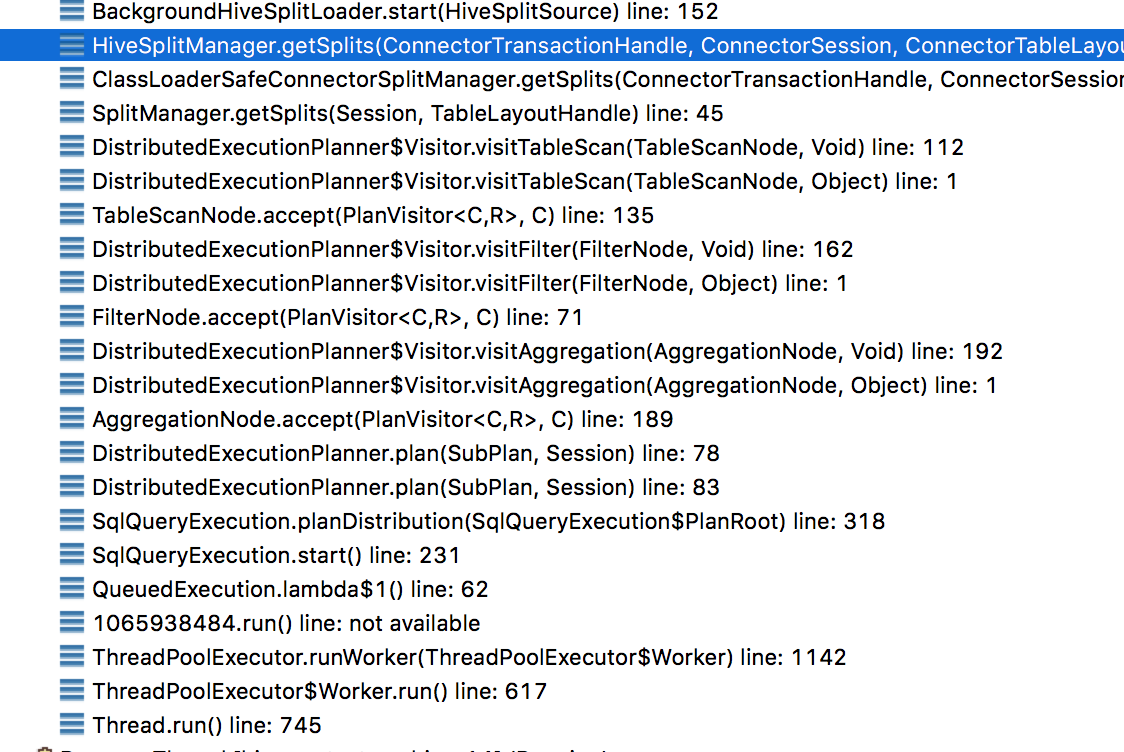
1 hive處理分割槽時的呼叫棧
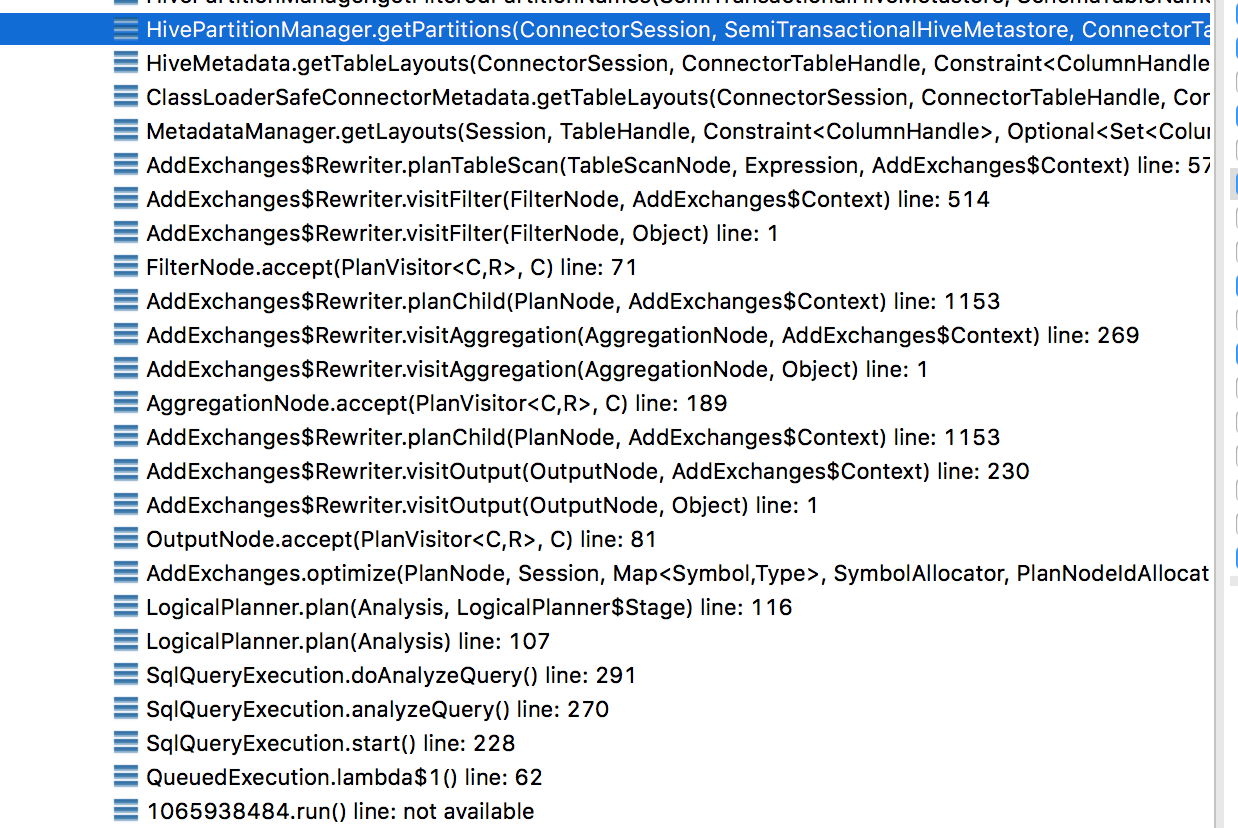
1.1 程式碼分析
HiveTableHandle hiveTableHandle = checkType(tableHandle, HiveTableHandle.class, "tableHandle");
requireNonNull(effectivePredicate, "effectivePredicate is null" getFilteredPartitionNames方法:
private List<String> getFilteredPartitionNames(SemiTransactionalHiveMetastore metastore, SchemaTableName tableName, List<HiveColumnHandle> partitionKeys, TupleDomain<ColumnHandle> effectivePredicate)
{
checkArgument(effectivePredicate.getDomains().isPresent());
List<String> filter = new ArrayList<>();
for (HiveColumnHandle partitionKey : partitionKeys) {//遍歷所有的分割槽欄位,在effectivePredicate中尋找該分割槽欄位的具體條件
Domain domain = effectivePredicate.getDomains().get().get(partitionKey);
if (domain != null && domain.isNullableSingleValue()) {
Object value = domain.getNullableSingleValue();
if (value == null) {
filter.add(HivePartitionKey.HIVE_DEFAULT_DYNAMIC_PARTITION);
}
else if (value instanceof Slice) {
filter.add(((Slice) value).toStringUtf8());
}
else if ((value instanceof Boolean) || (value instanceof Double) || (value instanceof Long)) {
if (assumeCanonicalPartitionKeys) {
filter.add(value.toString());
}
else {
// Hive treats '0', 'false', and 'False' the same. However, the metastore differentiates between these.
filter.add(PARTITION_VALUE_WILDCARD);
}
}
else {
throw new PrestoException(NOT_SUPPORTED, "Only Boolean, Double and Long partition keys are supported");
}
}
else {
filter.add(PARTITION_VALUE_WILDCARD);
}
}
// fetch the partition names
return metastore.getPartitionNamesByParts(tableName.getSchemaName(), tableName.getTableName(), filter)
.orElseThrow(() -> new TableNotFoundException(tableName));
}在獲取到sql謂詞中hive的分割槽資訊後,會構造hiveTablelayoutHandler,其中包含了上邊分析出的partition資訊,用於構造TableScanNode,這個TableScanNode在DistributedPlanner的visitTableScan中進行hive分割槽資料的載入
2 hive分割槽載入
在進行完謂詞中分割槽欄位的處理後,會在後臺啟動hive分割槽資料的載入,呼叫棧如下: