
分散式訊息佇列kafka原理簡介
kafka原理簡介
Kafka是由LinkedIn開發的一個分散式的訊息系統,使用Scala編寫,它以可水平擴充套件和高吞吐率而被廣泛使用。目前越來越多的開源分散式處理系統如Cloudera、Apache Storm、Spark都支援與Kafka整合。
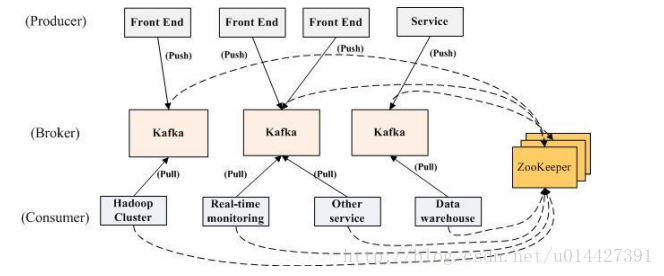
訊息的釋出描述為producer,訊息的訂閱描述為consumer,將中間的儲存陣列稱作broker(代理)。kafka是linkedin用於日誌處理的分散式訊息佇列,同時支援離線和線上日誌處理。kafka對訊息儲存時根據Topic進行歸類,傳送訊息者就是Producer,訊息接受者就是Consumer,每個kafka例項稱為broker。然後三者都通過Zookeeper進行協調。
也即:
1、啟動zookeeper的server
2、啟動kafka的server
3、Producer生產資料,然後通過zookeeper找到broker,再講資料push到broker進行儲存
4、Consumer通過zookeeper找到broker,然後再主動pull資料kafka儲存是基於硬碟儲存的,然而卻有著快速的讀寫效率,一個 67200rpm STAT RAID5 的陣列,線性讀寫速度是 300MB/sec,如果是隨機讀寫,速度則是 50K/sec。
雖然都知道記憶體讀取速度會明顯快於硬碟讀寫速度,但是kafka卻通過線性讀寫的方式實現快速地讀寫。
Producer
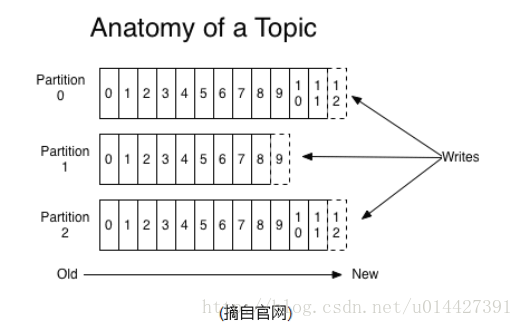
學習kafka一定要理解好Topic,每個Topic被分成多個partition(區)。每條訊息在partition中的位置稱為offset(偏移量),型別為long型數字。訊息即使被消費了,也不會被立即刪除,而是根據broker裡的設定,儲存一定時間後再清除,比如log檔案設定儲存兩天,則兩天後,不管訊息是否被消費,都清除。
Broker
broker也即中間的儲存佇列。我們將訊息的収布(publish)暫時稱作 producer,將訊息的訂閱(subscribe)表述為consumer,將中間的儲存陣列稱作 broker(代理)。
Consumer
每個consumer屬於一個consumer group。在kafka中,一個partition的訊息只會被group中的一個consumer消費;可以認為一個group就是一個“訂閱者”。一個Topic中的每個partition只會被一個“訂閱者”中的一個consumer消費。
Zookeeper
kafka叢集幾乎不需要維護任何Consumer和Producer的資訊。這些資訊由Zookeeper儲存。傳送到Topic的訊息,只會被訂閱此Topic的每個group中的一個consumer消費。
Kafka優點
解耦
在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息系統在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束。冗餘
有些情況下,處理資料的過程會失敗。除非資料被持久化,否則將造成丟失。訊息佇列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丟失風險。許多訊息佇列所採用的”插入-獲取-刪除”正規化中,在把一個訊息從佇列中刪除之前,需要你的處理系統明確的指出該訊息已經被處理完畢,從而確保你的資料被安全的儲存直到你使用完畢。擴充套件性
因為訊息佇列解耦了你的處理過程,所以增大訊息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。不需要改變程式碼、不需要調節引數。擴充套件就像調大電力按鈕一樣簡單。靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。可恢復性
系統的一部分元件失效時,不會影響到整個系統。訊息佇列降低了程序間的耦合度,所以即使一個處理訊息的程序掛掉,加入佇列中的訊息仍然可以在系統恢復後被處理。順序保證
在大多使用場景下,資料處理的順序都很重要。大部分訊息佇列本來就是排序的,並且能保證資料會按照特定的順序來處理。Kafka保證一個Partition內的訊息的有序性。緩衝
在任何重要的系統中,都會有需要不同的處理時間的元素。例如,載入一張圖片比應用過濾器花費更少的時間。訊息佇列通過一個緩衝層來幫助任務最高效率的執行。寫入佇列的處理會盡可能的快速。該緩衝有助於控制和優化資料流經過系統的速度。非同步通訊
很多時候,使用者不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許使用者把一個訊息放入佇列,但並不立即處理它。想向佇列中放入多少訊息就放多少,然後在需要的時候再去處理它們。
單機版安裝教程
1、關閉SELINUX
vi /etc/selinux/config對配置檔案進行修改,然後按ESC鍵,:wq儲存退出
#SELINUX=enforcing
#SELINUXTYPE=targeted
SELINUX=disabled #增加
:wq! #儲存退出2、配置防火牆
vi /etc/sysconfig/iptables可以看到配置檔案,然後按I鍵,insert一行
-A INPUT -m state --state NEW -m tcp -p tcp --dport 9092 -j ACCEPT然後按ESC鍵,:wq儲存退出
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 9092 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
:wq! #儲存退出3、安裝JDK
如果有安裝yum的話,一般可以使用yum安裝,下面給出網上一篇很不錯的jdk安裝教程,建議Linux安裝的可以去linux公社找找教程
CentOS6安裝JDK
4、下載安裝Kafka
cd進入相應資料夾,一般安裝到/usr/local/src
cd /usr/local/srcwget下載檔案
wget http://archive.apache.org/dist/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz解壓
tar -xzvf kafka_2.11-0.8.2.1.tgz移動到安裝目錄
mv kafka_2.11-0.8.2.1 /usr/local/kafka5、配置Kafka
建立Kafka日誌檔案存放資料夾
mkdir /usr/local/kafka/logs/kafkacd配置檔案目錄
cd /usr/local/kafka/configVI編輯
vi server.properties修改配置
broker.id=0
port=9092 #埠號
host.name=127.0.0.1 #伺服器IP地址,修改為自己的伺服器IP
log.dirs=/usr/local/kafka/logs/kafka #日誌存放路徑,上面建立的目錄
zookeeper.connect=localhost:2181 #zookeeper地址和埠,單機配置部署,localhost:2181
:wq! #儲存退出6、Zookeeper配置
建立一個目錄安裝
mkdir /usr/local/kafka/zookeeper建立一個Zookeeper日誌存放目錄
mkdir /usr/local/kafka/logs/zookeeper配置檔案
cd /usr/local/kafka/configvi zookeeper.propertiesdataDir=/usr/local/kafka/zookeeper #zookeeper資料目錄
dataLogDir=/usr/local/kafka/log/zookeeper #zookeeper日誌目錄
clientPort=2181
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
:wq! #儲存退出7、指令碼編寫
編寫kafka的start指令碼
cd /usr/local/kafka使用vi建立指令碼
vi kafkastart.sh 加入指令碼程式碼,&符號表示在後臺執行,然後:wq儲存退出
#!/bin/sh
#啟動zookeeper
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
sleep 3 #等3秒後執行
#啟動kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
編寫kafka的stop指令碼
vi kafkastop.sh指令碼程式碼如,同樣是:wq儲存退出
#!/bin/sh
#關閉zookeeper
/usr/local/kafka/bin/zookeeper-server-stop.sh /usr/local/kafka/config/zookeeper.properties &
sleep 3 #等3秒後執行
#關閉kafka
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties &新增指令碼執行許可權
chmod +x kafkastart.sh
chmod +x kafkastop.sh8、配置指令碼開機自行啟動
vi /etc/rc.d/rc.local設定開機時指令碼在後臺執行,使用&符號
將如下程式碼新增到rc.local裡,同樣使用VI編輯器
sh /usr/local/kafka/kafkastart.sh &:wq儲存退出
9、啟動kafka
sh /usr/local/kafka/kafkastart.sh #啟動kafka10、建立topic
usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181 test
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test --from-beginning