
一次磁碟空間不足引發的思考
阿新 • • 發佈:2019-01-04
2018年7月23週一晚上8點多,我的直接Leader給我打電話聯絡,向我諮詢了上週四(7月19日)生產伺服器磁碟不足導致的幾個重要URl訪問緩慢甚至無法訪問的情況,我當時尋思故障發生的主要原因就是該伺服器磁碟空間不足導致,因為當時接到伺服器磁碟不足10%的預警郵件,但未能及時進行處理,屋漏偏逢連夜雨,該伺服器有一些程式應該是有突然會消耗磁碟空間的隱患,偏偏也發生在那個時刻,最直接的結果就是生產伺服器歇菜34分鐘左右。下面將事後的故障分析原因丟擲來供大家參考:
問題發現
發現時間:【2018-7-19 11:12】
發現方式:
- [ ] 使用者發現
- [ ] 技術人員發現
- [✔] 告警發現
告警方式:
- [ ] 電話告警
- [ ] 郵件告警
- [✔] 簡訊告警
- [ ] 未收到告警
問題描述:
通過360網站監控服務收到異常通知:http://XXXXXXXXXX.com/index 連線被拒絕,與此同時團隊人員接收到生產伺服器磁碟空間不足10%的郵件預警後開始排查問題原因。
產生影響
- 故障開始時間:【2018-7-19 11:54】
故障解決時間:【2018-7-19 12:30】
是否影響使用者:
- [ ] 使用者無感知
- [✔] 使用者感知
- 影響描述:【著重描述是否影響客戶體驗,影響時長、程度】
在該生產伺服器重啟期間,導致相關服務報告中心無法正常載入以致於使用者無法正常登陸,在產品交流群中有一名使用者反饋無法載入介面,但在預警郵件中未接收到有關使用者反饋無法使用的錯誤郵件資訊,因此可判斷為小範圍影響,影響時長總計34分鐘,影響程度低。
問題原因
- 原因一
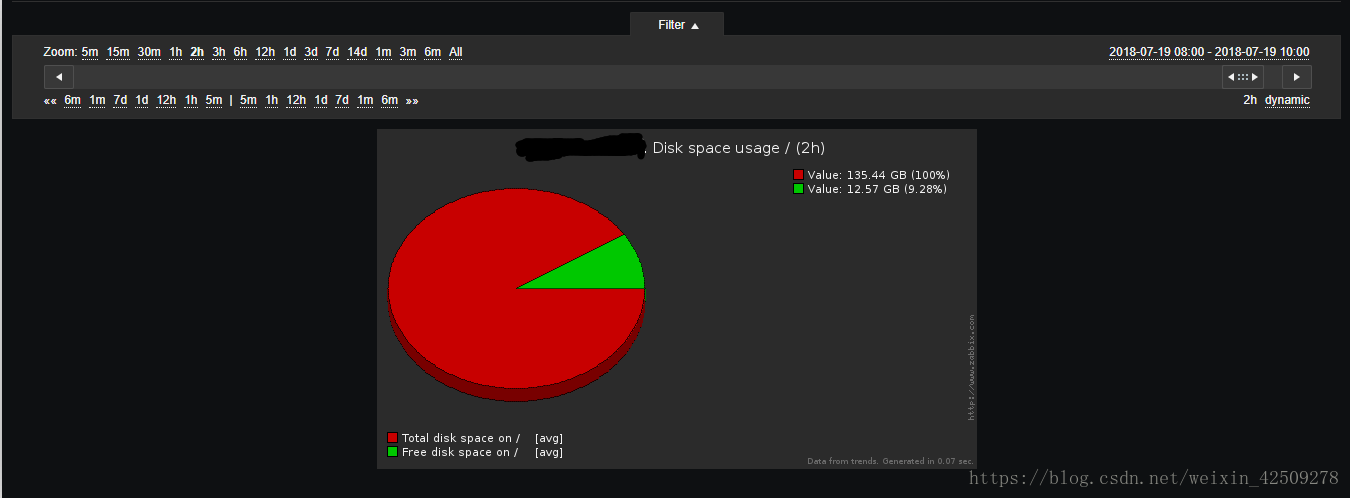
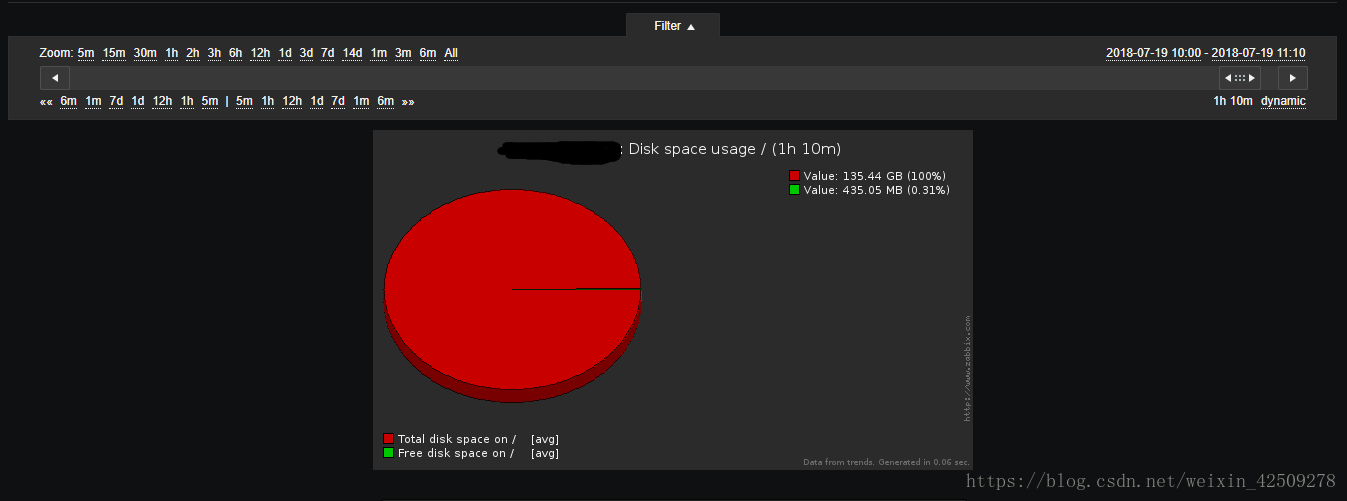
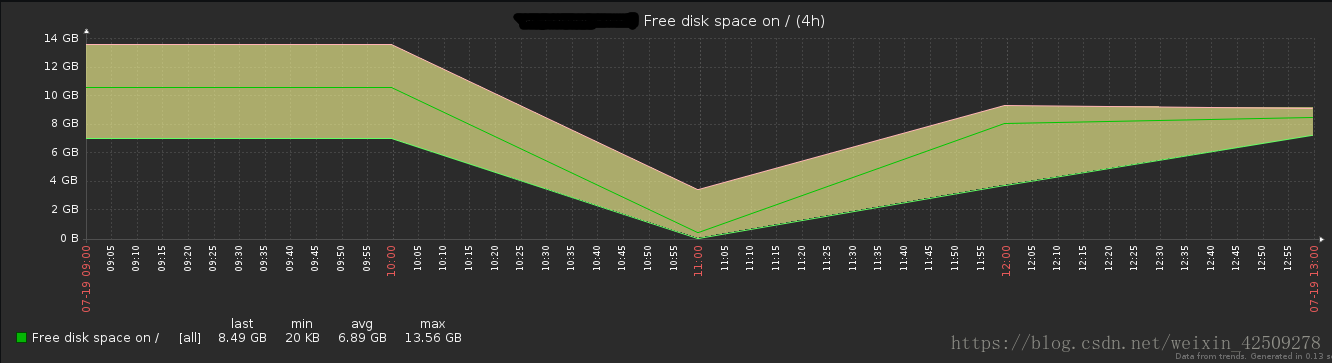
從以上兩圖來看zabbix監控上發現10點的時候磁碟空間已剩9.28%,在11:10分接到inode節點空間不足的報警的時候,即從10點到11:10分的時候磁碟空間只剩下0.31%,從下面的折線圖可以明顯看到從10點到11點有某種原因(由於相關日誌缺失,目前還未找到具體原因)突然佔用掉磁碟空間:
- 原因二
該伺服器磁碟總空間大小為200G,實際可用空間為/dev/sda3(136G),當啟用多個docker容器並且利用的是devicemapper儲存方式會預先佔用磁碟10G空間大小,因此不排除是由於伺服器本身磁碟空間太小不足以支撐生產業務需求的原因
核心技術原因
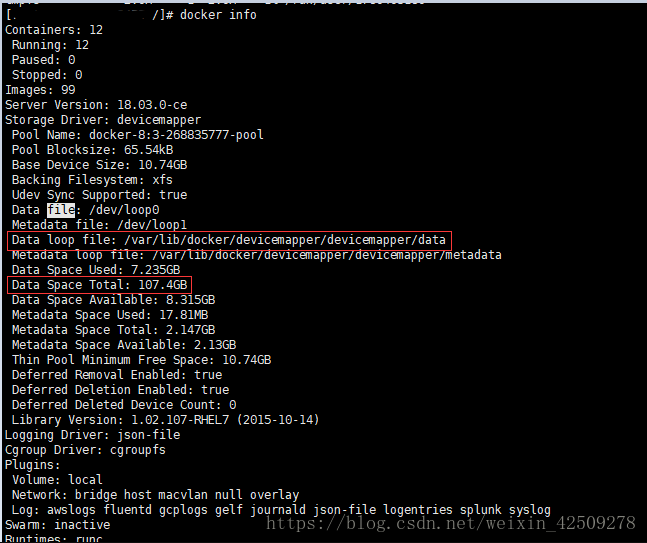
如上圖所示,在此伺服器上啟用的docker容器採用devicemapper方式,此方式會預先佔用伺服器磁碟空間107G,但容器本身實際佔用的空間並未達到107G,所以導致下圖結果:
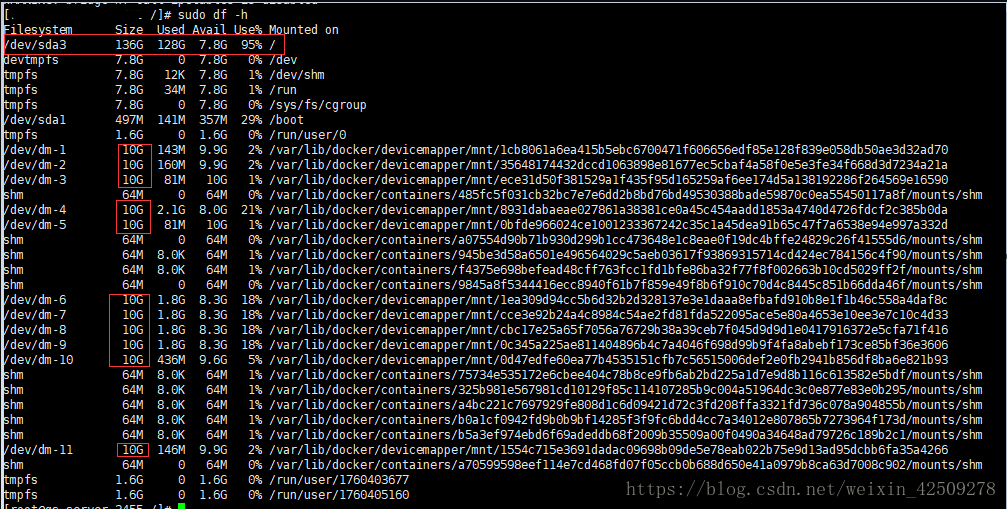
即邏輯上所有檔案佔用磁碟總容量未達到系統統計的已用磁碟容量,但實際上是docker容器預先佔用了磁碟空間
解決方案
目前解決方案是在該伺服器上額外增加一塊容量為500G的磁碟,將docker容器資料檔案掛載到新的磁碟上,以保證生產正常進行,如果要從技術上來改變docker容器儲存方式,還做技術上的拓展,如果其他產品利用到docker技術,可以注意docker容器的儲存方式,去做一個更加適合自身業務的容器。