
基於改進的協同過濾演算法的使用者評分預測模型
阿新 • • 發佈:2019-01-05
目標:精確預測某目標使用者對目標電影M的評分值。
步驟:1得到與目標電影M最相似的K個電影集合ci。
2.基於ci,計算評論過m電影且與目標使用者最相似的k2個使用者
3.將與目標使用者最相似的k2個使用者對目標電影M的評分值加權平均值作為目標使用者對目標電影評分預測值。
4測試不同k值,不同目標使用者對電影M的預測值減目標使用者對電影M的實際評分值,結果顯示評分誤差在0.6左右,說明演算法預測精度非常高。
相關公式模型:
1電影相似度計算公式(修正的餘弦相似度計算公式)
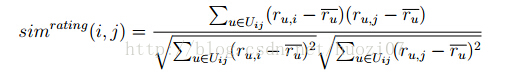
其中:Uij為同時評論電影ij的所有使用者集合,ru,i為使用者u對電影i的評分值,/ru為使用者u評論的所有電影的評分平均值。
2.使用者相似度計算公式

ci為1中計算的與電影i最相似的k個電影集合,u,v代表兩個使用者,ru,i為使用者u對電影i的評分值。可以看到,根據此公式,使用者間相似度為0等價於兩使用者對同一電影評分的值相差1分。
3.評分預測模型
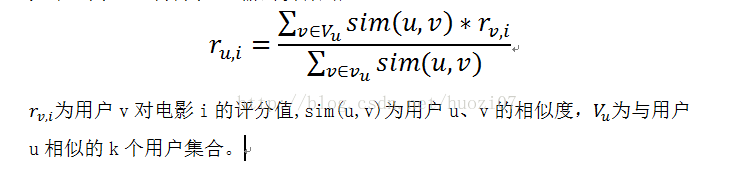
4模型評估方法
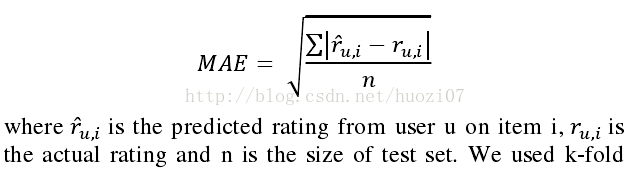
實現程式碼及註釋:
#-*- coding: utf-8 -*- import math class UserBasedCF: def __init__(self,datafile = None,k1=300,k2=2000):#建構函式初始化 self.readData(datafile=datafile,k1=k1,k2=k2)#載入資料 self.cacheData() def readData(self,datafile=None,k1=300,k2=2000): data = [] for line in open(datafile): userid,itemid,record,_ = line.strip('\n').split("::") if (int(userid)<k1)&(int(itemid)<k2):#設定訓練集的大小 data.append((userid,itemid,int(record)))#data列表儲存使用者id,電影id,得分 self.data=data return data def cacheData(self): self.userItemScore=dict()#{使用者:{電影1:評分,電影2:評分2}} self.user_items = dict()#{使用者:set(看過的電影集合)} self.item_users = dict()#{電影:set(看過該電影的使用者集合)} #僅僅遍歷一次資料,形成三個中間結果查詢字典 for user,item,rate in self.data: if user not in self.userItemScore: self.userItemScore.setdefault(user,{}) self.userItemScore[user][item]=int(rate) if item not in self.item_users: self.item_users.setdefault(item,set()) self.item_users[item].add(user) if user not in self.user_items: self.user_items.setdefault(user,set()) self.user_items[user].add(item) ''' #尋找hotmovie hotmovie={} for i in self.item_users.keys(): hotmovie.setdefault(i,len(self.item_users[i])) self.hotmovie=sorted(hotmovie.items(),key = lambda x : x[1],reverse = True)[0:20] print self.hotmovie ''' def itemSimBest(self,targetMovie='1210',k=[190,200]):#設定目標電影,與返回的最相似電影個數 self.targetMovie=targetMovie #計算每個targetmovie以外的電影與movie的相似度 simmj=dict()#存電影m與j的相似度 for j in self.item_users.keys():#j為所有電影 if j==targetMovie:continue umj=self.item_users[targetMovie]&self.item_users[j]#同時評論過電影mj的使用者集合 if umj==set([]):continue#如果沒有使用者共同評論電影mj則跳出本次迴圈 #中間結果計算,計算umj中每個使用者給出評分的平均值 umjj=dict()#umjj存對電影mj同時進行過評論的使用者的平均分 for u in umj: ucum=0 for i in self.userItemScore[u].items(): ucum+=float(i[1])#所有電影得分相加 umean=ucum/len(self.userItemScore[u])#該使用者評分總分/評論的電影數 umjj[u]=umean#使用者評分平均分,加入字典 #print(umjj)#與u共同評論了mj電影的使用者v有····他們各自的平均評分為 {'75': 3.92, '92': 2.8545454545454545} #對相似度計算的分子 fenzi=fenmu1=fenmu2=0 for v in umj:#i為使用者 fenzi+=(self.userItemScore[v][targetMovie]-umjj[v])*(self.userItemScore[v][j]-umjj[v]) fenmu1+=pow(self.userItemScore[v][targetMovie]-umjj[v],2) fenmu2+=pow(self.userItemScore[v][j]-umjj[v],2) if fenmu1*fenmu2==0:simmj[j]=0 else: sim=fenzi/(math.sqrt(fenmu1)*math.sqrt(fenmu2)) simmj[j]=sim #m與j專案相似度為sim #字典排序,取出與m最相似的k個電影 simmj=sorted(simmj.items(),key = lambda x : x[1],reverse = True) if len(simmj)<max(k):print "K值不能大於simmmj集合的元素個數————simmj集合的個數為"+str((len(simmj))) simmjkDict={}#存放不同k值,對應的最相似電影集合 for i in k: simmjkDict[i]=dict(simmj[0:i])#i為k return simmjkDict def userSimBest(self,simmjkDict,simk=0.00001): self.rightSimTargetuuDict={}#存放不同K值下,符合條件的目標使用者與其多個相似使用者的相似值 for key in simmjkDict.keys():#key就是topk這個列表 simmjk=simmjkDict[key] simmjk=set(simmjk.keys())#準備ci #print 'simmjk' #print len(simmjk) userm=list(self.item_users[self.targetMovie])#獲取評論過目標電影的使用者集合 rightSimTargetuu={}#有的tagetu的ci為空集,所以需要找到ci不為空集的targetu結果如圖 #print 'len user m' #print len(userm) for targetu in userm:#找到符合條件的targetu simtargetuu={}#找到與tagetu最相似的幾個使用者 for u in userm:#評論過目標電影的集合 if targetu==u:continue ci=self.user_items[targetu]&self.user_items[u]&simmjk if len(ci)>5: cum=0.0 for a in ci: cum+=pow((self.userItemScore[targetu][a]-self.userItemScore[u][a]),2) simtargetuu[u]=1.0-(cum*1.0)/len(ci) if len(simtargetuu)!=0:rightSimTargetuu[targetu]=simtargetuu #print rightSimTargetuu #因為ci設定過小,會使得有的使用者相似度計算結果為負或者0這種相似度值當然不適合預測,所以需要去除奇異值 for u in rightSimTargetuu.keys(): for v in rightSimTargetuu[u].keys(): if rightSimTargetuu[u][v]<simk:del rightSimTargetuu[u][v]#設定相似度閾值 for u in rightSimTargetuu.keys():#刪除{‘151’:{}}這樣的空值 if rightSimTargetuu[u]=={}: del rightSimTargetuu[u] #print 'del sim dic' #print rightSimTargetuu #self.rightSimTargetuu=rightSimTargetuu if len(rightSimTargetuu)==0:print "對k="+str(key)+" 沒有匹配的相似使用者,需要降低相似度閾值or增加K or 改變目標電影" self.rightSimTargetuuDict[key]=rightSimTargetuu #print self.rightSimTargetuuDict.keys() #print self.rightSimTargetuuDict[200] def predictAndEvaluation(self): m=self.targetMovie K_MAE_Dict={} for key in self.rightSimTargetuuDict.keys(): rightSimTargetuu=self.rightSimTargetuuDict[key] predictTargetScore={} for u in rightSimTargetuu.keys(): fenzi=fenmu=0.0 for v in rightSimTargetuu[u].keys(): fenzi+=rightSimTargetuu[u][v]*self.userItemScore[v][m] fenmu+=rightSimTargetuu[u][v] predictTargetScore[u]=fenzi*1.0/fenmu #test result cum=0.0 for i in predictTargetScore.keys(): cum+=abs(predictTargetScore[i]-self.userItemScore[i][m]) if len(predictTargetScore.keys())==0:break MAE=math.sqrt(cum/len(predictTargetScore.keys())) K_MAE_Dict[key]=MAE K_MAE_Dict=sorted(K_MAE_Dict.items(),key = lambda x : x[0],reverse = False) print "對目標電影 "+str(self.targetMovie)+" 不同k值對應的MAE值" print K_MAE_Dict def testModel(): cf=UserBasedCF('ratings.dat',k1=300,k2=2000)#載入資料檔案。由於原始資料集是由6040個使用者對3900個電影評論產生的逾100萬條電影評論資料 #原始資料較大,故可以使用k1,k2引數獲取原始資料子集進行模型效果初步檢驗 #k1代表使用者id範圍,k2代表電影id範圍(0<k1<6040,0<k2<3900) print "資料樣例:" print cf.data[0:6]#列印部分資料樣例 print "載入的資料條目數量"+str(len(cf.data)) k=[190,200,205,210,]#設定與目標電影最相似的k個電影數值。當k<<number(共同評論目標電影m與電影j的人數數量) Top-k個電影 simmjkDict=cf.itemSimBest(targetMovie='260',k=k)#求目標電影的K-Top個最相似電影 #最好選熱門電影,可以的熱門電影有:1196、1210、260、1198、593、110、1265、589、318、1197、608、296、527、1617、1 cf.userSimBest(simmjkDict,simk=0.00001)#simk為使用者相似度的閾值。根據你的相似度計算公式,使用者相似度值大於0,即相似度很高,不建議修改該預設閾值 cf.predictAndEvaluation() if __name__ == "__main__": testModel()
實現結果:

合作者:湖南大學 李劍鋒