
零基礎掌握百度地圖興趣點獲取POI爬蟲(python語言爬取)(進階篇)
好,現在進入進階篇教程。
1.獲取昆明市的bounds值
看到下面這個東西了吧?在文字框裡寫入昆明市,或者其他的行政區劃地名,北京市、朝陽區、大河溝子村什麼的。
這也是通過呼叫百度地圖開放平臺API實現的。
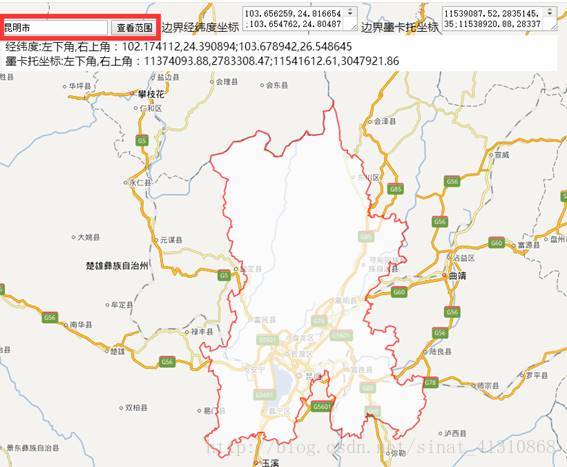
實現起來很簡單,把下面這段程式碼複製到一個txt檔案中,然後把txt檔案的拓展名改成html,用瀏覽器開啟,就可以查詢行政區劃的範圍了。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" HTML是一個很神奇的格式,程式碼可以在文字文件裡寫,不過應該很少有人用文字文件寫程式碼吧。
這段程式碼可以直接拿來用,也是我從網上找的,就不分析了。
2.更合理的對查詢範圍進行切分。
這是一個很常見的問題,我們要採集昆明市的中學興趣點,然後就把矩形等分了六份,遍歷一遍(其實要不遺漏的獲取興趣點,只切六個絕對不夠用)。
這種切分方式其實並不完美,分析一下,中心城區興趣點肯定分佈更密集,而郊區會稀疏一些,而且一個城市的邊界不可能是矩形的,我們用一個大矩形切分,會爬取到一些其他城市的興趣點。
有相關從業經驗的人應該能想到,如果有這個城市的分幅格網,遍歷分幅格網來爬取興趣點會更好一些,當然分幅格網我們也可以自己生成,根據預估的興趣點疏密程度,中心城區格網加密一些,外圍合併一些。
arcgis有一個工具fishnet(建立漁網),可以生成格網。
四至座標可以在欄位計算器裡計算,選用python語言
minX=!shape.extent.xmin!
maxX=!shape.extent.xmax!
minY=!shape.extent.ymin!
maxY=!shape.extent.ymax!把arcgis屬性表匯出,可以用excel開啟。
用這個座標列表去生成url列表,主要就是open和write語句的運用,其實都可以直接在excel裡用函式去生成url列表。
python逐行讀入:
f=open(路徑,’a’)
f.readlines()3.python中文亂碼問題解決
其實這是一個很棘手的問題。對於初學者來說,遇到亂碼問題,如何解決是一個幸運度的問題。有可能運氣不好,就解決不了了,有可能運氣夠好,根本遇不上。
在亂碼問題上,python2.7要多於python3
我精心挑選了幾個我覺得講得比較好的文章,大家可以參考一下,網上相關的文章太多了,容易懵。
這篇中文亂碼的解決方式:
http://www.jb51.net/article/42707.htm
用sys.getfilesystemencoding()獲取檔案系統的編碼方式。
import sys
type = sys.getfilesystemencoding()
print mystr.decode('utf-8').encode(type)我的經驗是,如果遇到亂碼,怎麼都除錯不成功,那麼可以換一個編譯環境,從python2.7換到python3,或者用別的函式,例如不用urllib2,用beautiful soul,或者requests等,有可能莫名其妙亂碼的問題就不出現了呢!
4.併發量限制與延時功能
import time
time.sleep(10)這兩行程式碼的意思是,延時10秒中,它解決的是一分鐘內併發量限制的問題,如果我們沒有做認證,那麼一分鐘能訪問API服務的次數不超過幾次,超過了就會提示訪問超過併發量,就爬不到資料了。
解決這個問題的方法就是用time.sleep(10),每次迴圈都先休眠10秒,就不會訪問超過併發量了。
我覺得10秒夠用了,所以就設定了10秒,不過如果認證過的開發者,應該不會遇到併發量限制的問題。
這段程式碼示例一下:
import time
time.sleep(10)
print time.time()休眠十秒,列印當前時間,結果是一個浮點秒數。
5.把程式碼移植到python3中。
python2.7和python3略微有些差異,python3版本有一個好處就是中文亂碼的情況沒那麼多,而且很多功能和第三方庫都被整合了。
下面這段程式碼是python3中的,可以看出比較於python2.7版本,進行了幾處改變,requests、webbrowser、列表的引用等。
#-*-coding:UTF-8-*-
import json
import sys
import requests #匯入requests庫,這是一個第三方庫,把網頁上的內容爬下來用的
ty=sys.getfilesystemencoding() #這個可以獲取檔案系統的編碼形式
import time
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #座標範圍
las=1 #給las一個值1
ak='9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO'
push=r'D:\python\zwzwlast.txt'
#我們把變數都放在前面,後面就不涉及到變量了,如果要爬取別的POI,修改這幾個變數就可以了,不用改程式碼了。
print (time.time()) #相較於python2.7,,python3print 需要加括號。
print ('開始')
urls=[] 宣告一個數組列表
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
for i in range(0,20):
page_num=str(i)
url='http://api.map.baidu.com/place/v2/search?query=中學& bounds='+str(lat_b1)+','+str(lon_b1)+','+str(lat_b1+las)+','+str(lon_b1+las)+'&page_size=20&page_num='+str(page_num)+'&output=json&ak='+ak
urls.append(url)
#urls.append(url)的意思是,將url新增入urls這個列表中。
f=open(r'D:\python\kunmingxuexiao.txt','a',encoding='utf-8')
print ('url列表讀取完成')
for url in urls:
time.sleep(10) #為了防止併發量報警,設定了一個10秒的休眠。
html=requests.get(url)#獲取網頁資訊
data=html.json()#獲取網頁資訊的json格式資料
for item in data['results']:
jname=item['name']
jlat=item['location']['lat']
jlon=item['location']['lng']
jadd=item['address']
j_str=jname+','+str(jlat)+','+str(jlon)+','+jadd+'\n'
f.write(j_str)
print (time.time())
f.close()
print ('完成') 6.程式碼簡化問題。
可以通過分析json資料提煉一下簡化方式。
網頁開啟之後,看一下。
{
“status”:0,
“message”:”ok”,
“total”:400,
“results”:[
{
“name”:”北大附中雲南實驗學校”,
“location”:{
“lat”:25.009573,
“lng”:102.723208
},
“address”:”昆明市日新中路北大附中雲南實驗學校”,
“street_id”:”beabdbf4ac3394997069d3c7”,
“detail”:1,
“uid”:”beabdbf4ac3394997069d3c7”
主要看results上面那三行,其中total,是這個矩形範圍內有多少個興趣點,有400個,說明我矩形畫大了,應該再細分一下,這個數應該小於400,因為我們之前已經說過20頁網址最多爬400個poi,total是400,說明實際的poi數量是大於400個的。
提取某一座標範圍中第一頁資料的時候,我們可以先獲取total值,這樣就可以計算出page_num的值了,如果total是100,那麼只迴圈到第五頁,page_num=4的時候就可以了。
這是程式碼的一個簡化方式。
當然應該還有很多,有待我們發覺。
7.過程參考資料彙總
因為使用python的人很多,所以網上的資料也很多,不過要找到比較合適的,也沒那麼容易。但是說實話,走彎路、排除錯誤答案也是學習收穫的一個過程,實踐過錯的,才知道什麼是對的嘛!
最有用的參考資料,應該是還算是官網。
https://www.python.org/
學好英語很必要。
這個網址,講的是requests的用法。
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
當然,買本書應該也不錯。
然後指令碼之家和CSDN都有很好的教程,不過也不是所有教程都是對的,多看多試多思考多練習,就會有多獲得。
最後會再來一篇python安裝和第三方庫安裝篇,這個python的零基礎教程就先告一段落吧!