
什麼是分散式檔案系統?分散式檔案系統的原理、出現的問題與解決方法
本地檔案系統如ext3,reiserfs等(這裡不討論基於記憶體的檔案系統),它們管理本地的磁碟儲存資源、提供檔案到儲存位置的對映,並抽象出一套檔案訪問介面供使用者使用。但隨著網際網路企業的高速發展,這些企業對資料儲存的要求越來越高,而且模式各異,如淘寶主站的大量商品圖片,其特點是檔案較小,但數量巨大;而類似於youtube,優酷這樣的視訊服務網站,其後臺儲存著大量的視訊檔案,尺寸大多在數十兆到數吉位元組不等。這些應用場景都是傳統檔案系統不能解決的。分散式檔案系統將資料儲存在物理上分散的多個儲存節點上,對這些節點的資源進行統一的管理與分配,並向用戶提供檔案系統訪問介面,其主要解決了本地檔案系統在檔案大小、檔案數量、開啟檔案數等的限制問題。
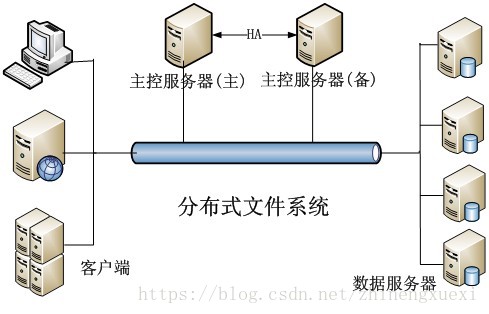
1、典型架構
目前比較主流的一種分散式檔案系統架構,如下圖所示,通常包括主控伺服器(或稱元資料伺服器、名字伺服器等,通常會配置備用主控伺服器以便在故障時接管服務,也可以兩個都為主的模式),多個數據伺服器(或稱儲存伺服器,儲存節點等),以及多個客戶端,客戶端可以是各種應用伺服器,也可以是終端使用者。
分散式檔案系統的資料儲存解決方案,歸根結底是將將大問題劃分為小問題。大量的檔案,均勻分佈到多個數據伺服器上後,每個資料伺服器儲存的檔案數量就少了,另外通過使用大檔案儲存多個小檔案的方式,總能把單個數據伺服器上儲存的檔案數降到單機能解決的規模;對於很大的檔案,將大檔案劃分成多個相對較小的片段,儲存在多個數據伺服器上(目前,很多本地檔案系統對超大檔案的支援已經不存在問題了,如ext3檔案系統使用4k塊時,檔案最大能到4T,ext4則能支援更大的檔案,只是受限於磁碟的儲存空間)。
理論上,分散式檔案系統可以只有客戶端和多個數據伺服器組成,客戶端根據檔名決定將檔案儲存到哪個資料伺服器,但一旦有資料伺服器失效時,問題就變得複雜,客戶端並不知道資料伺服器宕機的訊息,仍然連線它進行資料存取,導致整個系統的可靠性極大的降低,而且完全有客戶端決定資料分配時非常不靈活的,其不能根據檔案特性制定不同的分佈策略。
於是,我們迫切的需要能知道各個資料伺服器的服務狀態,資料伺服器的狀態管理可分為分散式和集中式兩種方式,前者是讓多個數據伺服器相互管理,如每個伺服器向其他所有的伺服器傳送心跳資訊,但這種方式開銷較大,控制不好容易影響到正常的資料服務,而且工程實現較為複雜;後者是指通過一個獨立的伺服器(如上圖中的主控伺服器)來管理資料伺服器,每個伺服器向其彙報服務狀態來達到集中管理的目的,這種方式簡單易實現,目前很多分散式檔案系統都採用這種方式如GFS、TFS(http://code.taobao.org/p/tfs/wiki/index/ )、MooseFS (http://www.moosefs.org/ )等。主控伺服器在負載較大時會出現單點,較多的解決方案是配置備用伺服器,以便在故障時接管服務,如果需要,主備之間需要進行資料的同步。
2、問題及解決方法
本文主要討論基於上圖架構的分散式檔案系統的相關原理,工程實現時需要解決的問題和解決問題的基本方法,分散式檔案系統涉及的主要問題及解決方法如下圖所示。為方便描述以下主控伺服器簡稱Master,資料伺服器簡稱DS(DataServer)。
主控伺服器
l 名稱空間的維護
Master負責維護整個檔案系統的名稱空間,並暴露給使用者使用,名稱空間的結構主要有典型目錄樹結構如MooseFS等,扁平化結構如淘寶TFS(目前已提供目錄樹結構支援),圖結構(主要面向終端使用者,方便使用者根據檔案關聯性組織檔案,只在論文中看到過)。
為了維護名字空間,需要儲存一些輔助的元資料如檔案(塊)到資料伺服器的對映關係,檔案之間的關係等,為了提升效率,很多檔案系統採取將元資料全部記憶體化(元資料通常較小)的方式如GFS, TFS;有些系統借則助資料庫來儲存元資料如DBFS,還有些系統則採用本地檔案來儲存元資料如MooseFS。
一種簡單的實現目錄樹結構的方式是,在Master上儲存與客戶端完全一樣的名稱空間,對應的檔案內容為該檔案的元資料,並通過在Master上採用ReiserFS來進行小檔案儲存優化,對於大檔案的儲存(檔案數量不會成為Master的瓶頸),這種方式簡單易實現。曾經參與的DNFS系統的開發就是使用這種方式,DNFS主要用於儲存視訊檔案,視訊數量在百萬級別,Master採用這種方式檔案數量上不會成為瓶頸。
l 資料伺服器管理
除了維護檔案系統的名稱空間,Master還需要集中管理資料DS, 可通過輪詢DS或由DS報告心跳的方式實現。在接收到客戶端寫請求時,Master需要根據各個DS的負載等資訊選擇一組(根據系統配置的副本數)DS為其服務;當Master發現有DS宕機時,需要對一些副本數不足的檔案(塊)執行復制計劃;當有新的DS加入叢集或是某個DS上負載過高,Master也可根據需要執行一些副本遷移計劃。
如果Master的元資料儲存是非持久化的,則在DS啟動時還需要把自己的檔案(塊)資訊彙報給Master。在分配DS時,基本的分配方法有隨機選取,RR輪轉、低負載優先等,還可以將伺服器的部署作為參考(如HDFS分配的策略),也可以根據客戶端的資訊,將分配的DS按照與客戶端的遠近排序,使得客戶端優先選取離自己近的DS進行資料存取.
l 服務排程
Master最終的目的還是要服務好客戶端的請求,除了一些週期性執行緒任務外,Master需要服務來自客戶端和DS的請求,通常的服務模型包括單執行緒、每請求一執行緒、執行緒池(通常配合任務佇列)。單執行緒模型下,Master只能順序的服務請求,該方式效率低,不能充分利用好系統資源;每請求一執行緒的方式雖能併發的處理請求,但由於系統資源的限制,導致建立執行緒數存在限制,從而限制同時服務的請求數量,另外,執行緒太多,執行緒間的排程效率也是個大問題;執行緒池的方式目前使用較多,通常由單獨的執行緒接受請求,並將其加入到任務佇列中,而執行緒池中的執行緒則從任務佇列中不斷的取出任務進行處理。
l 主備(主)容災
Master在整個分散式檔案系統中的作用非常重要,其維護檔案(塊)到DS的對映、管理所有的DS狀態並在某些條件觸發時執行負載均衡計劃等。為了避免Master的單點問題,通常會為其配置備用伺服器,以保證在主控伺服器節點失效時接管其工作。通常的實現方式是通過HA、UCARP等軟體為主備伺服器提供一個虛擬IP提供服務,當備用伺服器檢測到主宕機時,會接管主的資源及服務。
如果Master需要持久化一些資料,則需要將資料同步到備用Master,對於元資料記憶體化的情況,為了加速元資料的構建,有時也需將主上的操作同步到備Master。處理方式可分為同步和非同步兩種。同步方式將每次請求同步轉發至備Master,這樣理論上主備時刻保持一致的狀態,但這種方式會增加客戶端的響應延遲(在客戶端對響應延遲要求不高時可使用這種方式),當備Master宕機時,可採取不做任何處理,等備Master起來後再同步資料,或是暫時停止寫服務,管理員介入啟動備Master再正常服務(需業務能容忍);非同步方式則是先暫存客戶端的請求資訊(如追加至操作日誌),後臺執行緒重放日誌到備Master,這種方式會使得主備的資料存在不一致的情況,具體策略需針對需求制定。
3、資料伺服器
l 資料本地儲存
資料伺服器負責檔案資料在本地的持久化儲存,最簡單的方式是將客戶每個檔案資料分配到一個單獨的DS上作為一個本地檔案儲存,但這種方式並不能很好的利用分散式檔案系統的特性,很多檔案系統使用固定大小的塊來儲存資料如GFS, TFS, HDFS,典型的塊大小為64M。
對於小檔案的儲存,可以將多個檔案的資料儲存在一個塊中,併為塊內的檔案建立索引,這樣可以極大的提高儲存空間利用率。Facebook用於儲存照片的HayStack系統的本地儲存方式為,將多個圖片物件儲存在一個大檔案中,併為每個檔案的儲存位置建立索引,其支援檔案的建立和刪除,不支援更新(通過刪除和建立完成),新建立的圖片追加到大檔案的末尾並更新索引,檔案刪除時,簡單的設定檔案頭的刪除標記,系統在空閒時會對大檔案進行compact把設定刪除標記且超過一定時限的檔案儲存空間回收(延遲刪除策略)。淘寶的TFS系統採用了類似的方式,對小檔案的儲存進行了優化,TFS使用擴充套件塊的方式支援檔案的更新。對小檔案的儲存也可直接藉助一些開源的KV儲存解決方案,如Tokyo Cabinet(HDB, FDB, BDB, TDB)、Redis等。
對於大檔案的儲存,則可將檔案儲存到多個塊上,多個塊所在的DS可以並行服務,這種需求通常不需要對本地儲存做太多優化。
l 狀態維護
DS除了簡單的儲存資料外,還需要維護一些狀態,首先它需要將自己的狀態以心跳包的方式週期性的報告給Master,使得Master知道自己是否正常工作,通常心跳包中還會包含DS當前的負載狀況(CPU、記憶體、磁碟IO、磁碟儲存空間、網路IO等、程序資源,視具體需求而定),這些資訊可以幫助Master更好的制定負載均衡策略。
很多分散式檔案系統如HDFS在外圍提供一套監控系統,可以實時的獲取DS或Master的負載狀況,管理員可根據監控資訊進行故障預防。
l 副本管理
為了保證資料的安全性,分散式檔案系統中的檔案會儲存多個副本到DS上,寫多個副本的方式,主要分為3種。最簡單的方式是客戶端分別向多個DS寫同一份資料,如DNFS採用這種方式;第2種方式是客戶端向主DS寫資料,主DS向其他DS轉發資料,如TFS採用這種方式;第三種方式採用流水複製的方式,client向某個DS寫資料,該DS向副本鏈中下一個DS轉發資料,依次類推,如HDFS、GFS採取這種方式。
當有節點宕機或節點間負載極不均勻的情況下,Master會制定一些副本複製或遷移計劃,而DS實際執行這些計劃,將副本轉發或遷移至其他的DS。DS也可提供管理工具,在需要的情況下由管理員手動的執行一些複製或遷移計劃。
l 服務模型
參考主控伺服器::服務模型。
4、客戶端
l 介面
使用者最終通過檔案系統提供的介面來存取資料,linux環境下,最好莫過於能提供POSIX介面的支援,這樣很多應用(各種語言皆可,最終都是系統呼叫)能不加修改的將本地檔案儲存替換為分散式檔案儲存。
要想檔案系統支援POSIX介面,一種方式時按照VFS介面規範實現檔案系統,這種方式需要檔案系統開發者對核心有一定的瞭解;另一種方式是藉助FUSE(http://fuse.sourceforge.net)軟體,在使用者態實現檔案系統並能支援POSIX介面,但是用該軟體包開發的檔案系統會有額外的使用者態核心態的切換、資料拷貝過程,從而導致其效率不高。很多檔案系統的開發藉助了fuse,參考http://sourceforge.net/apps/mediawiki/fuse/index.php?title=FileSystems。
如果不能支援POSIX介面,則為了支援不同語言的開發者,需要提供多種語言的客戶端支援,如常用的C/C++、java、php、python客戶端。使用客戶端的方式較難處理的一種情況時,當客戶端升級時,使用客戶端介面的應用要使用新的功能,也需要進行升級,當應用較多時,升級過程非常麻煩。目前一種趨勢是提供Restful介面的支援,使用http協議的方式給應用(使用者)訪問檔案資源,這樣就避免功能升級帶來的問題。
另外,在客戶端介面的支援上,也需根據系統需求權衡,比如write介面,在分散式實現上較麻煩,很難解決資料一致性的問題,應該考慮能否只支援create(update通過delete和create組合實現),或折中支援append,以降低系統的複雜性。
l 快取
分散式檔案系統的檔案存取,要求客戶端先連線Master獲取一些用於檔案訪問的元資訊,這一過程一方面加重了Master的負擔,一方面增加了客戶端的請求的響應延遲。為了加速該過程,同時減小Master的負擔,可將元資訊進行快取,資料可根據業務特性快取在本地記憶體或磁碟,也可快取在遠端的cache系統上如淘寶的TFS可利用tair作為快取(減小Master負擔、降低客戶端資源佔用)。
維護快取需考慮如何解決一致性問題及快取替換演算法,一致性的維護可由客戶端也可由伺服器完成,一種方式是客戶端週期性的使cache失效或檢查cache有效性(需業務上能容忍),或由伺服器在元資料更新後通知客戶端使cache失效(需維護客戶端狀態)。使用得較多的替換演算法如LRU、隨機替換等。
l 其他
客戶端還可以根據需要支援一些擴充套件特性,如將資料進行加密保證資料的安全性、將資料進行壓縮後儲存降低儲存空間使用,或是在介面中封裝一些訪問統計行為,以支援系統對應用的行為進行監控和統計。
5、總結
本文主要從典型分散式檔案系統架構出發,討論了分散式檔案系統的基本原理,工程實現時需要解決的問題、以及解決問題的基本方法,真正在系統工程實現時,要考慮的問題會更多。