
2017年度開源貢獻榜 國內阿里排第一
摘要:作者依據來自GitHub 2017年度的資料,對近百家公司的開源貢獻資料進行了分析排名,也對自己的分析方法做了說明,以下是譯文。
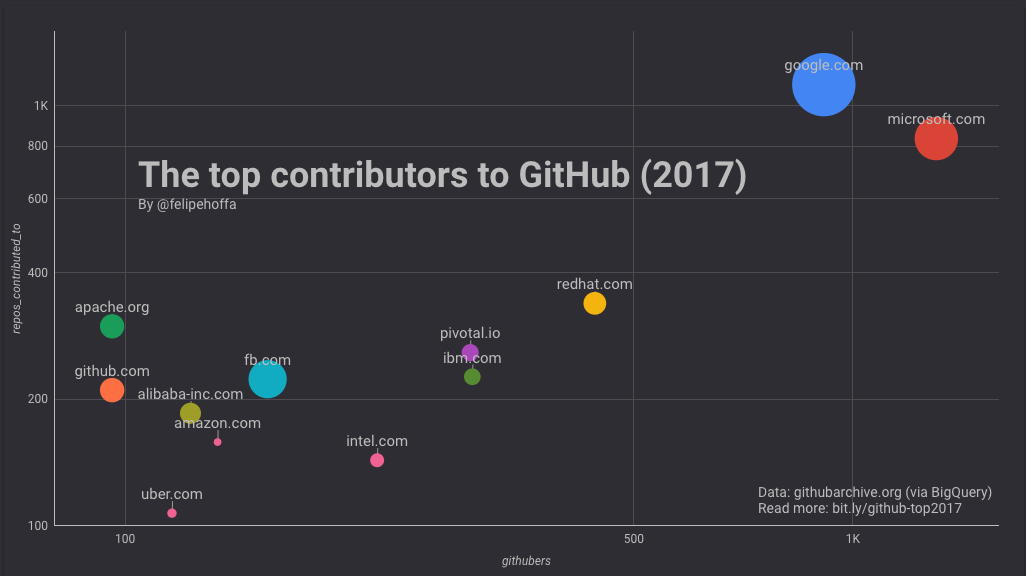
這篇分析,我們將看到GitHub在2017年度發表的所有的pushevents。對每個GitHub使用者,我們不得不盡最大努力推測他們屬於哪個組織。本分析只關注在 2017 年增長超過 20 個 star 的倉庫。
頂級雲提供商的比較
2017年度GitHub資料:
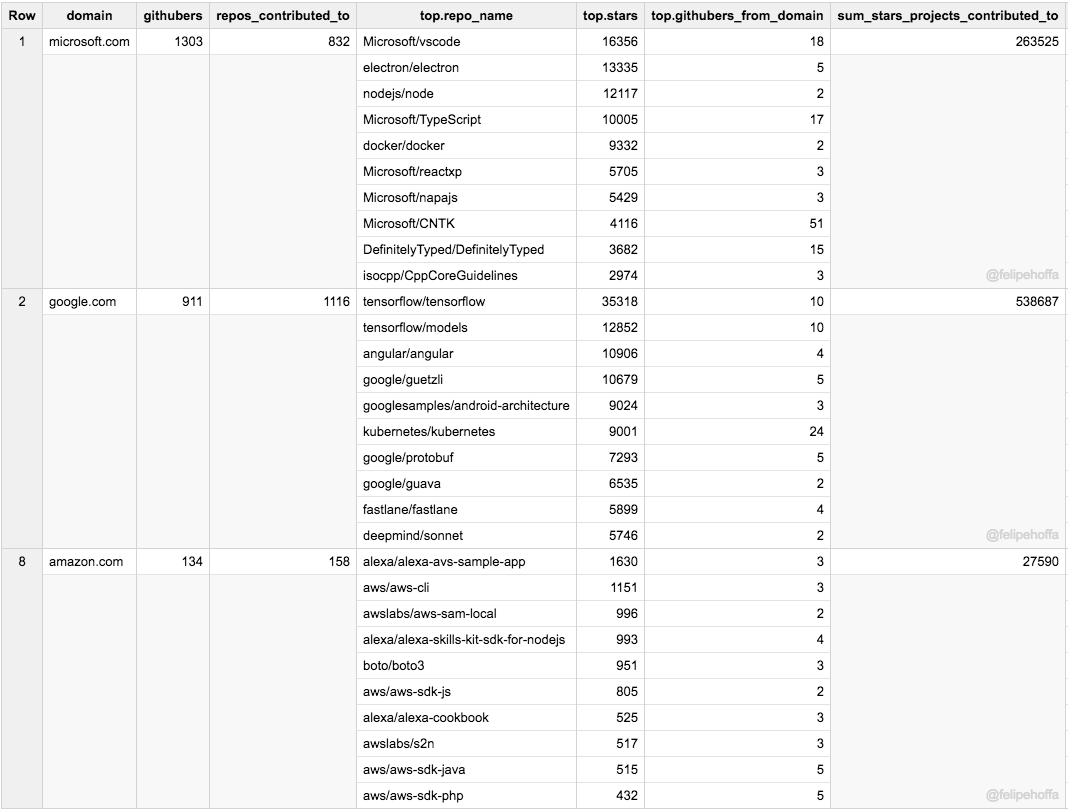
- 微軟大約有 1,300 名員工積極地將程式碼推送到 GitHub 上的 825 個頂級倉庫。
- 谷歌大約有 900 名員工活躍於 GitHub,將程式碼推送到約 1,100 個頂級倉庫。
- 亞馬遜大約有 134 名員工活躍於 GitHub,將程式碼推送到 僅158 個頂級倉庫。
- 並不是所有的專案都是公平的:谷歌員工貢獻的程式碼倉庫比微軟的多了 25%,倉庫獲得的 star 數也更多(530,000 vs 260,000)。亞馬遜倉庫 2017年的 star 總數為 27,000。
RedHat, IBM, Pivotal, Intel, 和 Facebook
亞馬遜遠遠落後於微軟和谷歌,那處在它們之間的有哪些公司呢? 根據貢獻情況排名如下:RedHat,Pivotal,Intel也對GitHub做出了突出貢獻。
注意,下面的表格合併了所有的IBM全球的域名(IBM在各個國家的域名都會帶有各個國家的域名字尾)——雖然各個區域仍舊出現在接下來的表格中。
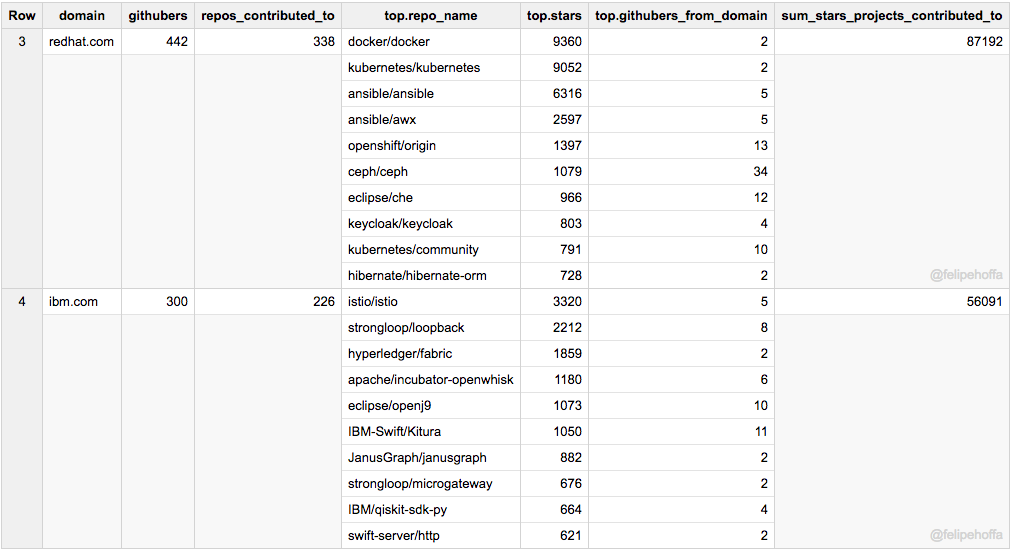
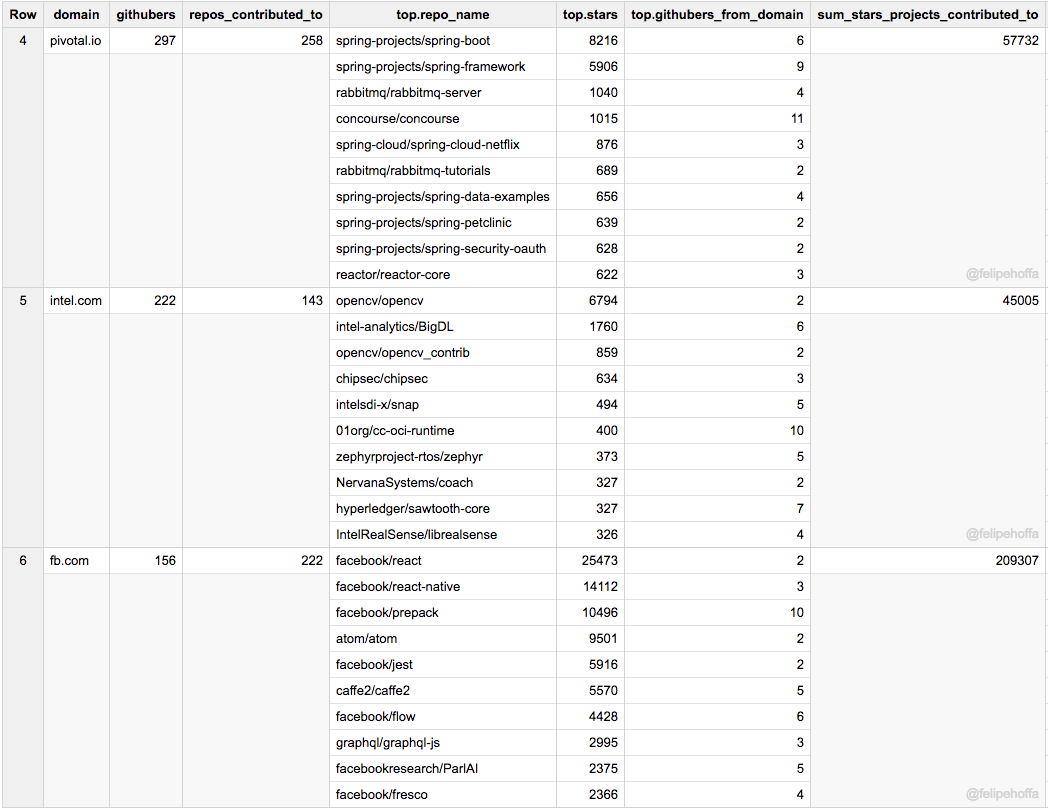
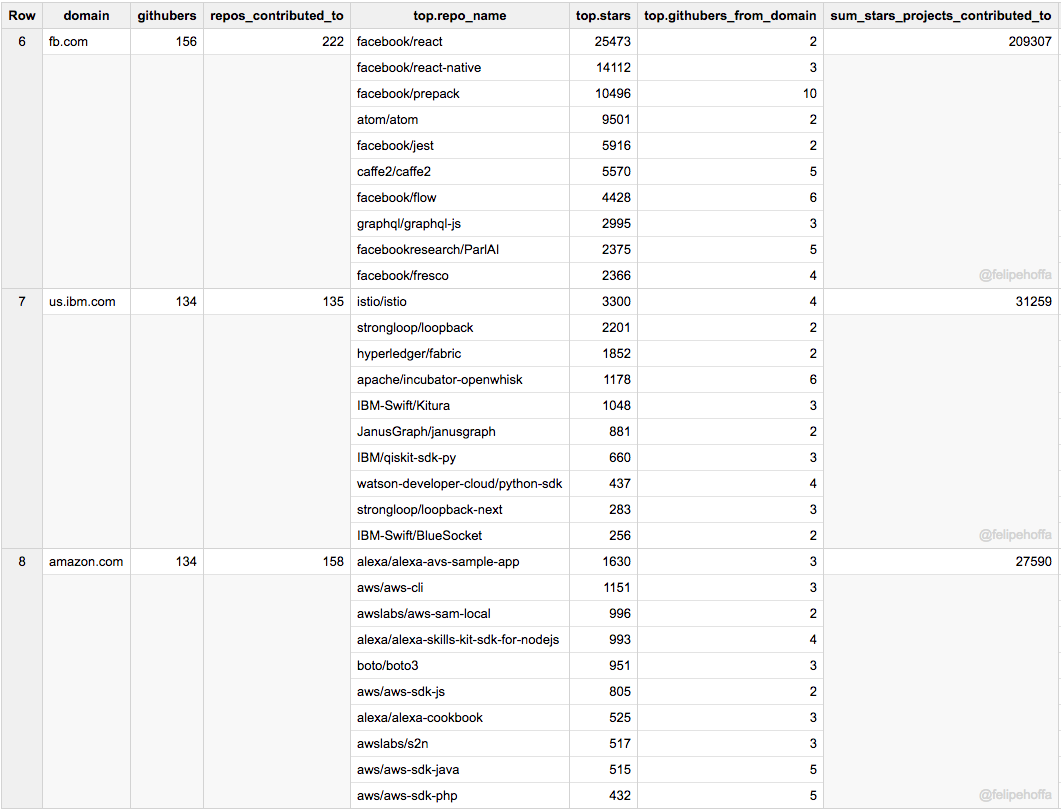
Facebook 和 IBM(US) 的 GitHub 使用者數量與亞馬遜的相似,但它們貢獻的專案收穫到了更多的 star(尤其是 Facebook):
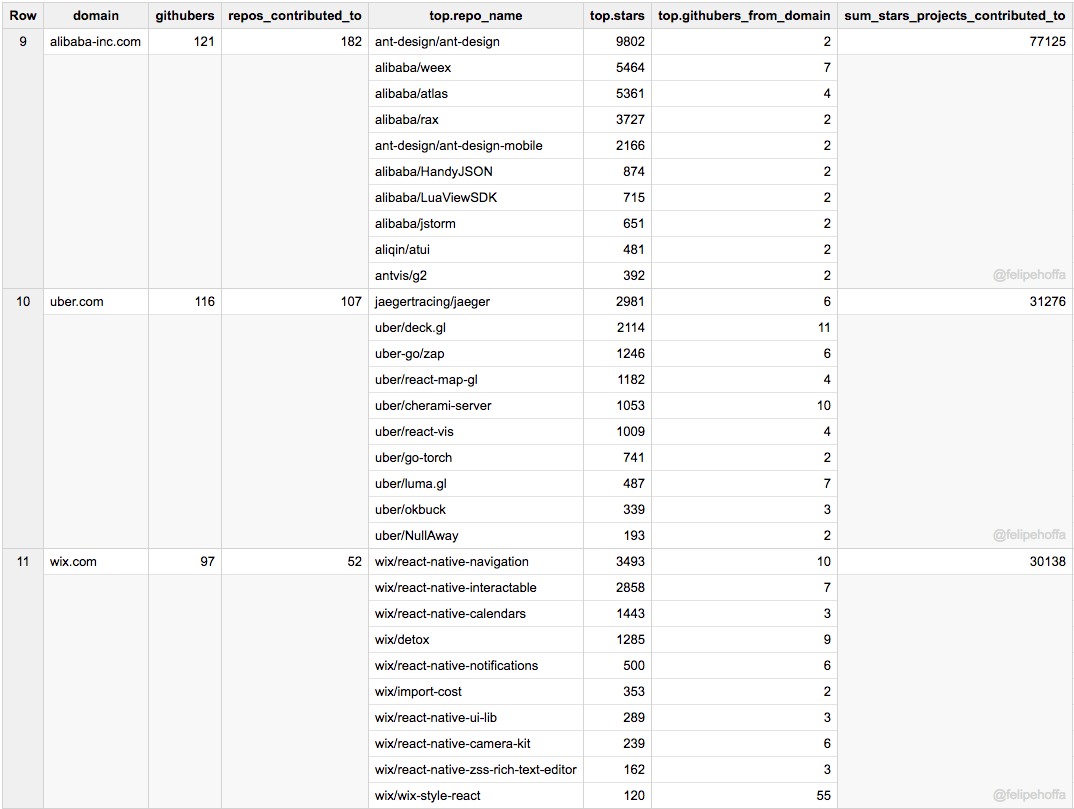
緊接著是Alibaba, Uber, 和 Wix:
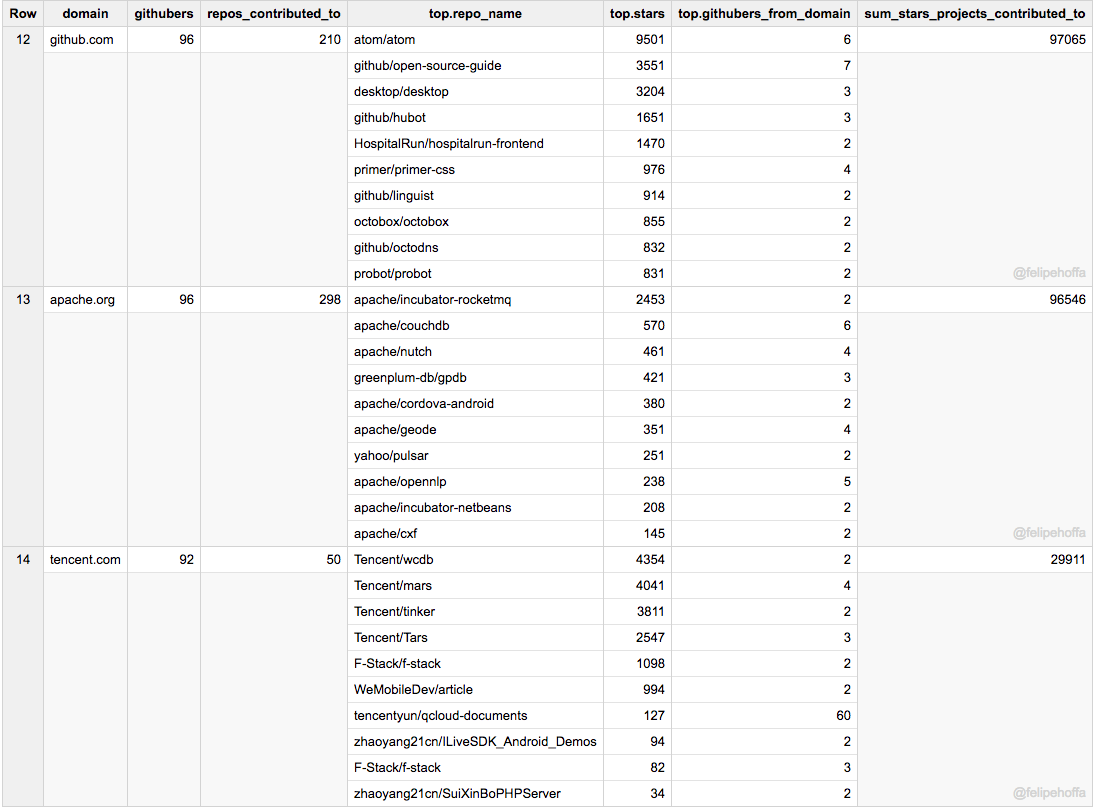
GitHub自己,Apache 和 Tencent:
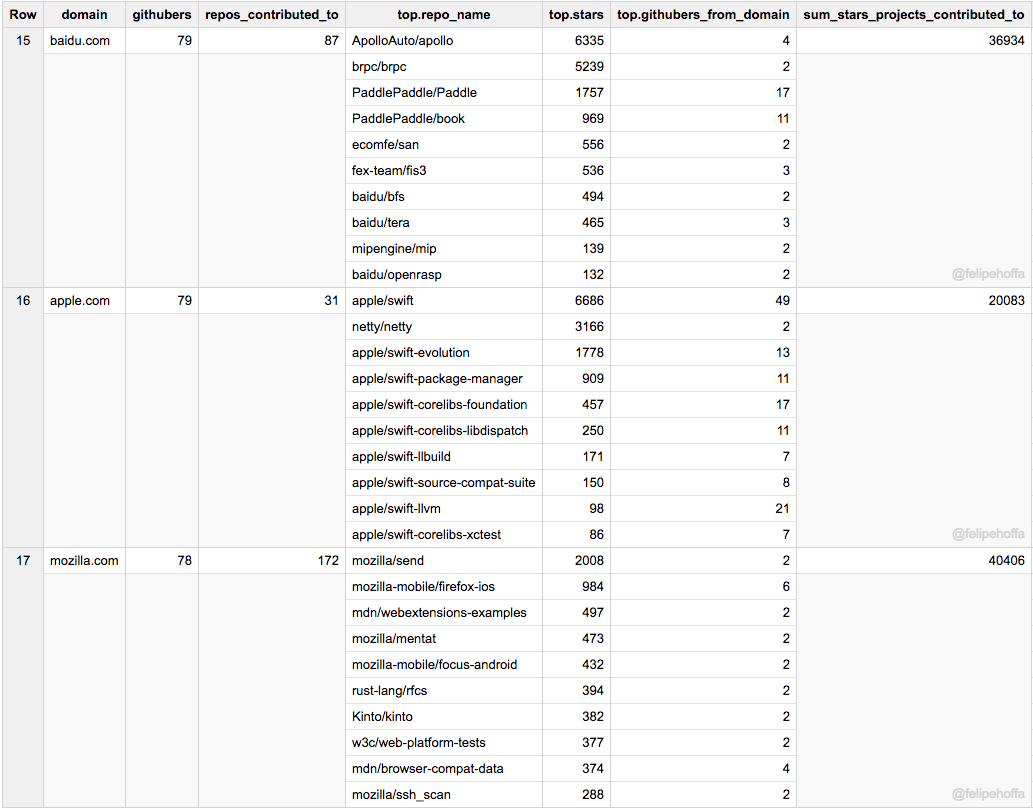
Baidu, Apple, Mozilla:
Oracle, Stanford, Mit, Shopify, MongoDb, Berkeley, VmWare, Netflix, Salesforce, Gsa.gov:
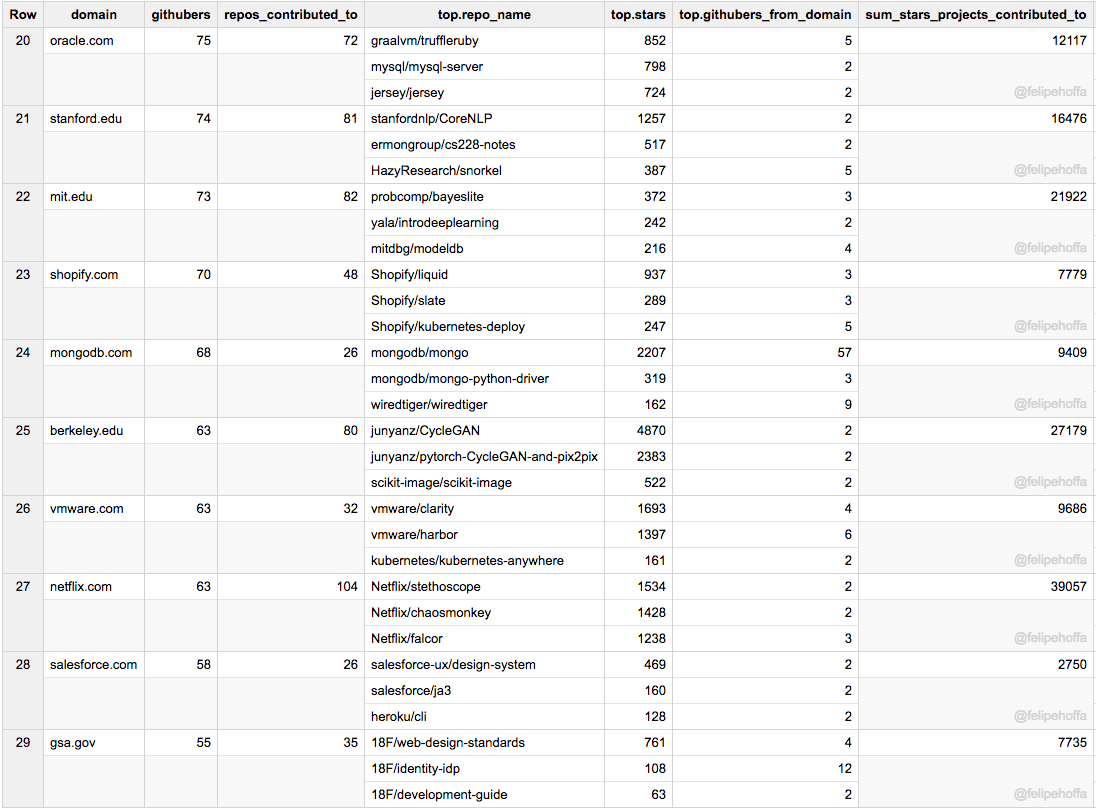
LinkedIn, Broad Institute, Palantir, Yahoo, MapBox, Unity3d, Automattic, Sandia, Travis-ci, Spotify:
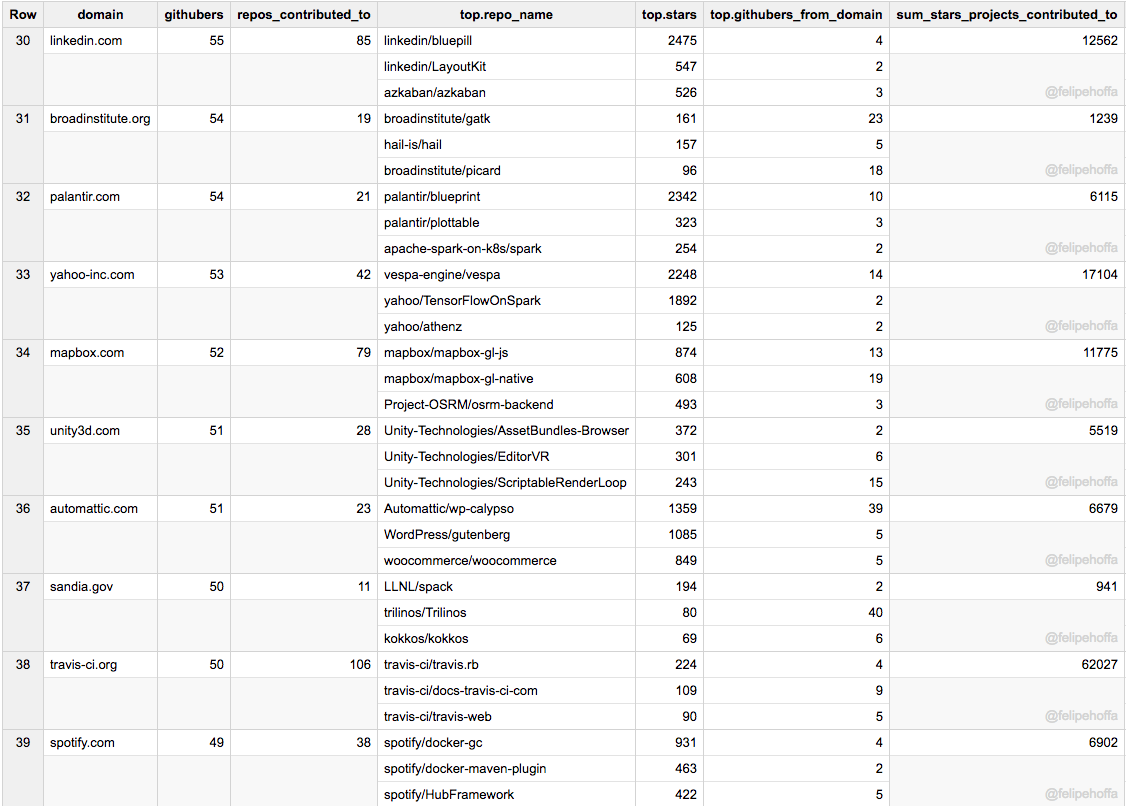
Chromium, UMich, Zalando, Esri, IBM (UK), SAP, EPAM, Telerik, UK Cabinet Office, Stripe:
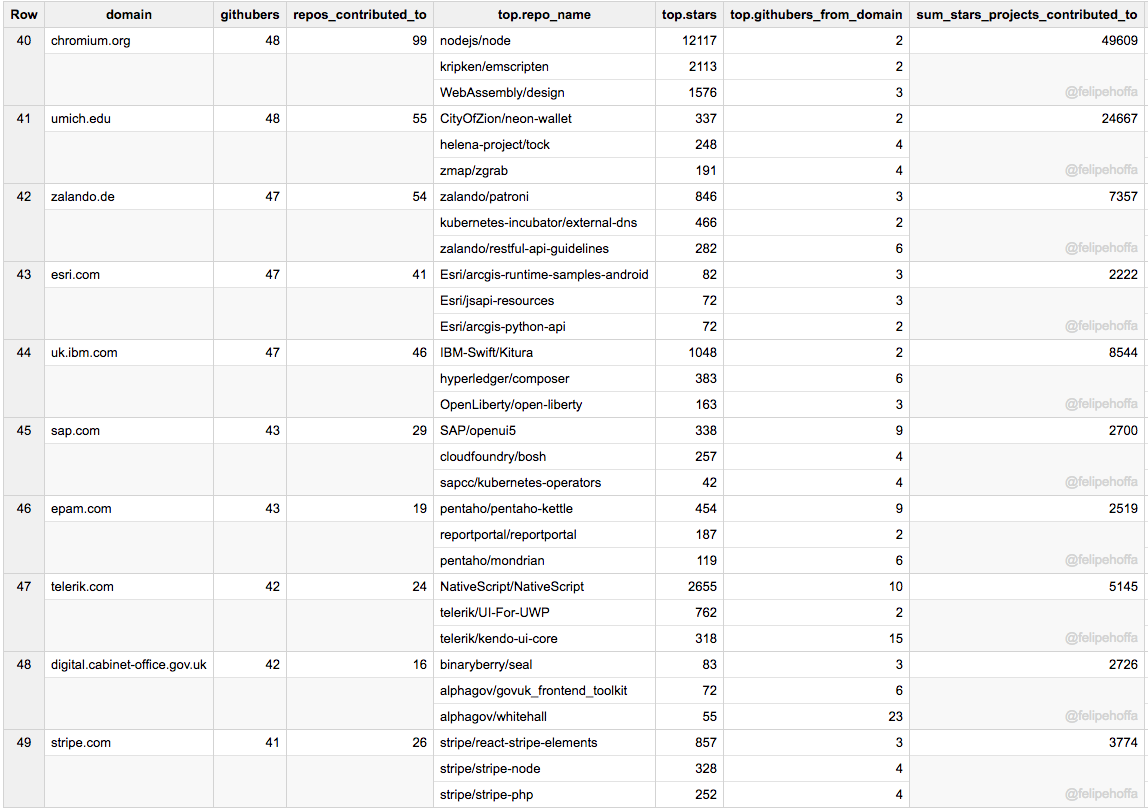
Cern, Odoo, Kitware, Suse, Yandex, IBM (Canada), Adobe, AirBnB, Chef, The Guardian:
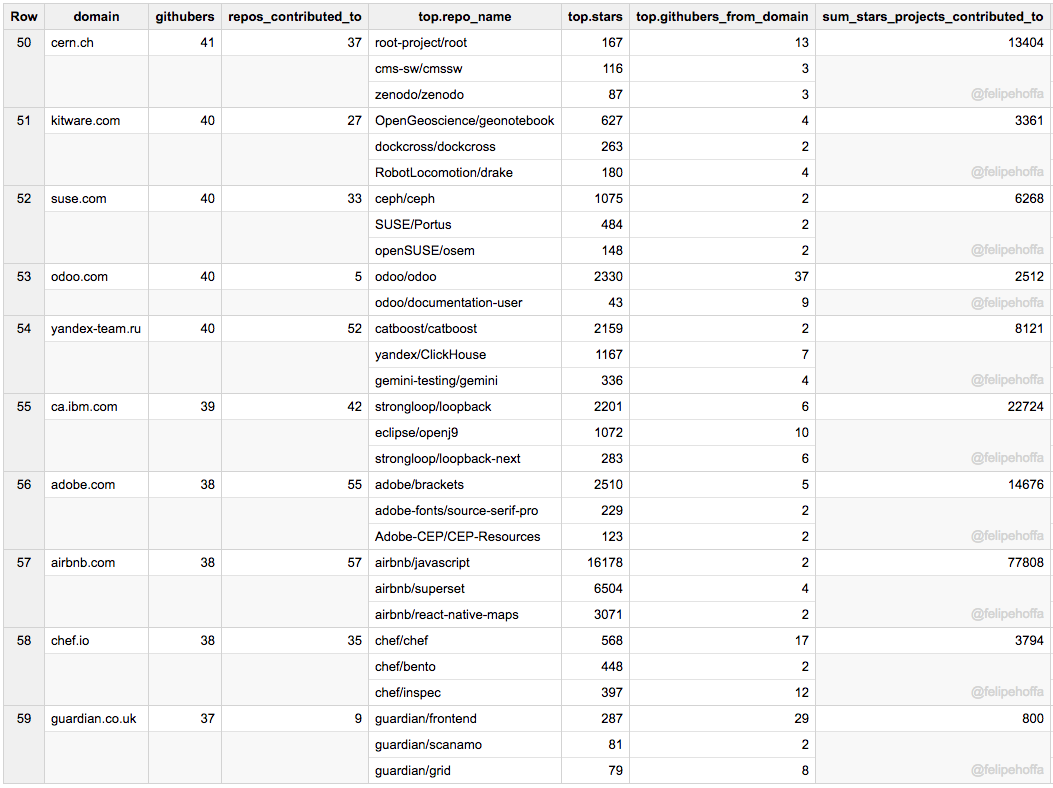
Arm, Macports, Docker, Nuxeo, NVidia, Yelp, Elastic, NYU, WSO2, Mesosphere, Inria
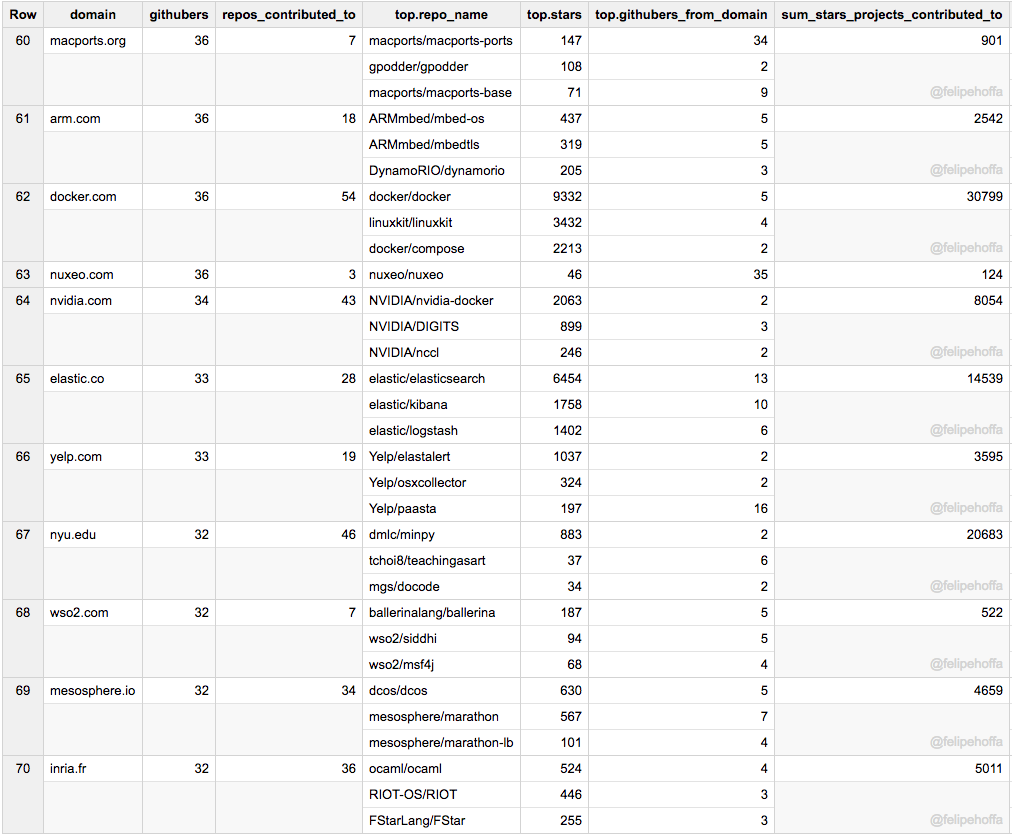
Puppet, Stanford (CS), DatadogHQ, Epfl, NTT Data, Lawrence Livermore Lab:
我的方法
如何將GitHub使用者和企業聯絡在一起
確定每個GitHub使用者隸屬於哪個組織並不容易—但是我們可以通過email的域名來確定,域名資訊包含在提交的PushEvents裡:
- 不止一個使用者用同一個電子郵件,所以我們只能考慮到GitHub使用者在同一時期可以將程式碼推送到超過20個star的GitHub 專案。
- 我只計同一時期超過3個推送的GitHub使用者。
- 使用者推送程式碼到GitHub可以在推送中顯示許多不同的電子郵件—部分解釋了Git是如何工作。為了確定每個使用者的所屬組織,檢視他們推送顯示最頻繁的電子郵件。
- 不是每個人都會用自己組織的郵箱地址。在 Github 上有很多 gmail.com, users.noreply.github.com 或其它的郵箱。有時候出於保護自己企業郵箱的需要,使用者會匿名——所以我看不見他們的郵件域名,那就沒辦法把他們計入進去了。
- 有時候僱員更換了組織,也就是跳槽了。我就把他們分配到獲得更多推送的公司。
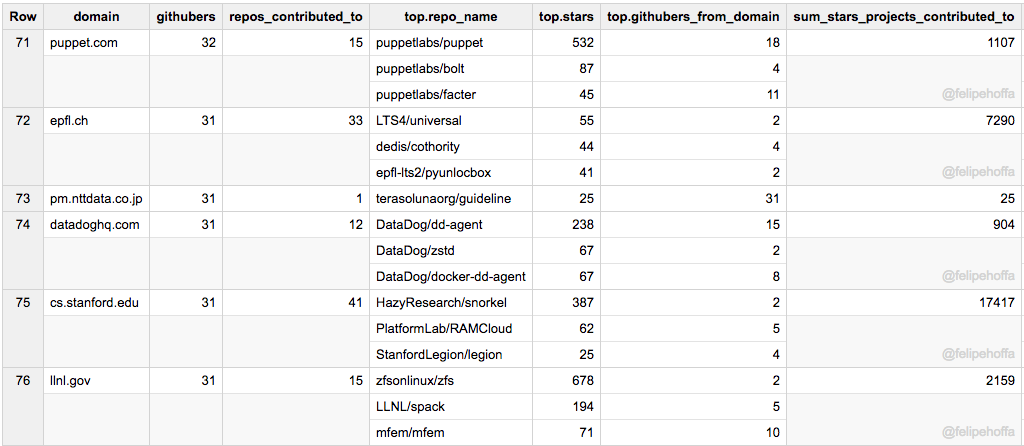
我的查詢
#standardSQL
WITH
period AS (
SELECT *
FROM `githubarchive.month.2017*` a
),
repo_stars AS (
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
FROM period
WHERE type='WatchEvent'
GROUP BY 1
HAVING stars>20
),
pushers_guess_emails_and_top_projects AS (
SELECT *
# , REGEXP_EXTRACT(email, r'@(.*)') domain
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
FROM (
SELECT actor.id
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email
, COUNT(*) c
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
FROM period a
JOIN repo_stars b
ON a.repo.id=b.id
WHERE type='PushEvent'
GROUP BY 1
HAVING c>3
)
)
SELECT * FROM (
SELECT domain
, githubers
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
, ARRAY(
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name
, CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
GROUP BY 1, 2
HAVING githubers_from_domain>1
ORDER BY stars DESC LIMIT 3
) top
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
FROM (
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
FROM pushers_guess_emails_and_top_projects
#WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|'))
WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru', '|')) # email hosters
GROUP BY 1
HAVING githubers > 30
)
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
)
ORDER BY githubers DESC
常見問題解答
如果一個組織有1500個倉庫,為什麼只計算200個呢?如果一個倉庫有7000個star,為什麼只顯示1500個?
我做了關聯過濾,只計算了2017年度的star數。例如,在GitHub上Apache有大於1500個倉庫,但在2017年,只有205個收到多於20個star數。
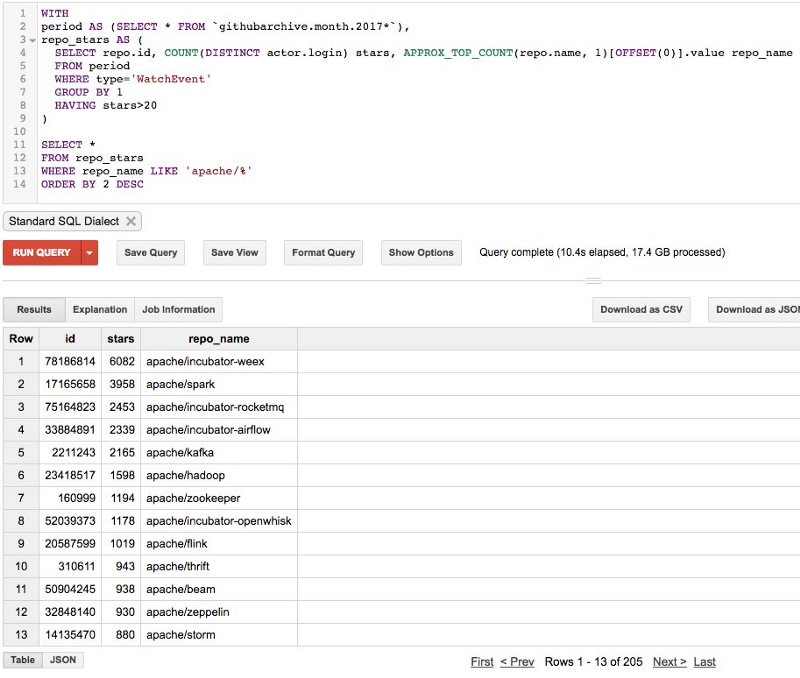
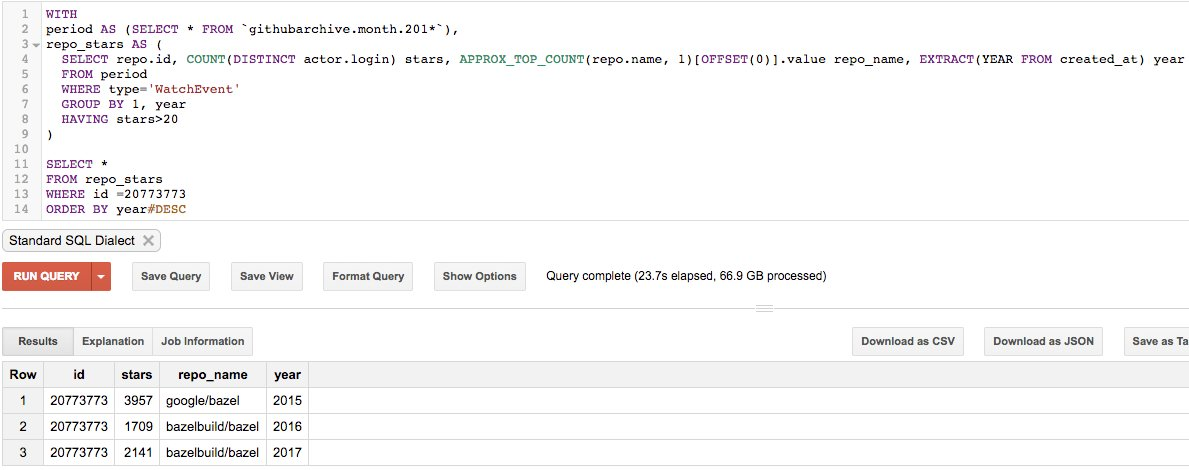
這是開源的現狀嗎?
請注意,分析GitHub資料不包括頂級的團體,如Android,Chromium, GNU, Mozilla,也不包括Apache或者Eclipse基金會,還有一些其它專案選擇在GitHub之外執行它們的大部分活動。
對我的組織不公平
我只能計算我所能看見的。大家可以質疑我的臆斷,告訴我你如何用更好的方式來衡量。工作查詢是最好的方法。
例如,當將IBM的基於區域的域名用一個SQL轉換語句合併為頂級域名時,看看它們的排名是如何變化的:
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
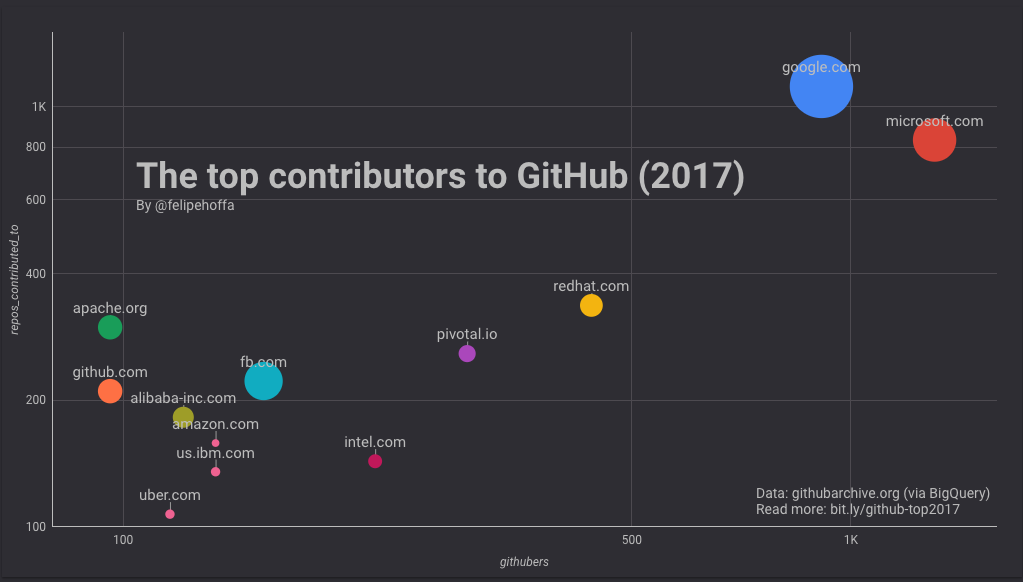
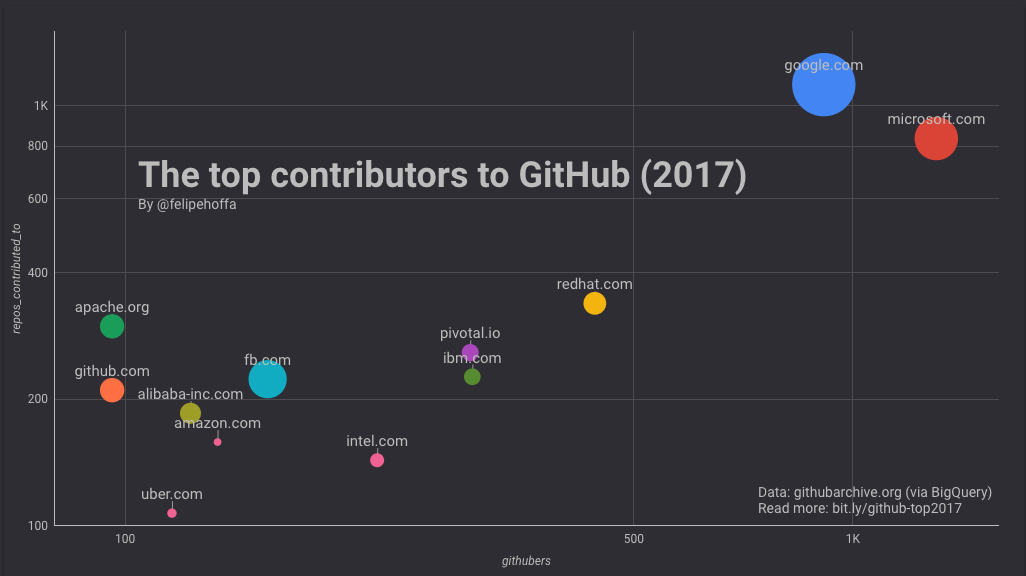
(當合並IBM的區域電子郵件域名時,它的相對排名發生顯著變化)
接下來的步驟
我以前可能錯過——錯誤可能還會再次發生。請看看GitHub所有可用的原始資料,並質疑我所有的臆斷——那會很酷,可以看看你會得到什麼樣的結果。