
詳解資料模型(LP32 ILP32 LP64 LLP64 ILP64 )中的不同資料型別
不同資料模型下,各資料型別的位數:
| Type \ Model | LP32 | IPL32 | LP64 | ILP64 | LLP64 |
| char | 8 | 8 | 8 | 8 | 8 |
| short | 16 | 16 | 16 | 16 | 16 |
| int | 16 | 32 | 32 | 64 | 32 |
| long | 32 | 32 | 64 | 64 | 32 |
| long long | 64 | 64 | 64 | 64 | 64 |
| pointer | 32 | 32 | 64 | 64 | 64 |
在這張表中,LP32和ILP32是32位平臺上的字長模型,LP64,ILP64,LLP64是64位平臺上的字長模型。
LP32指long和pointer是32位的,
ILP32指int,long和pointer是32位的,
LP64指long和pointer是64位,
ILP64指int,long,pointer是64位,
LLP64指long long和pointer是64位的。
常見32位環境一般僅涉及"ILP32"資料模型;而64位環境則使用不同的資料模型。現今所有64位的類Unix平臺均使用LP64資料模型,而64位Windows使用LLP64資料模型。
以上 3 個 64 位模型(LP64、LLP64 和 ILP64)之間的區別在於非浮點資料型別。當一個或多個 C 資料型別的寬度從一種模型變換成另外一種模型時,應用程式可能會受到很多方面的影響。這些影響主要可以分為兩類:
- 資料物件的大小。編譯器按照自然邊界對資料型別進行對齊;換而言之,32 位的資料型別在 64 位系統上要按照 32 位邊界進行對齊,而 64 位的資料型別在 64 位系統上則要按照 64 位邊界進行對齊。這意味著諸如結構或聯合之類的資料物件的大小在 32 位和 64 位系統上是不同的。
- 基本資料型別的大小。通常關於基本資料型別之間關係的假設在 64 位資料模型上都已經無效了。依賴於這些關係的應用程式在 64 位平臺上編譯也會失敗。例如,
sizeof (int) = sizeof (long) = sizeof (pointer)的假設對於 ILP32 資料模型有效,但是對於其他資料模型就無效了。
總之,編譯器要按照自然邊界對資料型別進行對齊,這意味著編譯器會進行 “填充”,從而強制進行這種方式的對齊,就像是在 C 結構和聯合中所做的一樣。結構或聯合的成員是根據最寬的成員進行對齊的。
資料型別轉換原則:
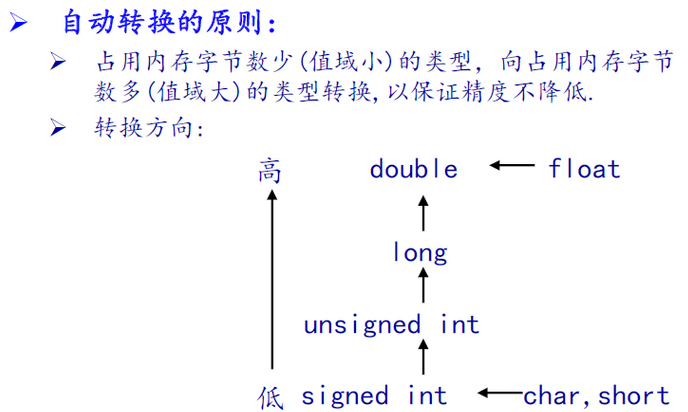
結構體對齊,預設對齊原則:
1.資料型別對齊值:
char型資料自身對齊值為1
short為2,int、float為4,double為8(windows)
解釋:
char變數只要有一個空餘的位元組即可存放
short要求首地址能被2整除,int、float、double同理
2.結構體的對齊值:
其成員中自身對齊值最大的那個值。
解釋:
結構體最終對齊按照資料成員中最長的型別的整數倍
指定對齊原則:
使用#pragma pack改變預設對齊原則
格式:
#pragma pack (value)時的指定對齊值value。
結構體最終對齊按照指定對齊值的整數倍
注意:
1.value只能是:1 2 4 8等
2.指定對齊值與資料型別對齊值相比取較小值
如:如果指定對齊值:
設為1:則short、int、float等均為1
設為2:則char仍為1,short為2,int 變為2