
Flume入門筆記------架構以及應用介紹
在具體介紹本文內容之前,先給大家看一下Hadoop業務的整體開發流程:
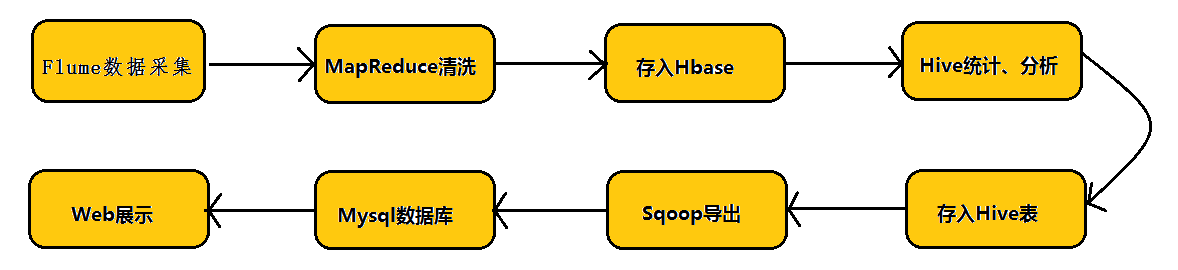
從Hadoop的業務開發流程圖中可以看出,在大資料的業務處理過程中,對於資料的採集是十分重要的一步,也是不可避免的一步,從而引出我們本文的主角—Flume。本文將圍繞Flume的架構、Flume的應用(日誌採集)進行詳細的介紹。
(一)Flume架構介紹
1、Flume的概念
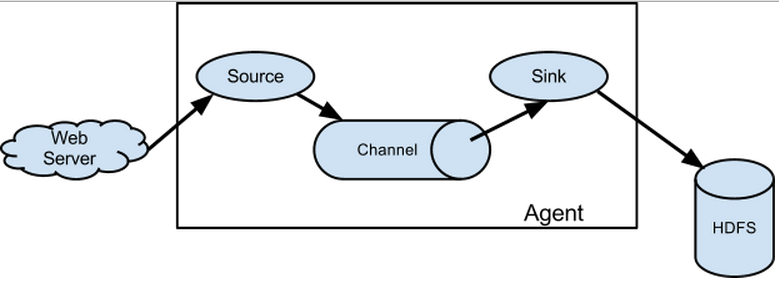
flume是分散式的日誌收集系統,它將各個伺服器中的資料收集起來並送到指定的地方去,比如說送到圖中的HDFS,簡單來說flume就是收集日誌的。
2、Event的概念
在這裡有必要先介紹一下flume中event的相關概念:flume的核心是把資料從資料來源(source)收集過來,在將收集到的資料送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先快取資料(channel),待資料真正到達目的地(sink)後,flume在刪除自己快取的資料。
在整個資料的傳輸的過程中,流動的是event,即事務保證是在event級別進行的。那麼什麼是event呢?—–event將傳輸的資料進行封裝,是flume傳輸資料的基本單位,如果是文字檔案,通常是一行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為一個位元組陣列,並可攜帶headers(頭資訊)資訊。event代表著一個數據的最小完整單元,從外部資料來源來,向外部的目的地去。
為了方便大家理解,給出一張event的資料流向圖:
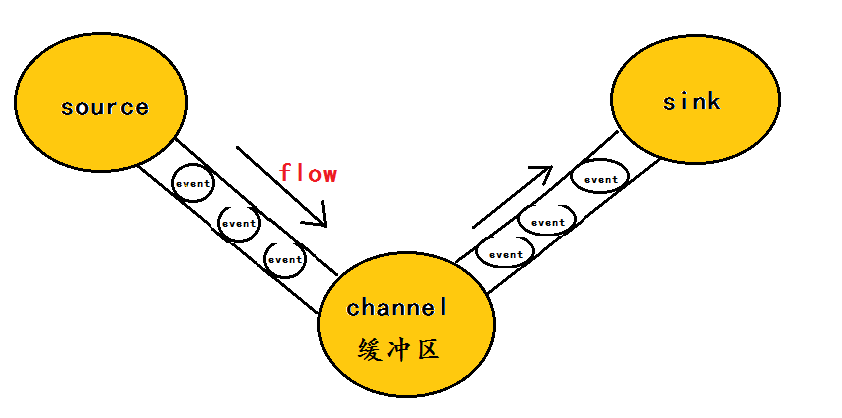
一個完整的event包括:event headers、event body、event資訊(即文字檔案中的單行記錄),如下所以:

其中event資訊就是flume收集到的日記記錄。
3、flume架構介紹
flume之所以這麼神奇,是源於它自身的一個設計,這個設計就是agent,agent本身是一個Java程序,執行在日誌收集節點—所謂日誌收集節點就是伺服器節點。
agent裡面包含3個核心的元件:source—->channel—–>sink,類似生產者、倉庫、消費者的架構。
source:source元件是專門用來收集資料的,可以處理各種型別、各種格式的日誌資料,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定義。
channel:source元件把資料收集來以後,臨時存放在channel中,即channel元件在agent中是專門用來存放臨時資料的——對採集到的資料進行簡單的快取,可以存放在memory、jdbc、file等等。
sink:sink元件是用於把資料傳送到目的地的元件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、
4、flume的執行機制
flume的核心就是一個agent,這個agent對外有兩個進行互動的地方,一個是接受資料的輸入——source,一個是資料的輸出sink,sink負責將資料傳送到外部指定的目的地。source接收到資料之後,將資料傳送給channel,chanel作為一個數據緩衝區會臨時存放這些資料,隨後sink會將channel中的資料傳送到指定的地方—-例如HDFS等,注意:只有在sink將channel中的資料成功傳送出去之後,channel才會將臨時資料進行刪除,這種機制保證了資料傳輸的可靠性與安全性。
5、flume的廣義用法
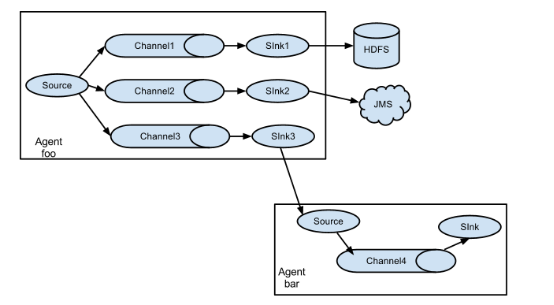
flume之所以這麼神奇—-其原因也在於flume可以支援多級flume的agent,即flume可以前後相繼,例如sink可以將資料寫到下一個agent的source中,這樣的話就可以連成串了,可以整體處理了。flume還支援扇入(fan-in)、扇出(fan-out)。所謂扇入就是source可以接受多個輸入,所謂扇出就是sink可以將資料輸出多個目的地destination中。
(二)flume應用—日誌採集
對於flume的原理其實很容易理解,我們更應該掌握flume的具體使用方法,flume提供了大量內建的Source、Channel和Sink型別。而且不同型別的Source、Channel和Sink可以自由組合—–組合方式基於使用者設定的配置檔案,非常靈活。比如:Channel可以把事件暫存在記憶體裡,也可以持久化到本地硬碟上。Sink可以把日誌寫入HDFS, HBase,甚至是另外一個Source等等。下面我將用具體的案例詳述flume的具體用法。
其實flume的用法很簡單—-書寫一個配置檔案,在配置檔案當中描述source、channel與sink的具體實現,而後執行一個agent例項,在執行agent例項的過程中會讀取配置檔案的內容,這樣flume就會採集到資料。
配置檔案的編寫原則:
1>從整體上描述代理agent中sources、sinks、channels所涉及到的元件
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
2>詳細描述agent中每一個source、sink與channel的具體實現:即在描述source的時候,需要
指定source到底是什麼型別的,即這個source是接受檔案的、還是接受http的、還是接受thrift
的;對於sink也是同理,需要指定結果是輸出到HDFS中,還是Hbase中啊等等;對於channel
需要指定是記憶體啊,還是資料庫啊,還是檔案啊等等。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3>通過channel將source與sink連線起來
- 1
- 2
- 3
- 1
- 2
- 3
啟動agent的shell操作:
- 1
- 2
- 1
- 2
引數說明: -n 指定agent名稱(與配置檔案中代理的名字相同)
-c 指定flume中配置檔案的目錄
-f 指定配置檔案
-Dflume.root.logger=DEBUG,console 設定日誌等級
具體案例:
案例1: NetCat Source:監聽一個指定的網路埠,即只要應用程式向這個端口裡面寫資料,這個source元件就可以獲取到資訊。 其中 Sink:logger Channel:memory
flume官網中NetCat Source描述:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
a) 編寫配置檔案:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
b) 啟動flume agent a1 服務端
- 1
- 1
c) 使用telnet傳送資料
- 1
- 1
d) 在控制檯上檢視flume收集到的日誌資料:
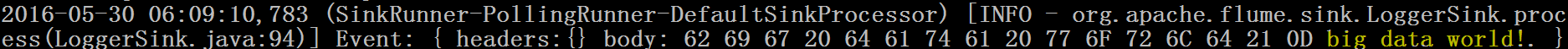
案例2:NetCat Source:監聽一個指定的網路埠,即只要應用程式向這個端口裡面寫資料,這個source元件就可以獲取到資訊。 其中 Sink:hdfs Channel:file (相比於案例1的兩個變化)
flume官網中HDFS Sink的描述:
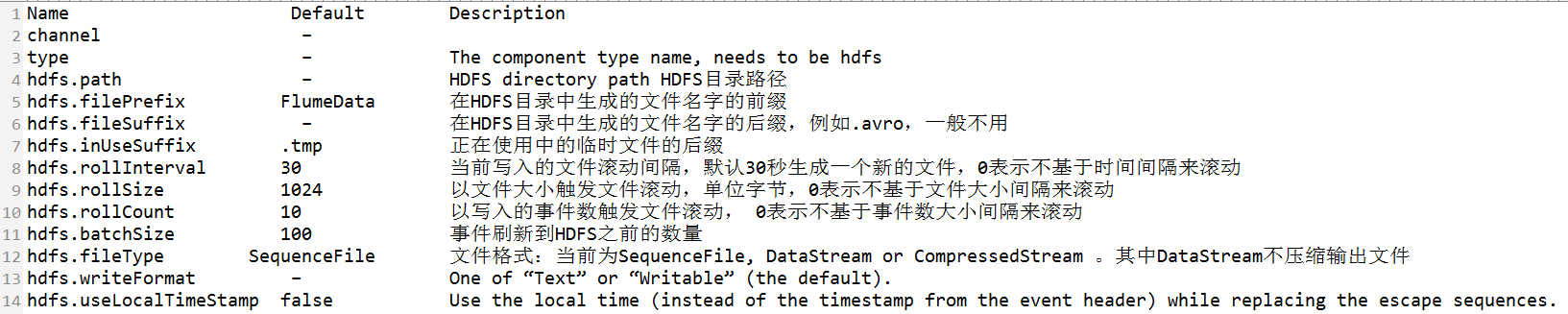
a) 編寫配置檔案:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
b) 啟動flume agent a1 服務端
- 1
- 1
c) 使用telnet傳送資料
- 1
- 1
d) 在HDFS中檢視flume收集到的日誌資料:
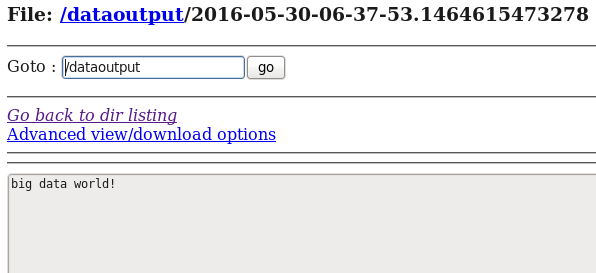
案例3:Spooling Directory Source:監聽一個指定的目錄,即只要應用程式向這個指定的目錄中新增新的檔案,source元件就可以獲取到該資訊,並解析該檔案的內容,然後寫入到channle。寫入完成後,標記該檔案已完成或者刪除該檔案。其中 Sink:logger Channel:memory
flume官網中Spooling Directory Source描述:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Spooling Directory Source的兩個注意事項: