
探究 | kafka-connector 同步 Elasticsearch速度慢根因分析?
阿新 • • 發佈:2019-01-04
1、kafka同步Elasticsearch的方式
之前博文中也有介紹:
- 方式一:logstash_input_kafka
- 方式二:kafka_connector
- 方式三:spark stream
- 方式四:java程式讀寫自己實現
2、kafka-connector同步kafka到ES
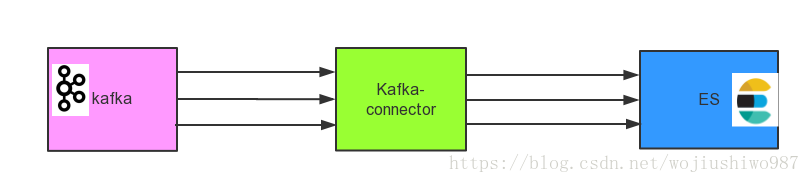
場景一:kafka實時資料流直接通過kafka-connector同步到ES。
場景二:kafka實時資料流需要中間資料處理後再同步到ES。
3、同步慢問題分析?
3.1 針對場景一:
可能的原因:kafka-connector寫入ES速度慢?
可能的應對策略核心:提升ES的寫入速度
分解策略:
- 1)ES副本數設定為0
待寫入完畢後再改成實際副本值。 - 2)調整 bulk 執行緒池和佇列
結合物理機的執行緒大小配置與之匹配的執行緒池和佇列大小。 - 3)增加refresh間隔
預設的refresh的間隔是1s,用index.refresh.interval可以設定。如果設定為預設值1s,則會強迫每秒將記憶體中的資料寫入磁碟中,建立一個新的segment file。這個1s間隔是導致:寫入資料後,需要1s才能看到的原因。
如果該值調大,比如60s,新寫入的資料60s才能看到,這樣就會獲得了較大的寫入吞吐量。
因為:60s的間隔都是寫入記憶體的,每隔60s才會建立一個segment file。 - 4) 調整translog flush 間隔
translog的寫入可以設定,預設是request,每次請求都會寫入磁碟(fsync),這樣就保證所有資料不會丟,但寫入效能會受影響。
如果改成async,則按照配置觸發trangslog寫入磁碟,注意這裡說的只是trangslog本身的寫盤。
translog什麼時候清空?預設是512mb,或30分鐘。這個動作就是flush,同時伴隨著segment提交(寫入磁碟)。flush之後,這段translog的使命就完成了,因為segment已經寫入磁碟,就算故障,也可以從segment檔案恢復。
index.translog.durability 另外,有一個/_flush/sync命令,在做資料節點維護時很有用。其邏輯就是flush translog並且將sync_id同步到各個分片。可以實現快速恢復。
更多策略參考:
3.2 針對場景二:
結合實際場景,從後往前分析?
思考問題:
(1)kafka-connector之前的實時速度怎麼樣?
可以在kafka-connector同步之前列印日誌,看獲取的實時資料實現和當前時刻進行比對。
如果二者差值較大, 則認為資料沒有實時。
可能的原因需要進一步分析。
可能問題1:接入的時候中間可能有異常。
進一步排查kafka 接入的時候的問題。
可能問題2:中間處理慢了。
- 1)排查下,中間有沒有呼叫第三方應用、服務。比如:讀寫資料庫、呼叫第三方分詞等服務。
- 2)考慮增大並行,提升呼叫速度。
(2)kafka-connector寫入到ES的時刻是不是慢了?
如果是,需要統計一段時間,比如1小時、5小時,統計出每秒的寫入速度?
這裡的優化:
- 1)增大並行,kafka-connector寫入ES考慮並行。
- 2)參考場景一中提及的ES方面的優化。
4、小結
問題排查的週期可能會很長,但是要有定力。
從後往前、找到問題的根源,“對症下藥”放得持久療效!
加入知識星球,更短時間更快習得更多幹貨!
2017-07-15 10:25 思於家中床前