
Java 1.8 HashMap實現(譯註)
譯者序
作者整個部落格只有這一篇文章,而就這一篇文章,卻是介紹HashMap與Java中Hash策略的精品。作者從Java 2講述到Java 8,細數種種變更,並且用數學公式和清晰的思路解釋其原理。全文行文流暢,排版規範典雅,有著論文般的美感,就技術部落格而言,實乃佳品。配合HashMap原始碼消化更佳。
因為時間倉促,在翻譯的過程中,難免會有錯漏,希望多加指正。
概述
這篇文件闡述了Java中的HashMap,從早期版本一直到基於Oracle的JDK和OpenJDK的Java 7,8中的實現原理。在文件中,所有引用的原始碼都來自於Oracle JDK和OpenJDK——這兩者在純粹的Java SDK實現上是完全相同的。我希望這篇文件能夠幫助各位到開發者,甚至是那些從未使用過Java的開發者。因為這些內容與如何設計框架或者庫無關,它們更多的針對於如何去以實現語言無關的HashMap。
HashMap是Java集合框架(Java Collection Framework, JCF)中一個基礎類,它在1998年12月,加入到Java 2版本中。在此之後,Map介面本身除了在Java 5中引入了泛型以外,再沒有發生過明顯變化。然而HashMap的實現,則為了提升效能,不斷地在改變。
實現HashMap時一個重要的考量,就是如何儘可能地規避雜湊碰撞。而HashMap實現變更的路線圖,也大多與此相關。
HashMap與HashTable
HashMap和HashTable這兩個術語,在此文件中指的都是Java的API。
HashTable在Java出現之初,就已經被引入,而HashMap直到Java 2,才隨著JCF出現到人們的視野之中。
HashTable和HashMap一樣,也實現了Map介面,因此他們從函式的視角上是等價的。
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {Code No.1 HashTable 與 HashMap的宣告
然而,在它們之間,有許多處不同。首先,HashTable是一個執行緒安全
synchronized關鍵字進行修飾。儘管並不推薦使用HashTable來開發一個高效能的應用,但是它確實能夠保證你的應用執行緒安全。相反,HashMap並不保證執行緒安全。因此當你構建一個多執行緒應用時,請使用ConcurrentHashMap。 而在單執行緒應用中,HashMap有這個比HashTable更好的效能,這得益於HashMap使用了多種方式來規避雜湊碰撞,其中,使用輔助Hash函式是一種著名的方式。在Java 8中,一種更好的方式被用來處理高頻碰撞的問題。不過,我們需要記住一點,沒有完美的雜湊函式。但是即使我們無法創造一個完美的世界,讓它變得更好也是值得的。
這裡,我想要指出HashTable和HashMap這個兩個術語的來源。基本上,他們都可以被看做是一種關聯陣列,關聯陣列與陣列最大的不同,就是對於每一個數據,關聯陣列會有一個key與之關聯,當使用關聯陣列時,每個資料都可以通過對應的Key來獲取。關聯陣列有許多別名,比如Map(對映)、Dictionary(字典)和Symbol-Table(符號表)。儘管名字不同,他們的含義都是相同的。
字典和符號表都是非常直觀的術語,無須解釋它們的行為。對映來自於數學領域。在函式中,一個域(集合)中的值被與另一個域(集合)中的值關聯,這種關聯關係叫做對映。
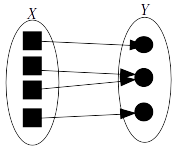
*Figure No.1 函式中的對映
因此HashTable和HashMap都是基礎的關聯陣列,雜湊指的是一種通過Key來獲取資料的過程。
雜湊分佈和雜湊碰撞
對於每個物件X和Y,如果當(且僅當,譯者注)X.equals(Y)為false,使得X.hashCode() != Y.hashCode()為true,這樣的函式叫做完美Hash函式。下面是完美雜湊函式的數學表達.
基於物件中變化的域(欄位),我們很容易構造一個完美雜湊函式。一個
Boolean物件有true和false兩個值,因此Boolean物件的Hash值可以通過一個二進位制位 bit 表達,即0b0, 0b1。對於一些Number物件,比如Integer、Long、Double等,他們都可以使用自身原始的值作為Hash值。然而,想要構造這樣的完美雜湊函式,我們需要無限的記憶體大小,這種假設顯然是不可能的。而且,即時我們能夠為每個POJO(Plain Ordinary Java Object)或者String物件構造一個理論上不會有衝突的雜湊函式,但是hashCode()函式的返回值是int型。根據鴿籠理論,當我們的物件超過這裡還有一個點需要我們考慮。我們是否可以在某些限制下,通過允許雜湊碰撞來節省記憶體?這往往是一個提升總體效能不錯的方式。許多關聯陣列的實現,包括HashMap,使用了大小為M的桶來儲存
int index = X.hashCode() % M;Code No.2 獲取hash桶索引的方式
因此,當一個物件的插入HashMap,發生雜湊衝突的概率是

Figure No.2 Open Adressing and Seperate Chaning
開放定址是一種解決雜湊衝突的方式,當計算出的桶索引的位置被佔據時,通過一定的探索方式,來尋找未被佔據的雜湊桶(適合數量確定,衝突較少的情況,譯者注)。而分離連結則將每一個雜湊桶作為一個連結串列的頭結點,當雜湊碰撞發生時,僅需在連結串列中進行儲存、查詢。
這兩種方法都有著同樣的最壞時間複雜度
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// the reason why transient keyword is used is because of efficienty,
// when it comes to serialize the HashMap instance,
// storing key-value pairs is the better
// than serializing object itself.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() { … }
public final V getValue() { …}
public final V setValue(V newValue) { … }
public final boolean equals(Object o) { … }
public final int hashCode() {…}
public final String toString() { …}
void recordAccess(HashMap<K,V> m) {… }
void recordRemoval(HashMap<K,V> m) {…}
}Code No.3 Java 7中雜湊桶的實現
程式碼4呈現了put()使用分離連結串列實現的方式。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
// creating 'table' array
}
// null can be a key in HashMap
if (key == null)
return putForNullKey(value);
// rather than using value.hashCode() without altering
// modified hash values is used
// with a Supplement Hash Function
// the Supplement Hash Function is explained
// in 'Supplement Hash Function' section
int hash = hash(key);
// value 'i' is an index of hash bucket
// indexFor() is related with 'hash % table.length'
int i = indexFor(hash, table.length);
// scaning a linked list in a hash bucket
// if there is a data with the correspondence key
// the data is replaced with new one.
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// modCount is for managing how many times
// this HashMap has been modificated
// it is also used to determine
// whether throw ConcurrentModificationException
modCount++;
// create new Entry only if the key is never used yet.
addEntry(hash, key, value, i);
return null;
}Code No.4 Java 1.7中HashMap的put()方法的實現
Java 8 HashMap的分離連結串列
從Java 2到Java 1.7,HashMap在分離連結串列上的改變並不多,他們的演算法基本上是相同的。如果我們假設物件的Hash值服從平均分佈,那麼獲取一個物件需要的次數時間複雜度應該是
資料越多,
使用連結串列還是樹,與一個雜湊桶中的元素數目有關。程式碼5中中展示了Java 8的HashMap在使用樹和使用連結串列之間切換的閾值。當衝突的元素數增加到8時,連結串列變為樹;當減少至6時,樹切換為連結串列。中間有2個緩衝值的原因是避免頻繁的切換浪費計算機資源。
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;Code No.5 Java 8 HashMap中的TREEIFY_THRESHOLD & UNTREEIFY_THRESHOLD
Java 8 HashMap使用Node類替代了Entry類,它們的結構大體相同。一個顯著地差別是,Node類具有匯出類TreeNode,通過這種繼承關係,一個連結串列很容易被轉換成樹。
Java 8 HashMap使用的樹是紅黑樹,它的實現基本與JCF中的TreeMap相同。通常,樹的有序性通過兩個或更多物件比較大小來保證。Java 8 HashMap中的樹也通過物件的Hash值(這個hash值與雜湊桶索引值不同,索引值在這個hash值的基礎上對桶大小M取模,譯者注)作為物件的排序鍵。因為使用Hash值作為排序鍵打破了Total Ordering(可以理解為數學中的小於等於關係,譯者注),因此這裡有一個tieBreakOrder()方法來處理這個問題。
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
// the name of class is different from Java7's
// but this class has almost identical structure
// with Java7's except for 'treefying'
}
// LinkedHashMap.Entry extends HashMap.Node
// so TreeNode instacne can be inserted into 'table' array
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
// in Red-Black Tree node is either Red or Black.
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
final TreeNode<K,V> root() {
// returns the root of Tree Node
}
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
// root is the 'first gate' whenever work with trees.
}
// for traversing
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {}
final TreeNode<K,V> getTreeNode(int h, Object k) {}
/**
* Tie-breaking utility for ordering insertions when equal
* hashCodes and non-comparable. We don't require a total
* order, just a consistent insertion rule to maintain
* equivalence across rebalancings. Tie-breaking further than
* necessary simplifies testing a bit.
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
final void treeify(Node<K,V>[] tab) {
// turn a linked list to a tree.
}
final Node<K,V> untreeify(HashMap<K,V> map) {
// turn a tree to a linked list
}
// method names explain everything.
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {}
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {}
// according to Red-Black theconstruction rule,
// these methods are to keep trees' balance
final void split (…)
static <K,V> TreeNode<K,V> rotateLeft(…)
static <K,V> TreeNode<K,V> rotateRight(…)
static <K,V> TreeNode<K,V> balanceInsertion(…)
static <K,V> TreeNode<K,V> balanceDeletion(…)
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
// this is for verifying the construction of a tree.
}
}Code No.6 Java 8中的Node類
Hash桶動態擴容
小數目的雜湊桶可以有效的利用記憶體,但是會產生更高概率的雜湊碰撞,最終損失效能。因此,HashMap會在資料量達到一定大小時,將雜湊桶的數量擴充到兩倍。當雜湊桶的數量變為兩倍後,
雜湊桶的預設數量是16,最大值是
// newCapacity always has a value of powers of 2 $
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// MAXIMIM_CAPACITY는 230이다.
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
// after creating new hash buckets, all stored key-value paired data
// are stored in new hash buckets.
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// traversing all hash buckets
for (Entry<K,V> e : table) {
// traversing a linked list in a hash bucket
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// as we have new M, the size of hash buckets
// so need to recompute new index value(hashCode % M)
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}Code No.7 Java 1.7中的雜湊桶擴容
確定是否需要對桶進行擴充套件的臨界值是
因為在臨界點的擴容會導致所有資料重新插入,那麼從一個預設的HashMap一直擴容到當前包含有N個元素的HashMap的消耗,也就是資料的插入次數,可以大致估算出。(原文公式不嚴格,沒有給出上下界,因此沒有評估意義。此處公式和結論由譯者給出,譯者注)