
新舊Java MapReduce API的差異
摘錄自 Hadoop權威指南
1、版本區別
Hadoop在0.20.0版本中第一次使用新的API,部分早期的0.20.0版本不支援使用舊的API,但在接下來的1.x和2.x版本中新舊API都可以使用。
新舊API的差異主要有以下幾點:
1. 新的API放在org.apache.hadoop.mapreduce包(和子包)中,舊的API放在org.apache.hadoop.mapred中。
2. 新API傾向於使用 抽象類,而不是介面,更有利於擴充套件。
3. 新API充分使用上下文物件context,允許使用者能與MapReduce系統通訊。例如,新的Context統一了舊API的JobConf、OutputCollector和Reporter的功能。
4. 鍵/值對記錄在這兩類API中都被推給mapper和reducer,除此之外,新的API通過重寫run()方法允許mapper和reducer控制資料執行流程,允許資料按條處理或者分批處理。老的api只在map中允許。
5. 新的API中作業控制由Job類實現,而非舊API中的JobClient類,新的API中刪除了JobClient類。
6. 新增的API實現了配置的統一。舊API通過一個特殊的JobConf物件配置作業,該物件是Hadoop配置物件的一個擴充套件。在新的API中,作業的配置由Configuration來完成。
7. 輸出檔案的命名方式稍有不同。在舊的API中map和reduce的輸出被統一命名為part-nnmm,但在新的API中map的輸出檔名為part-m-nnnnnn,而reduce的輸出檔名為part-r-nnnnn(其中nnnnn是從0開始的表示分塊序號的整數)。
8. 新API中的使用者過載函式被宣告為丟擲異常java.lang.InterruptedException。這意味著可以用程式碼來實現中斷響應。
9.在新的API中,reduce()傳遞的值是java.lang.Iterable型別的,而非舊API中傳遞的java.lang.Iterator型別。這一改變使我們更容易通過java的for-each迴圈結構來迭代這些值。
2、注意問題
如果基於hadoop1版本的打的jar包,在hadoop2下可能會報如下錯誤:
java.lang.IncompatibleClassChangeError: Found interface
org.apache.hadoop.mapreduce.TaskAttemptContext, but class was expected
只需要將程式碼用hadoop2的依賴重新編譯打下jar包
3、新版版本程式碼區別示例
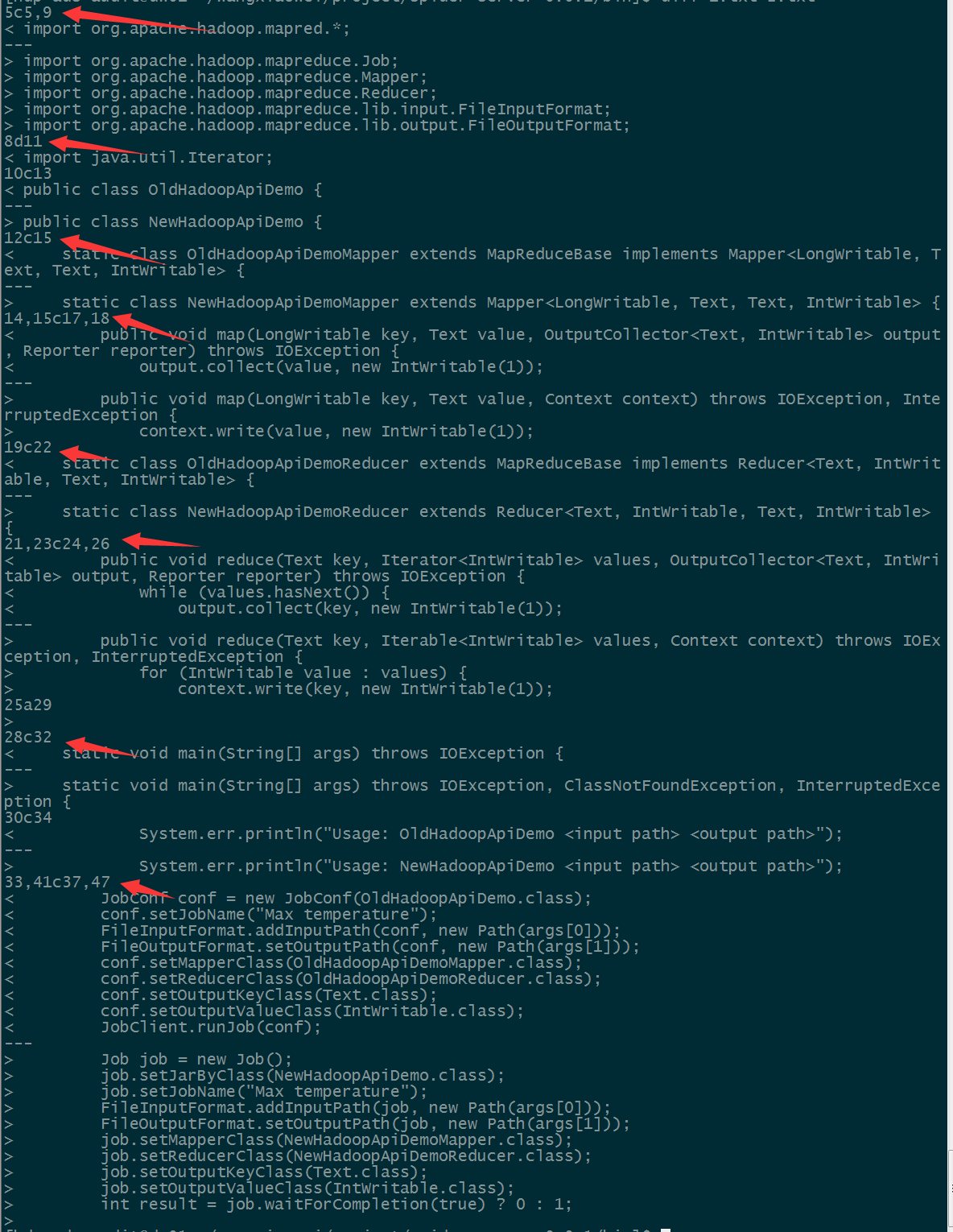
4、示例程式碼-老版API
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import java.io.IOException;
import java.util.Iterator;
public class OldHadoopApiDemo {
static class OldHadoopApiDemoMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
output.collect(value, new IntWritable(1));
}
}
static class OldHadoopApiDemoReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
while (values.hasNext()) {
output.collect(key, new IntWritable(1));
}
}
}
static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println("Usage: OldHadoopApiDemo <input path> <output path>");
System.exit(-1);
}
JobConf conf = new JobConf(OldHadoopApiDemo.class);
conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(OldHadoopApiDemoMapper.class);
conf.setReducerClass(OldHadoopApiDemoReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
JobClient.runJob(conf);
}
}
5、示例程式碼-新版API
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class NewHadoopApiDemo {
static class NewHadoopApiDemoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, new IntWritable(1));
}
}
static class NewHadoopApiDemoReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable value : values) {
context.write(key, new IntWritable(1));
}
}
}
static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("Usage: NewHadoopApiDemo <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(NewHadoopApiDemo.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(NewHadoopApiDemoMapper.class);
job.setReducerClass(NewHadoopApiDemoReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
int result = job.waitForCompletion(true) ? 0 : 1;
}
}