
Win10+CUDA10+VS2017 安裝配置教程
目錄
本機配置
- win10 64bit(版本1809)
- i5-7200 U
- GTX 940MX
下載並配置
測試Cuda是否安裝成功
①命令列測試
開啟命令提示符,輸入:nvcc -V
出現如下類似資訊即為成功
②編譯測試檔案
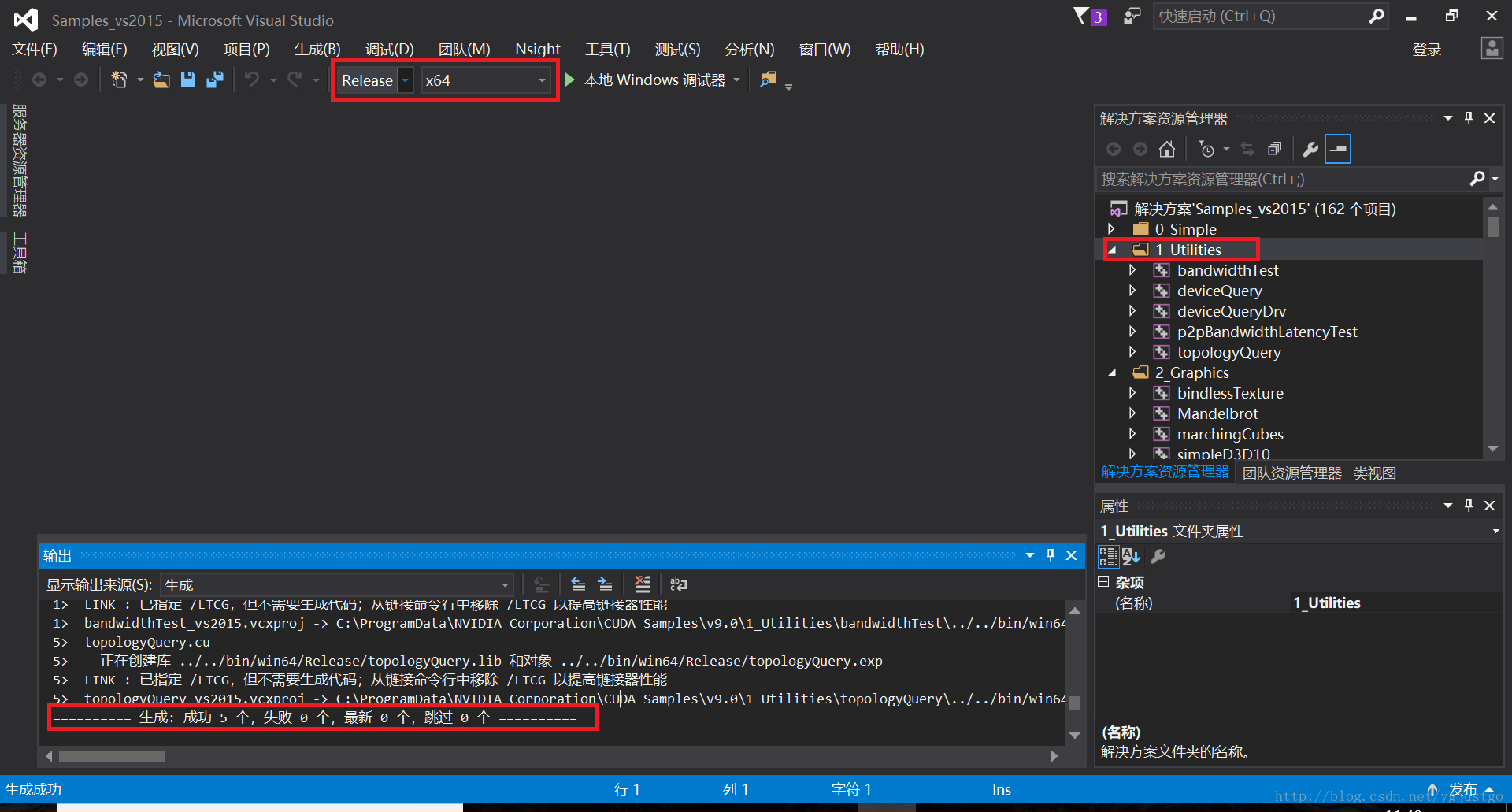
- C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.0下找到Samples_vs2017.sln並開啟
- 編譯:選擇Release x64,右鍵1_Utilities,點選“生成”
③驗證deviceQuery和bandwidthTest
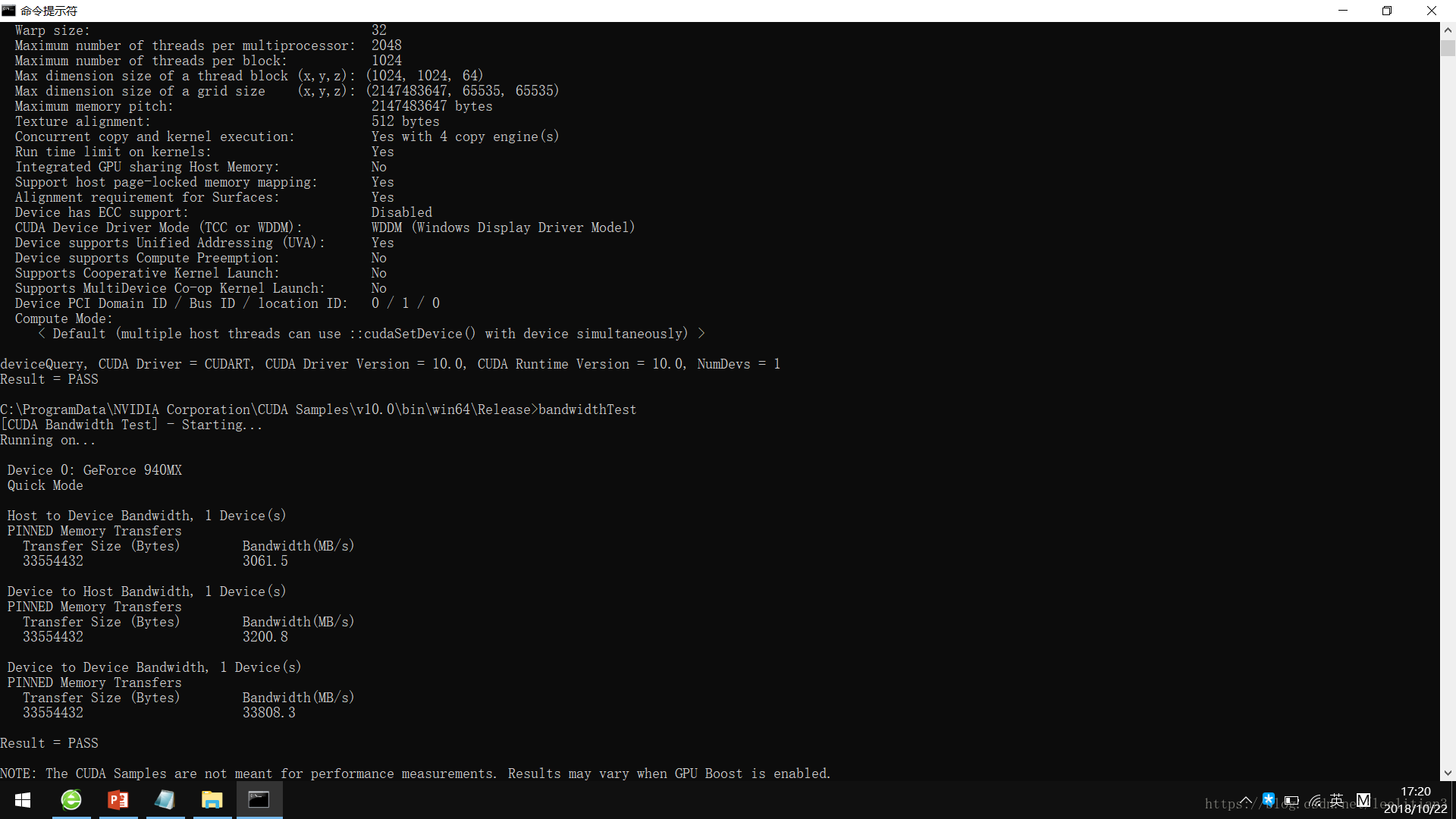
- 開啟命令提示符:定位到 c:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.0\bin\win64\Release
- 分別輸入deviceQuery,bandwidthTest並執行,出現如下類似資訊便說明CUDA安裝成功

配置環境變數
①確認系統變數中:CUDA_PATH和CUDA_PATH_V10.0已經存在
②我們還需要在環境變數中新增如下幾個變數:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0 CUDA_LIB_PATH = %CUDA_PATH%\lib\x64 CUDA_BIN_PATH = %CUDA_PATH%\bin CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64 CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64③可在cmd中檢視配置情況(命令:set cuda)
配置VS2017
①新建Visual C++空專案(CUDA_TEST)
②CUDA_TEST右鍵->新增->新建項->選擇CUDA C/C++File,取名CUDA_MAIN
③CUDA_TEST右鍵–>專案依賴項–>自定義生成,選擇CUDA10.0
④CUDA_MAIN.cu右鍵->屬性,在配置屬性–>常規–>項型別–>選擇“CUDA C/C++”
⑤專案配置
1.x64
1.1 包含目錄配置
1.右鍵點選專案屬性–>屬性–>配置屬性–>VC++目錄–>包含目錄
2.新增包含目錄:
$(CUDA_PATH)\include1.2 庫目錄配置
1.VC++目錄–>庫目錄
2.新增庫目錄:
$(CUDA_PATH)\lib\x641.3 依賴項
配置屬性–>連結器–>輸入–>附加依賴項
新增庫檔案:cublas.lib cuda.lib cudadevrt.lib cudart.lib cudart_static.lib nvcuvid.lib OpenCL.lib cublas.lib注意:新增nvcuvid.lib庫檔案,編譯時,報找不到該檔案的錯誤。去掉後,程式也能執行
2.x86(win32)
2.1 包含目錄配置
右鍵點選專案屬性–>屬性–>配置屬性–>VC++目錄–>包含目錄
新增包含目錄:
$(CUDA_PATH)\include2.2 庫目錄配置
1.VC++目錄–>庫目錄
2.新增庫目錄:
$(CUDA_PATH)\lib\Win322.3 依賴項
配置屬性–>聯結器–>輸入–>附加依賴項
新增庫檔案:cuda.lib cudadevrt.lib cudart.lib cudart_static.lib nvcuvid.lib OpenCL.lib⑥測試程式,在CUDA_MAIN.cu中貼上以下程式碼:
#include "cuda_runtime.h" #include "cublas_v2.h" #include <time.h> #include <iostream> using namespace std; // 定義測試矩陣的維度 int const M = 5; int const N = 10; int main() { // 定義狀態變數 cublasStatus_t status; // 在 記憶體 中為將要計算的矩陣開闢空間 float *h_A = (float*)malloc(N*M * sizeof(float)); float *h_B = (float*)malloc(N*M * sizeof(float)); // 在 記憶體 中為將要存放運算結果的矩陣開闢空間 float *h_C = (float*)malloc(M*M * sizeof(float)); // 為待運算矩陣的元素賦予 0-10 範圍內的隨機數 for (int i = 0; i < N*M; i++) { h_A[i] = (float)(rand() % 10 + 1); h_B[i] = (float)(rand() % 10 + 1); } // 列印待測試的矩陣 cout << "矩陣 A :" << endl; for (int i = 0; i < N*M; i++) { cout << h_A[i] << " "; if ((i + 1) % N == 0) cout << endl; } cout << endl; cout << "矩陣 B :" << endl; for (int i = 0; i < N*M; i++) { cout << h_B[i] << " "; if ((i + 1) % M == 0) cout << endl; } cout << endl; /* ** GPU 計算矩陣相乘 */ // 建立並初始化 CUBLAS 庫物件 cublasHandle_t handle; status = cublasCreate(&handle); if (status != CUBLAS_STATUS_SUCCESS) { if (status == CUBLAS_STATUS_NOT_INITIALIZED) { cout << "CUBLAS 物件例項化出錯" << endl; } getchar(); return EXIT_FAILURE; } float *d_A, *d_B, *d_C; // 在 視訊記憶體 中為將要計算的矩陣開闢空間 cudaMalloc( (void**)&d_A, // 指向開闢的空間的指標 N*M * sizeof(float) // 需要開闢空間的位元組數 ); cudaMalloc( (void**)&d_B, N*M * sizeof(float) ); // 在 視訊記憶體 中為將要存放運算結果的矩陣開闢空間 cudaMalloc( (void**)&d_C, M*M * sizeof(float) ); // 將矩陣資料傳遞進 視訊記憶體 中已經開闢好了的空間 cublasSetVector( N*M, // 要存入視訊記憶體的元素個數 sizeof(float), // 每個元素大小 h_A, // 主機端起始地址 1, // 連續元素之間的儲存間隔 d_A, // GPU 端起始地址 1 // 連續元素之間的儲存間隔 ); cublasSetVector( N*M, sizeof(float), h_B, 1, d_B, 1 ); // 同步函式 cudaThreadSynchronize(); // 傳遞進矩陣相乘函式中的引數,具體含義請參考函式手冊。 float a = 1; float b = 0; // 矩陣相乘。該函式必然將陣列解析成列優先陣列 cublasSgemm( handle, // blas 庫物件 CUBLAS_OP_T, // 矩陣 A 屬性引數 CUBLAS_OP_T, // 矩陣 B 屬性引數 M, // A, C 的行數 M, // B, C 的列數 N, // A 的列數和 B 的行數 &a, // 運算式的 α 值 d_A, // A 在視訊記憶體中的地址 N, // lda d_B, // B 在視訊記憶體中的地址 M, // ldb &b, // 運算式的 β 值 d_C, // C 在視訊記憶體中的地址(結果矩陣) M // ldc ); // 同步函式 cudaThreadSynchronize(); // 從 視訊記憶體 中取出運算結果至 記憶體中去 cublasGetVector( M*M, // 要取出元素的個數 sizeof(float), // 每個元素大小 d_C, // GPU 端起始地址 1, // 連續元素之間的儲存間隔 h_C, // 主機端起始地址 1 // 連續元素之間的儲存間隔 ); // 列印運算結果 cout << "計算結果的轉置 ( (A*B)的轉置 ):" << endl; for (int i = 0; i < M*M; i++) { cout << h_C[i] << " "; if ((i + 1) % M == 0) cout << endl; } // 清理掉使用過的記憶體 free(h_A); free(h_B); free(h_C); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); // 釋放 CUBLAS 庫物件 cublasDestroy(handle); getchar(); return 0; }⑦編譯執行





遇到的問題
①最新的VS2017在編譯過程中可能產生類似於“找不到Windows SDK”字樣的錯誤
解決方法:只需要按照它的提示更改為可用版本的SDK即可。
②驗證deviceQuery報錯:"CUDA: cudaDeviceSynchronize return error code 30"
解決方法:重灌NVIDIA顯示卡驅動
