
人臉識別 傳統Haar與CNN比較
轉自:https://zhuanlan.zhihu.com/p/25335957
成文於2016年7月,以調研人臉檢測技術的發展為目的,同時也瞭解一下深度學習相關知識。
文章很長,也沒修改,請各位看官指正,有所引用,侵刪。
前言:“春風十里,不如懂深度學習”,沸沸揚揚的“圍棋人機大戰”最終以谷歌AlphaGo擊敗職業棋手李世石而落下帷幕,我們有幸見證了“人工智慧”新里程碑的誕生。藉助AlphaGo研究的契機,深度學習(Deep learning,DL)相關方法受到廣泛關注與應用。人臉檢測作為模式識別經典應用,資料集豐富,一定條件下任務也足夠複雜,深度學習正好有用武之地。此調研報告主要從以下幾方面組成:1 人臉檢測的發展現狀
2 深度學習的發展歷史 為什麼要用深度學習? 深度學習是什麼?
3 基於DL 的人臉檢測方法與傳統方法的比較(文獻演算法、商用演算法、專利情況)
4 總結與展望 要開始深度學習的硬體需求 未來視覺方面的的研究方向
一、人臉檢測
自動人臉檢測技術是所有人臉影像分析衍生應用的基礎,這些擴充套件應用細分有人臉識別、人臉驗證、人臉跟蹤、人臉屬性識別,人臉行為分析、個人相簿管理、機器人人機互動、社交平臺的應用等。
從應用領域上可以分為:①以企事業單位管理及商業保密為主的商用人臉檢測;②大規模聯網布控的多角度多背景的安防人臉檢測;③反恐安全、調查取證、刑事偵查為主的低解析度尺度多樣的軍用/警用人臉檢測;④當然還有基於網際網路社交娛樂應用等的一般人臉檢測。在學術研究中分為約束環境人臉檢測和非約束環境人臉檢測,如下圖。
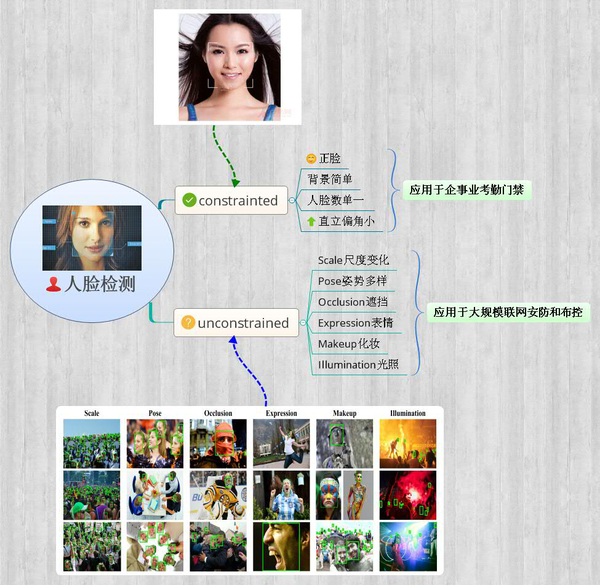
1.人臉檢測的發展現狀
所謂人臉檢測,就是給定任意一張圖片,找到其中是否存在一個或多個人臉,並返回圖片中每個人臉的位置和範圍。人臉檢測的研究在過去二十年例取得了巨大進步,特別是Viola and Jones提出了開創性演算法,他們通過Haar-Like特徵和AdaBoost去訓練級聯分類器獲得實時效果很好的人臉檢測器,然而研究指出當人臉在非約束環境下,該演算法檢測效果極差。這裡說的非約束環境是對比於約束情況下人臉數單一、背景簡單、直立正臉等相對理想的條件而言的,隨著人臉識別、人臉跟蹤等的大規模應用,人臉檢測面臨的要求越來越高(如上圖):人臉尺度多變、數量冗大、姿勢多樣包括俯拍人臉、戴帽子口罩等的遮擋、表情誇張、化妝偽裝、光照條件惡劣、解析度低甚至連肉眼都較難區分
14年底微軟美國研究院首席研究員張正友等在CVIU上發表了非約束人臉檢測專題綜述,文中指出過去十年裡,當限定誤檢數為0或不超過10個時,人臉檢測演算法的查準率也就是準確率(true positive rate)提高了65%之多(最新基於CNN的演算法和傳統Vj-boosting演算法的對比結果)。
文中總結了現今出現的優異演算法主要得益於以下四點:
①越來越多的魯棒特徵提取方法:LBP、SIFT、HOG、SURF、DAISY等;
②開放的資料庫和評測平臺:LFW、FDDB(報告中效能對比主要用的一個,更新於2016.4.15)、WIDER(湯曉歐團隊釋出的,更新於2016.4.17,不完整);
③機器學習方法的發展和應用:boosting、SVM、深度學習等;
④高質量的開源視覺程式碼庫的良好發展與維護:OpenCV、DPM、深度學習框架-caffe等。
人臉檢測演算法以往被分為基於知識的、基於特徵的、基於模板匹配的、基於外觀的四類方法。隨著近些年DPM演算法(可變部件模型)和深度學習CNN(卷積神經網路)的廣泛運用,人臉檢測所有演算法可以總分為兩類:①Based on rigid templates:代表有boosting+features和CNN ②Based on parts model:主要是DPM。
基於深度學習的人臉檢測方法可以作為第一類方法的代表,同時也是檢測某一種深度學習架構或新方法是否有效的評測標準。往往一個簡單的卷積神經網路在人臉檢測就能獲得很好效果,同時有文獻驗證了深度卷積神經網路的第一層特徵和SIFT型別特徵極其相似。
DPM演算法由Felzenszwalb於2008年提出的一種基於部件的檢測方法,對目標的形變具有很強的魯棒性,目前已成為分類、分割、動態估計等演算法的核心組成部分。應用DPM的演算法採用了改進後的Hog特徵、SVM分類器和滑動視窗檢測思想,在非約束人臉檢測中取得極好效果。而其缺點主要是計算複雜度過高。
隨著DNN的發展,基於深度學習的方法獲得了state of art的效果,可見未來人臉檢測演算法主要的發展將圍繞DPM和DCNN展開。同時將DPM和DCNN結合的方法也將是研究趨勢。
2.實際應用
在實際中,作為安防企業,人臉檢測(識別)技術的研發應用在兩方面:
1.基本的人臉考勤和門禁等,這一類屬於有約束情況,用傳統改進演算法足以滿足效能;
2.安防實時監控,智慧視訊人臉分析,海量人臉搜尋驗證、人群數量統計,防踩踏預警等,這類屬於非約束情況,不僅對檢測演算法的精度(包括誤檢率)要求很高,而且要確保實時性。
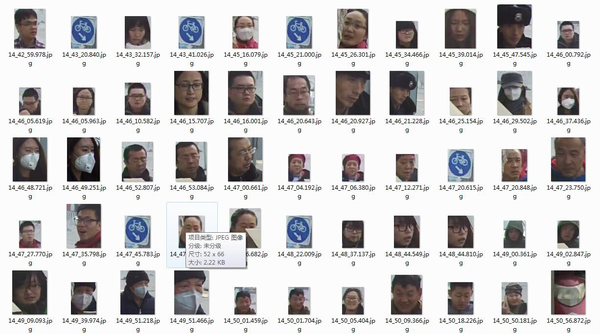
調研發現,人臉檢測(識別)實戰的場景逐漸從室內演變到室外,從單一路況發展到廣場、車站、地鐵口等。目前基於後者場景,精度若能穩定達到80%以上就屬於頂尖技術了(很難達到)。可以想象,霧霾天戴著口罩,冬天戴著帽子,夏天戴著墨鏡等,傳統演算法的檢測是比較難的。
例如,公安部門某次招標給出的人臉測試集中一張圖如下,可以看出圖片模糊、解析度低,更有戴口罩等大部分遮擋情況。在這種情況下需要識別精度達到一定要求,並且對於召回率(誤檢率)有一定的保證,傳統檢測演算法是望而卻步的,而且目前現有智慧視訊分析技術的誤報率有60%之多,改進的好點的能降低到30%,但還是極大影響實際應用(天安門廣場上過識別後因誤報高撤了)。綜上所述,研究出克服上述困難的人臉檢測演算法是人臉分析相關應用的首要任務。
二、深度學習
1.深度學習的背景知識
深度學習是近十年來人工智慧領域取得的最重要的突破之一。它在語音識別、自然語言處理、計算機視覺、影象與視訊分析、多媒體等諸多領域都取得了巨大成功。
現有的深度學習模型大部分屬於神經網路。神經網路的歷史可追溯到上世紀四十年代,曾經在八九十年代流行。神經網路試圖通過模擬大腦認知的機理,解決各種機器學習的問題。1986年Rumelhart,Hinton和Williams在《自然》發表了著名的反向傳播演算法用於訓練神經網路,直到今天仍被廣泛應用。
但是後來由於種種原因,大多數學者在相當長的一段的時間內放棄了神經網路。神經網路有大量的引數,經常發生過擬合問題,即往往在訓練集上準確率很高,而在測試集上效果差,究其根本是訓練資料較少等造成的。而且計算資源有限,即便是訓練一個較小的網路也需要很長的時間。總體而言,神經網路與其它模型相比並未在識別的準確率上體現出明顯的優勢,而且難於訓練。
因此更多的學者開始傾向使用諸如SVM、Boosting、KNN等分類器。這些分類器可以用具有一個或兩個隱含層的神經網路模擬,因此被稱作淺層機器學習模型。它們不模擬大腦的認知機理;相反,針對不同的任務設計不同的系統,並採用不同的手工設計(hand crafted)的特徵,我們可以稱之為有監督的學習。例如語音識別採用高斯混合模型(GMM)和隱馬爾可夫模型(HMM),物體匹配和識別採用SIFT特徵,人臉檢測採用Haar-like特徵,人臉識別採用LBP特徵,行人檢測採用HOG特徵等。
2006年Hinton在Science發表上了名為“Reducing the dimensionality of data with neural networks”的論文,提出了利用RBM預訓練的方法,即用特定結構將網路先初始化到一個差不多“好”的程度,再回到傳統的訓練方法(反向傳播BP)。這樣得到的深度網路似乎就能達到一個不錯的結果,從一定程度上解決了之前網路“深不了”的問題:
1)多隱層的人工神經網路具有優異的特徵學習能力,學習得到的特徵對資料有更本質的刻畫,從而有利於視覺化或分類;
2)深度神經網路在訓練上的難度,可以通過“逐層初始化”來有效克服,逐層初始化可通過無監督學習實現。
而這時候深度學習並不是特別火,它的一飛沖天發生在2012年,也是計算機視覺領域最具影響力的突破,Hinton的研究團隊採用深度學習獲得了ImageNet影象分類的比賽冠軍,準確率比第二名好10%。因此在學術界掀起了深度學習研究和應用的熱潮。
與此同時大資料的出現在很大程度上緩解了訓練過擬合的問題。例如上面提到的擁有上百萬有標註影象的ImageNet訓練集(後面會細說)、人臉檢測領域出現的FDDB資料集等。計算機硬體的飛速發展提供了強大的計算能力,使得訓練大規模神經網路(浮點運算要求)成為可能。總之,大資料(labeled)的快速積累、大規模平行計算(GPU)的快速發展、新演算法新框架的不斷出現共同促使了神經網路技術改頭換面,重出江湖搖身一變成為如今的深度學習(deep learning)。
與此同時,在工業界也產生了巨大的影響,引起了磅礴的變遷。在Hinton的科研小組(後面加盟了谷歌)贏得ImageNet比賽之後6個月,谷歌和百度都發布了新的基於影象內容的搜尋引擎,沿用了Hinton在ImageNet競賽中用的深度學習模型,應用在各自的資料上,發現影象搜尋的準確率得到了大幅度的提高。百度在2012年就成立了深度學習研究院(IDL),於2014年五月又在美國矽谷成立了新的深度學習實驗室,聘請吳恩達擔任首席科學家。Facebook於2013年12月在紐約成立了新的人工智慧實驗室,聘請深度學習領域的著名學者、卷積神經網路(lenet)的發明人YannLeCun(楊立昆)作為首席科學家。2014年1月,谷歌四億美金收購了一家深度學習的創業公司—DeepMind,這才促成了AlphaGo的誕生。鑑於深度學習在學術和工業界的巨大影響力,2013年MIT Technology Review將其列為世界十大技術突破之首。在這之後,許多基於深度學習的初創公司如雨後春筍般出現,深度學習領域出現了頻繁佈局等,這裡就不贅述了。
2.為什麼是深度學習?
基於上一小節的鋪墊,我們不由的好奇:深度學習和傳統方法相比有哪些關鍵的不同點,深度學習和真正的人工智慧有多大距離嗎?它取得如此成功的原因是什麼?這幾個問題很難解釋清楚,先通過下面思維導圖概括一下。

分別從五方面來概述為什麼深度學習可以這麼火:
①有淵源——1981年的諾貝爾醫學獎獲得者David Hubel和TorstenWiesel發現了視覺系統的資訊處理機制,也就是人的視覺系統的資訊處理是分級的,高層的特徵是低層特徵的組合,從低層到高層的特徵表示越來越抽象,越來越能表現語義或者意圖抽象層面越高,存在的可能猜測就越少,就越利於分類。從某種程度上解釋了為什麼要用層次結構?為什麼要深層?然而人的舉一反三、觸類旁通等能力是目前機器學習遠遠不能達到的。只能說深度學習和“人工智慧”有一定的淵源,是通往真正的“人工智慧”漫漫長路上的一項重要的技術。華為諾亞方舟實驗室主任李航提到:“深度學習,至少是目前的深度學習,還是停留在“複雜的模式識別”層面上,正往推理、控制等方面擴充套件。”未來深度學習將發展到什麼程度,還無法下定論,但是可以預見具有歷史淵源的它還將是研究和應用熱點。
②本質的契合——深度學習泰斗Hinton給出了其理論本質:通過構建多隱層的模型和海量訓練資料(可為無標籤資料),來(無監督)學習更有用的特徵,從而最終提升分類或預測的準確性。“深度模型”是手段,“特徵學習”是目的。深度學習本質上是一種具有層次結構的特徵學習機——它學習大資料特徵,深度刻畫資料內在本質。同時這裡所謂學習更契合上述“低層組成高層,高層利於分類”的人腦視覺處理機制。
③特徵學習的優勢——與傳統手工設計特徵不同,深度學習的自動學習特徵一定程度上避免了前者的劣勢即“手工選取特徵費時費力,需要啟發式專業知識,很大程度上靠經驗和運氣”,我們知道在模式識別領域,一句重要的話是:“Features matter”。獲得好的特徵是識別成功的關鍵。那什麼是好的特徵呢?在一幅影像資訊中,各種複雜因素會以非線性的方式結合在一起。例如人臉影象中包含了身份、姿態、年齡、表情和光線等各種資訊。深度學習的關鍵優勢就是通過多層非線性對映將這些因素成功的區分,例如在深度模型的最後一個隱含層,不同的神經元代表了不同的因素。如果將這個隱含層當作特徵表示,人臉識別、姿態估計、表情識別、年齡估計就會變得非常簡單,因為各個因素之間變成了簡單的線性關係,不再彼此干擾。說明網路和人腦一樣,將原始訊號經過逐層的處理,最終從部分到整體抽象為我們要感知的物體。
④深層結構的優勢——深度學習意味著深層結構,傳統常用的機器學習模型(SVM、boosting)都是淺層結構,有理論證明,三層神經網路模型(經典網路——輸入層+一個隱含層+輸出層)可以近似任何分類函式。然而針對特定複雜的任務,淺層結構需要的引數和訓練樣本要多得多。因為淺層模型處理的是區域性特徵,將高維整體的目標分成許多區域性區域,這些區域訓練得到一個模板,然後將測試樣本與這模板對比判斷並預測其類別。當分類或識別問題複雜時,需要的模板要求更高更多,導致引數數量和訓練樣本呈指數上升。然而深度模型能減少引數的關鍵在於重複利用中間層的計算單元,如DCNN由於一個對映面上的神經元可共享權值從而大大減少網路自由引數。從人臉影象分析上看,DL可以學習針對人臉影象的分層特徵表達。最底層從原始pixel學習濾波器,刻畫區域性邊緣和紋理特徵;緊接著中層濾波器通過低層各種邊緣濾波器的組合描述出不同型別的人臉器官(如上圖,可放大看);到最高層描述的是整個人臉的全域性特徵。深層結構決定了DL提供的是分散式的特徵表示。在最高的隱含層中,每個神經元代表一個屬性分類器,例如男女性別、人種、頭髮顏色等。每個神經元將影象空間一分為二,N個神經元組合可以表達2N個區域性區域,而淺層至少需要2N個。可見深度模型表達能力更強且高效。
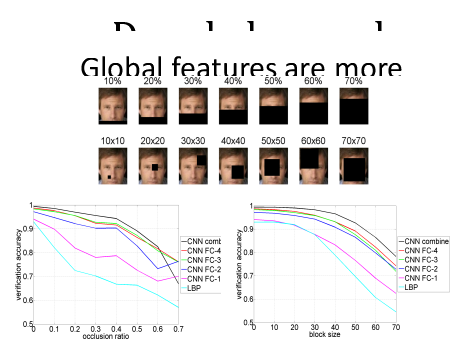
⑤新穎的演算法設計(tricks)——深度模型具有強大的學習、高效的特徵表達能力,從畫素級原始資料輸入,進行逐層提取資訊,可以最終輸出識別結果,構成一個端到端系統。深度學習獲得的模型可以成功應用到其他領域,泛化能力極強。這些歸功於越來越多新演算法的提出。在CV研究領域中,一些學者將深度學習模型視為黑盒子,實際上研究表明傳統計算機視覺系統和深度學習模型存在密切的聯絡,而且可以利用傳統的特徵以及上述聯絡,設計出新的深度模型和新的訓練方法。例如用於行人檢測的聯合深度學習,一個行人檢測器包括了特徵提取、部件檢測器、部件集合形變建模、部件遮擋推理、分類器等等,在聯合深度模型演算法中,深度模型的每個層和視覺系統的各個模組可以建立起一定的對應關係。當視覺系統中存在一些關鍵模組在現有的深度學習模型中沒有與之對應的層,這就啟發了我們設計出新的深度模型,在人臉檢測中同樣常用的物體部件的幾何形變建模DPM,研究證明DPM演算法可以有效提高檢測率,但是常見的深度模型中沒有與之對應的層,有學者就相應地提出了新的形變層和形變池化層以實現這一功能。再進一步,我們在視覺研究中積累的經驗可以對深度模型的預訓練提供指導,預訓練得到的模型至少可以達到與傳統方法可比的程度,在此基礎上,深度學習還會利用反向傳播對所有的層進行聯合優化,使它們之間的相互協作達到最優,從而使整個網路的效能得到重大提升。例如在影象及視訊相關應用中,最成功的深度卷積網路(DCNN),它採用兩個重要操作——卷積與池化正是利用與影象相關的特殊結構而設計的,其中池化起到降維效果同時帶來了區域性的平移不變性。而且已經有人把卷積核改進到加權PCA矩陣,做出深度特徵臉卷積神經網路了。我們希望在未來的研究中可以進一步擴充套件設計演算法結構,獲得如旋轉不變性、尺度不變性、光照魯棒性、甚至是對遮擋的魯棒性等等。值得一提是湯曉歐、王曉剛團隊通過加大網路結構,增加訓練資料,以及在每一層都加入監督資訊進一步改進得到的DeepID2+,實驗結果表明它最上層的神經元相應是中度稀疏的,對人臉身份和各種人臉屬性具有很強的選擇性,對區域性遮擋具有很強的魯棒性,如下圖所示,人臉甚至被遮擋70%,該深度演算法對人臉驗證精度仍有75%之高(墨鏡、口罩可破?!)。
綜上幾點,深度學習之所以能夠受到如此廣泛關注,是有緣由的,它再也不是神經網路方法打出的一個大噱頭,絕不僅僅是簡單替換原先系統,而是從理論上的大變革。
3.深度卷積神經網路
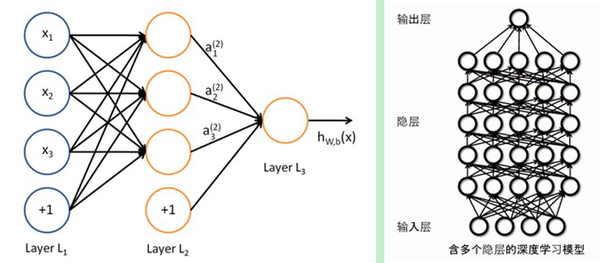
深度學習採用了與傳統神經網路相似的分層結構,系統由包括輸入層、隱層(多層)、輸出層組成的多層網路,只有相鄰層節點之間有連線,同一層以及跨層節點之間相互無連線,每一層可以看作是一個logistic regression模型;這種分層結構,比較接近人類大腦結構。
深度學習方法有很多,如:自動編碼器、稀疏自動編碼器、受限波爾茲曼機(RBM)、深度信念網路(DBN)、卷積神經網路(CNN)、迴圈神經網路(RNN)、長短期記憶遞迴網路(LSTM)等。在上一節提到,在影象識別領域,主要用的是卷積神經網路(CNN),下面圍繞CNN作簡要介紹,同時藉助matlab實現的簡單手寫字元程式碼例程CNN-toolbox加以說明。
一個深度卷積神經網路通常包含輸入層、多個卷積層(convolutional layer)、對應的降取樣層(pooling layer)和歸一化層。最後通過全連線層(fully connected layer)將二維的feature maps連線成一個向量輸入到最後的分類器,得到概率(二分類時0/1)輸出,如下圖。
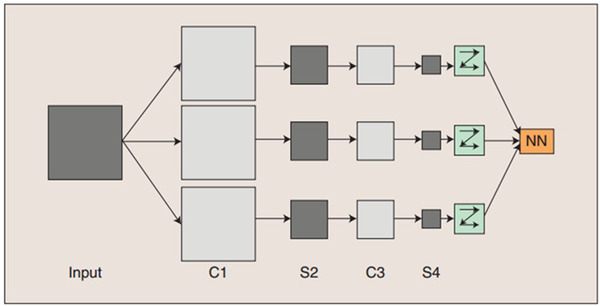
卷積神經網路的概念示範:輸入影象通過和三個可訓練的濾波器和可加偏置進行卷積,濾波過程如上圖,卷積後在C1層產生三個特徵對映圖,然後特徵對映圖中每組的四個畫素再進行降取樣求和(池化pooling),加權值、偏置,通過一個Sigmoid函式得到三個S2層的特徵對映圖。這些對映圖再進過濾波得到C3層。這個層級結構再和S2一樣產生S4。最終,這些畫素值被光柵化,並連線成一個向量輸入到傳統的神經網路全連線層,分類得到輸出。
卷積層(Convolution):通過若干個濾波器與輸入的二維特徵平面(第一個卷積層是原始圖片)進行卷積提取得到資料的顯著性特徵(如下左圖),濾波器的大小(3X3,一般不大於5X5)決定了提取到的特徵對應的感知區域的大小,每一個特徵都對應輸入空間的一個小的感知區域,提取到的特徵通過降取樣等操作提高特徵對輸入樣本微小畸變的魯棒性。在卷積層中,卷積核是在整個輸入平而上進行平移的(步長stride=1),不同卷積層的卷積核提取不同尺度的特徵,所以卷積神經網路提取的特徵具有很高的平移不變性和尺度不變性,下圖中,5X5的輸入image與3X3卷積核卷積得到3X3的Convolved feature。
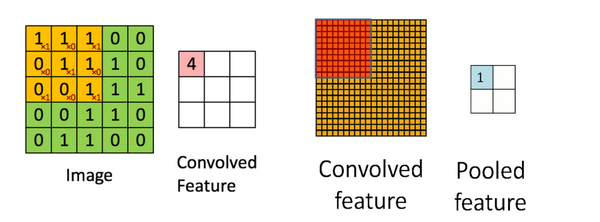
池化層(Pooling):影象具有一種“靜態”的屬性,也就是意味著在一個區域內有用的特徵極有可能在另一個區域適用。為了描述大的影象時,又可以做到降維,我們很自然的就對不同位置的特徵進行聚合統計,旨在提高網路對輸入樣本微小形變的魯棒性,從而增強網路的泛化能力,有以下三種:平均池化Average pooling、最大池化Max pooling、重疊池化Overlapping pooling,一般size=stride,如上右圖,上一步得到的卷積特徵圖的左上角經過特定的運算,可以得到右邊池化特徵圖的值,注意池化作用於影象不重疊區域,有別卷積操作。
上一章中提到過,CNN的一個對映面上的神經元共享權值,因而減少了網路自由引數的個數,降低了網路引數選擇的複雜度。卷積神經網路中的每一個特徵提取層(C-層)都緊跟著一個用來求區域性平均與二次提取的計算層(S-層或P),這種特有的兩次特徵提取結構使網路在識別時對輸入樣本有較高的畸變容忍能力。
測試實驗:下面通過matlab實驗簡要說明,主程式名為test_example_CNN,首先匯入深度學習大牛楊立昆的mnist手寫數字識別資料庫,它共有70000個手寫數字樣本(28x28,下右圖),其中60000個作為訓練樣本,10000個作測試樣本。然後把資料畫素/255歸一化並轉為浮點數。再通過設定網路引數,C1層神經元數6、卷積核尺寸為5,S2降取樣一半,C3神經元數12、卷積核尺寸5,S4降取樣一半。最後設定訓練選項,alpha學習率為1,batchsize批訓練樣本數50,迭代次數待定等。呼叫子程式cnnsetup,初始化網路,呼叫cnntrain,訓練cnn,呼叫cnnff完成前向過程,呼叫cnnbp計算並傳遞神經網路的error,計算梯度(修改權值),呼叫cnnapplygrads把計算出來的梯度加到原始模型上(優化)。最終執行cnntest函式測試優化後模型的準確率,與測試樣本的y值對比,輸出error值。函式呼叫如下左圖。

迭代1次,耗時102秒,對於10000個測試手寫數字樣本進行預測,得到準確率88.87%,迭代20次,耗時33分鐘,得到準確率99.982%,同時注意到上右圖,CNN對輸入的圖形不需要約束或預處理,顛倒的亦可。可以看出通過一個簡單的6層卷積神經網路來解決手寫數字識別任務是非常高效的。由於採用的是matlab和一般硬體,故運算時間久。本章最後給出調研中對CNN演算法的總結圖。
三、基於深度學習的人臉檢測
報告開篇前言中提到人臉檢測是模式識別經典基礎應用,資料集豐富,一定條件下任務也足夠複雜。這裡我們可以認為當人臉處於非約束環境下的檢測是一類足夠複雜的任務,基於深度學習的人臉檢測將有用武之地,可以獲得state of art的效能。那麼有幾個問題需要展開調研:基於深度學習的人臉檢測及相關的技術發展現狀怎樣?基於DL的人臉檢測與傳統方法相比有多大優勢?商用演算法呢?專利情況?
1.基於DL的影象識別技術發展
隨著06年深度學習的重出江湖,影象識別領域的許多學者就開始了淺嘗輒止的應用研究。早在07年Osadchy基於CNN提出一種新的能實時的同時完成多角度估計和人臉姿態估計的方法,這裡的CNN由交替的卷積層和均值取樣層組成,包含五個隱藏層,最後一個隱藏層是全連線層,然而效果一般。直至微軟研究院在2011年提出了深度神經網路和隱馬爾可夫模型(DNN-HMM)成功應用於大詞彙量語音識別系統,並驚人地將常規的高斯混合模型(GMM-HMM)的相對誤差率減少了16%以上,在語音識別50多年的發展中取得如此卓越的進展具有非常重要的意義。與此同時,素有國際“計算機視覺奧林匹克”之稱的ImageNet2012競賽結果揭曉了(ImageNet是當今計算機視覺領域最具影響力的比賽之一,它的訓練和測試樣本都來自於網際網路圖片,訓練樣本超過百萬,任務是將測試樣本分成1000類,自2009年起,包括工業界在內的很多計算機視覺小組都參加了每年一度的比賽,而且各個小組的方法逐漸趨同),令人咋舌的是,這次獲得影象分類冠軍的是第一次參賽的Hinton研究小組。排名2到4位的小組都採用的是傳統的計算機視覺方法、基於手工設計的特徵學習,他們準確率的差別不超過1%。然而Hinton的深度學習方法比第二名超出了10%以上,這個結果在計算機視覺領域產生了極大的震動。
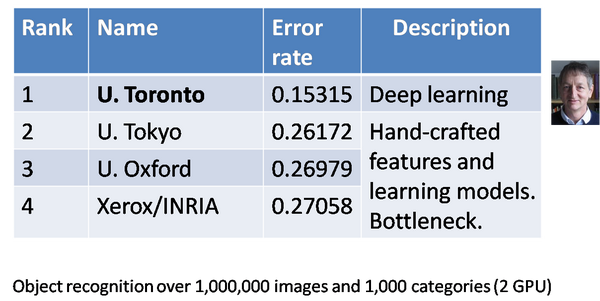
到了2014年的ImageNet比賽中,用深度學習來進行影象分類已經成為心照不宣的方法。
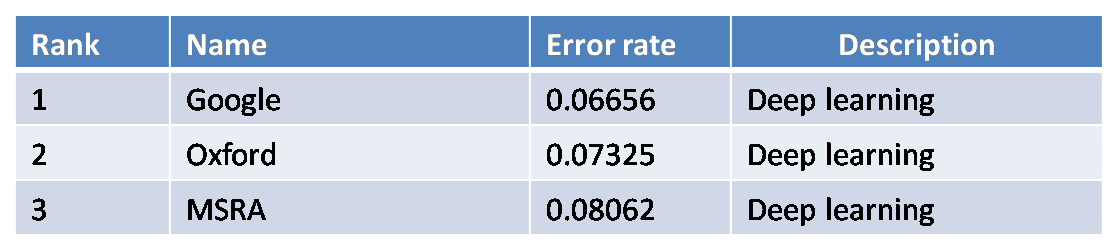
ImageNet2015競賽結果於15年底揭曉,參賽的68支隊伍均採用了深度學習方法(百度因超過每週測試集使用限制次數,在較短時間內頻繁訪問測試集,涉嫌作弊撤銷參賽資格)。
在影象目標檢測(DET)目標分類和定位任務中,微軟亞洲研究院(MSRA)的孫劍、何凱明(經典去霧演算法作者)等組成的隊伍採用“深層殘差網路”(deep residual networks)獲得了冠軍,他們的深度結構實現了152層,“殘差學習”最重要的突破在於重構了學習的過程,並重新定向了深層神經網路中的資訊流。它很好地解決了此前深層神經網路層級與準確度之間的矛盾。
在視訊目標檢測任務中,港中大歐陽萬里、王曉剛和SenseTime(商湯科技)閆俊傑等(其實是一家)聯合組成的團隊在視訊物體檢測競賽中取得了檢測數量、檢測準確率兩項世界第一的成績。檢測器採用由DeepID-Net和Faster Rcnn組合而成,並引入光流估計和時空資訊及視訊文理等方法確定最終的候選目標。
在場景目標分類任務中,北京大學信科院林宙辰與中科院計算所研究生申麗組成的團隊基於其課題組所提出的新的深度學習優化演算法,在場景分類a情形(即只用主辦方所提供的訓練資料)中提交了五個不同模型,一舉包攬前五名(錯誤率16.8715%-17.3527%),他們採用了部分重疊優化策略來改善卷積神經網路效能(pooling),從而減小底層優化難度,增強高層區分能力,並引入VGG-like深度學習框架以及平衡取樣策略來獲得更優分類效果。
計算機視覺領域另一個重要的挑戰是人臉識別。Labeled Faces in the Wild (LFW)是最流行的人臉識別測試集(同樣是馬薩諸塞大學計算機系維護,和檢測集FDDB並稱人臉雙雄),創建於2007年。在此前,人臉識別測試集大多采集於實驗室約束(直立、正臉)的條件下。而LFW從網際網路收集了五千多個名人的人臉照片,用於評估人臉識別演算法在非約束條件下的效能。這些照片往往具有複雜的光線、表情、姿態、年齡和遮擋等方面的變化。LFW的測試集包含了6000對人臉影象。其中3000對是正樣本,每對的兩張影象屬於同一個人;剩下3000對是負樣本,每對的兩張影象屬於不同的人。隨機猜的準確率是50%。有研究表明,如果只把不包括頭髮在內的人臉的中心區域給人看,人眼在LFW測試集上的識別率是97.53%。如果把整張影象,包括背景和頭髮給人看,人眼的識別率是99.15%。經典的人臉識別演算法Eigenface(特徵臉)在這個測試集上只有60%的識別率。在非深度學習的演算法中,最好的識別率是96.33%。目前深度學習普遍可以達到99%的識別率或更高。如百度深度學習研究院99.77%,騰訊優圖99.65%,當然也包括飛搜科技99.40%,北京中科奧森(核心演算法來自李子青團隊)99.77%等公司。
2.基於DL的方法和傳統方法的比較
本節將介紹基於深度學習的人臉檢測技術及其效能比較。
隨著深度學習的新型框架不斷提出,以及一些優異tricks的廣泛使用(如ReLU啟用函式、dropout策略、殘差網路等),基於深度學習的方法在各個領域均獲得了state of art的效果。研究表明,非約束環境下的傳統人臉檢測技術發展的關鍵問題在於:類似haar小波和HOG等特徵無法在多樣的姿勢和光照條件下獲取人臉顯著資訊,可以認為這一侷限性大大影響了檢測精度,其中特徵的提取佔的比重大於各種分類器,這也說明了手工設計特徵往往難以駕馭各種複雜任務。然而使用深度學習中的DCNN來提取特徵成為研究熱點。那麼對於其獲得人臉檢測的效能,下面從文獻演算法和商用演算法兩方面與傳統方法進行對比。
效能對比離不開有效的演算法評測集。FDDB是由馬薩諸塞大學計算機系維護的一套公開資料庫,為來自全世界的研究者提供一個標準的人臉檢測評測平臺,其中涵蓋在非約束環境下(自然環境)的各種姿態的人臉,其中包含5171張人臉的2845張圖片作為測試集。作為全世界最具權威的人臉檢測評測平臺之一,而其公佈的評測集也代表了人臉檢測的世界最高水平,FDDB更新比較及時,最新更新於4月15日。本報告主要參考FDDB評測資料。
對某一演算法的泛化效能(在訓練樣本中獲得的分類器在測試樣本中的表現)進行評估,需要有衡量模型泛化能力的評價標準。人臉檢測一般採用兩種曲線:P-R曲線和ROC曲線。
P-R曲線是指的查準率(precision也稱準確率)和查全率(recall也成召回率)的曲線關係,查準率(P)是預測結果為正例實際也是正例的數量(True Positive,TP)佔預測為正例總數的比值(可能存在反例預測為正,False Positive,FP),在人臉檢測中指檢測到真實人臉數佔檢測器檢測到人臉總數的百分比。查全率(R)則是預測結果為正例實際也是正例的數量(True Positive,TP)佔實際正例的總數(可能存在誤檢例,False negative,FN),在人臉檢測中指檢測到的真實人臉數佔測試集中真實人臉總數的百分比。下面用表格來描述。
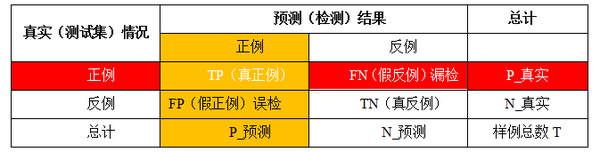
查準率(TP/P_預測)和查全率(TP/P_真實)是一對矛盾的度量,一般來說,查準率高時,查全率往往偏低,而查全率高時,查準率往往偏低。若希望真實人臉儘可能多地檢測出來也就是希望查準率儘可能地高,若希望誤檢人臉數儘可能的少也就是希望查全率儘可能地高。通常只有在有約束環境下,才可能滿足兩者都很高。
而ROC曲線則是真正例率和假正例率的曲線,真正例率(True Positive rate,TPR)為TP/P_真實等同於查全率,假正例率(False Positive rate,FPR)為FP/N_真實,前者評估的是漏檢水平,後者評估的是誤檢水平。由於在FDDB評估集中使用的是真正例率(準確率)和假正例數(誤檢數)的曲線關係。這個關係在人臉檢測中是最合理的,我們最希望得到的檢測器能在誤檢數儘可能少的前提下,使得漏檢率儘可能的低。下圖是近幾年來發表的頂級文獻演算法對比情況,以下表格中甄選了一些演算法具體分析,有經典演算法、傳統演算法以及近兩年的深度學習演算法做比對。資料來自FDDB官方網站。
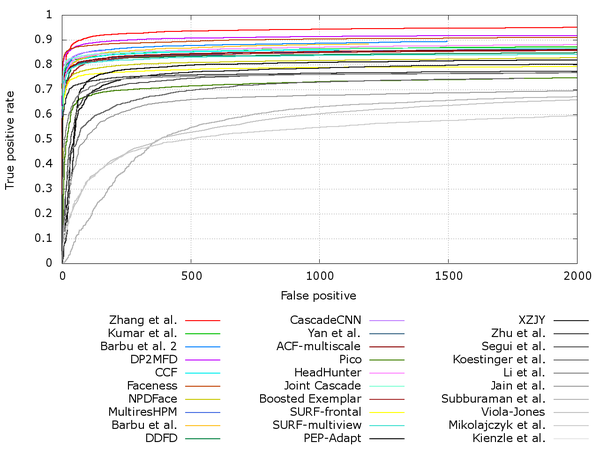
1.文獻演算法
表中對比可知傳統演算法在特徵設計上存在一定劣勢,深度學習演算法普遍具有更優的效能。
2.商用演算法
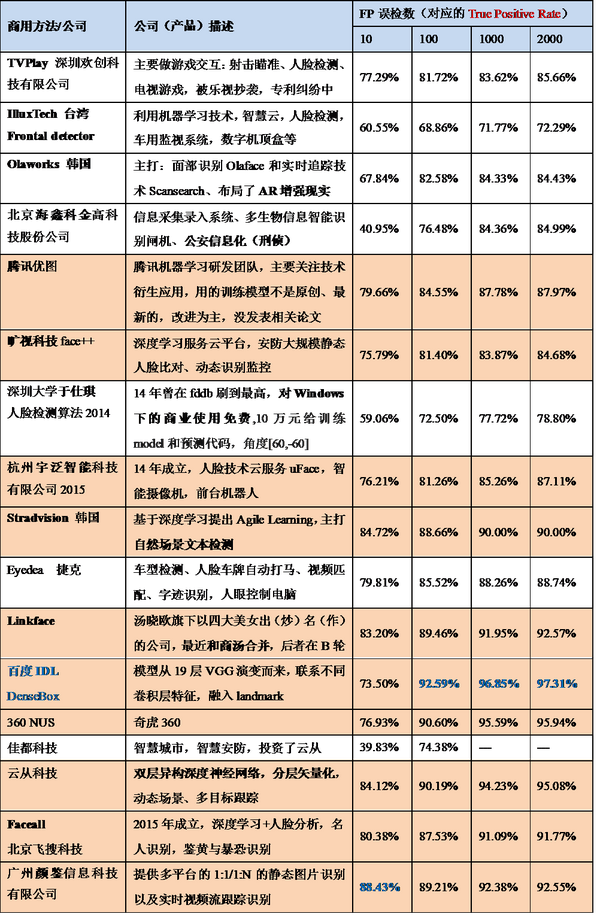
上表可以看出,列舉出共十七項商用演算法,百度IDL提出DenseBox第三版(加粗藍色)是效能最優演算法。表中有十項是基於深度學習方法的人臉檢測演算法(加底紋),這些演算法普遍比傳統演算法提高了十幾個百分點,在誤檢數限制為10的情況下(基本沒有誤檢),準確率仍能達到75%-80%,甚至有88.43%之高。在上述兩表中提到的文獻演算法和商用演算法只是為了說明深度學習方法的優勢,然而相比於人臉比對評測集中許多公司刷到的99.00%+來說,FDDB人臉檢測評測集還遠未達到頂點(目前最高97.31%),雖然只有僅僅兩個百分點左右的差距,如果用比較相似的額外資料作訓練集,完全能夠刷出更高的分數,但是對於演算法研究和實際應用卻是極難突破的,因為實際遇到的情況遠比FDDB測試集上的複雜多變,隨著深度學習和機器視覺技術的發展,我們可以用更好的策略、更優的特徵學習、更深的網路將非約束情況下的人臉檢測效能逐步提高。
3.專利情況
為進一步調研基於深度學習的人臉檢測相關技術,從中國專利局檢索並篩選出12例發明專利如下表所示,搜尋過程發現,目前大部分人臉檢測技術專利還是基於傳統方法的,基於深度學習的專利只有近幾年獲准、為數不多的4項,因為有一部分專利是用深度學習方法來做人臉識別、性別檢測、人數估計等實際應用,在這其中,輸入神經網路的資料都是預處理剪下並對齊好的人臉,並未使用深度學習方法做人臉檢測。不過我們可以預見在深度學習熱潮的席捲下,這類專利會逐漸增多,最終應用在實際產品中。

四、總結與展望
深度學習在影象識別中的發展方興未艾,報告中提到的只是冰山一角,未來還有著巨大的空間。在人臉檢測中正趨向使用更大更深的網路結構。ILSVRC2012中Alex Net只包含了5個卷積層和兩個全連線層。ILSVRC2014中GooLeNet和VGG使用的網路結構為20層,而之前提到的ILSVRC2015微軟亞洲研究院實現了152層的深度結構,更深的網路結構使得反向傳播更加困難。與此同時訓練資料的規模、耗時也在迅速增加。這迫切需要研究新的演算法和開發新的平行計算硬體系統更加有效地利用大資料訓練更大更深的模型。
總之,深度學習的本質是通過多層非線性變換,從大資料中自動學習特徵,從而替代手工設計的特徵。深層的結構使其具有極強的表達能力和學習能力,尤其擅長提取複雜的全域性特徵和上下文資訊,而這是淺層模型難以做到的。一幅影象中,各種隱含的因素往往以複雜的非線性的方式關聯在一起,而深度學習可以使這些因素分級開,在其最高隱含層不同神經元代表了不同的因素,從而使分類變得簡單。深度模型並非黑盒子,它與傳統的計算機視覺體統有著密切的聯絡,但是它使得這個系統的各個模組(即神經網路的各個層)可以通過聯合學習,整體優化,從而效能得到大幅提升。與影象識別相關的各種應用也在推動深度學習在網路結構、層的設計和訓練方法各個方面的的快速發展。我們可以預見在未來的數年內,深度學習將會在理論、演算法、和應用各方面進入高速發展的時期,期待著愈來愈多精彩的工作對學術和工業界產生深遠的影響。
假如要從事深度學習相關領域的研發和應用,可以從下面兩方面入手:
1.需要的硬體
調研發現稍微大一點的神經網路,用CPU跑可能要半個月,GPU只需要一天多。因為跑DL吃浮點運算的,雖然CPU也支援浮點運算,但是速度太慢,而GPU出色的浮點計算效能特別提高了深度學習兩大關鍵活動:分類和卷積的效能,同時又達到所需的精準度。如果我們作為興趣愛好想跑一個簡單的深度網路首當其衝的是配置一臺入門機器,如果公司研發部門或者科研機構想從事深度學習相關研究開發,首先要做的也是入手適合的硬體系統。NVIDIA公司表示,深度學習需要很高的內在並行度、大量的浮點計算能力以及矩陣預算,而GPU可以提供這些能力,並且在相同的精度下,相對傳統CPU的方式,擁有更快的處理速度、更少的伺服器投入和更低的功耗。例如,TITAN X在工業標準模型AlexNet上跑,花了不到三天的時間,使用120萬個ImageNet影象資料集去訓練模型,而使用16G核心的CPU得花上四十多天。如有200萬張圖片需要學習,用一臺雙路E5-2650 v2的伺服器訓練需要16天時間,而如果用阿里雲雙GPU物理機僅需要1天,阿里雲基於公共雲平臺的高效能運算產品HPC正式對外商用,可通過阿里雲官網租用(一個月一臺7200,有錢公司用的)。
目前那些走在深度學習前沿公司是怎麼做的呢?Microsoft正在嘗試使用FPGA加速神經網路計算,並一直在尋找擁有更強大計算能力的可程式設計邏輯器件。普遍猜測Google擁有GPU的數量在8000個左右,但事實上遠遠不止。國內語音識別領頭羊科大訊飛,據說基於多GPGPU和InfiniBand構建了一個環形的並行學習架構,用於DNN、RNN、CNN等模型訓練,效果不錯。同時科大訊飛為打造“訊飛超腦”,除了GPU,還考慮藉助深度定製的人工神經網路專屬晶片來打造更大規模的超算平臺叢集。
除了英偉達的GPU,還有其他選擇,如IBM主導的SyNAPSE巨型神經網路晶片(類人腦晶片),功率低可擴充套件。在70毫瓦的功率上提供100萬個“神經元”核心、2.56億個“突觸”核心以及4096個“神經突觸”核心,甚至允許神經網路和機器學習負載超越了馮·諾依曼架構,二者的能耗和效能,都足以成為GPU潛在的挑戰者。浪潮開發了一個支援多GPU的Caffe,曙光也研發了基於PCI匯流排的多GPU的技術,對熟悉序列程式設計的開發者更加友好。相比之下,FPGA可程式設計晶片或者是人工神經網路專屬晶片對於植入伺服器以及程式設計環境、程式設計能力要求更高,還缺乏通用的潛力,目前不適合普及。但值得注意的是Intel去年斥巨資167億美元收購了世界兩大FPGA公司之一的Altera,期待CPU和FPGA的強強結合,如果發揮好FPGA的低功耗和高效能硬體加速,未來的市場前景將十分光明,深度學習的硬體選擇將更加多樣。
做深度學習嵌入式應用的話可以選擇NVIDIA JetPack,它是針對Jetson嵌入式開發平臺的開發者提供的工具,通過最新的GIE(GPU推斷引擎),可以讓Jetson TX1的處理能力達到24張影象每秒每瓦特。研究人員首推DIGITS DevBox,採用四個TITAN X GPU,從記憶體到I/O的每個元件都進行了最佳化除錯,預先安裝了開發深度神經網路所需要使用到的各種軟體,包括:DIGITS 軟體包,三大流行深度學習架構Caffe、Theano和Torch,以及NVIDIA完整的GPU加速深度學習庫cuDNN 2.0,可是這些對於個人普及入門來說非常不現實,因為Devbox售價10萬。下面總結了個人深度學習入門配置以供參考(1.5-2萬)。

2.演算法研究
在與影象和視訊相關的應用中,深度模型的輸出預測(例如分割圖或物體檢測框)往往具有空間和時間上的相關性,如Faceness。通過研究深度模型和傳統計算機視覺系統之間的關係,不但可以幫助我們理解深度學習成功的原因,還可以啟發新的模型和訓練方法,如聯合深度學習和多階段深度學習,未來這方面還可以有更多的工作,如人臉檢測領域針對遮擋、影象模糊等做更多的改進。
雖然深度學習在實踐中取得了巨大成功,通過大資料訓練得到的深度模型體現出的特性(例如稀疏性、選擇性、和對遮擋的魯棒性——Deepid2+)引人注目,其背後的理論分析並未完善,大部分是經驗性策略(如ReLU等),從本質上說明為什麼這些tricks擁有如此好的效果,我們將有許多工作需要在未來發掘。還有例如,如何更好調參,何時收斂,如何取得較好的區域性極小點,能否引入仿生演算法對引數優化,每一層變換取得了那些對識別有益的不變性,又損失了那些資訊等等。最近Mallat(小波變換的推動者)利用小波對深層網路結構進行了量化分析,是在這一個方向上的重要探索。
在應用領域上,深度學習在視訊分析識別的使用還遠未成熟。從ImageNet訓練得到的影象特徵深度模型可以直接有效地應用到各種與影象相關的識別任務(例如影象分類、影象檢索、物體檢測和影象分割等等),和其它不同的影象測試集,具有良好的泛化效能。然而在視訊分析中,描述視訊的靜態影象特徵,可以採用上述的深度模型,但是至今還沒有得到類似的可用於視訊分析的特徵(動態)。要達到這個目的,不但要建立大規模的訓練資料集(最新建立了包含一百萬YouTube視訊的資料庫),還需要研究適用於視訊分析的新的深度模型。此外訓練用於視訊分析的深度模型的計算量也會大大增加。深度學習在視訊分類上的應用總體而言還處於起步階段,未來還有很多工作要做。
深度學習在影象識別上的巨大成功,必將對於多媒體相關的各種應用產生重大影響。期待著更多的學者和工程人員在不久的將來研究和探索如何利用深度學習得到的影象特徵,推動各種應用的快速進步。