
資料庫常見面試題

三個正規化是什麼
第一正規化(1NF):資料庫表中的欄位都是單一屬性的,不可再分。這個單一屬性由基本型別構成,包括整型、實數、字元型、邏輯型、日期型等。
第二正規化(2NF):資料庫表中不存在非關鍵欄位對任一候選關鍵欄位的部分函式依賴(部分函式依賴指的是存在組合關鍵字中的某些欄位決定非關鍵欄位的情況),也即所有非關鍵欄位都完全依賴於任意一組候選關鍵字。
第三正規化(3NF):在第二正規化的基礎上,資料表中如果不存在非關鍵欄位對任一候選關鍵欄位的傳遞函式依賴則符合第三正規化。所謂傳遞函式依賴,指的是如果存在”A → B → C”的決定關係,則C傳遞函式依賴於A。因此,滿足第三正規化的資料庫表應該不存在如下依賴關係: 關鍵欄位 → 非關鍵欄位x → 非關鍵欄位y
上面的文字我們肯定是看不懂的,也不願意看下去的。接下來我就總結一下:
首先要明確的是:滿足著第三正規化,那麼就一定滿足第二正規化、滿足著第二正規化就一定滿足第一正規化
第一正規化:欄位是最小的的單元不可再分
學生資訊組成學生資訊表,有年齡、性別、學號等資訊組成。這些欄位都不可再分,所以它是滿足第一正規化的
第二正規化:滿足第一正規化,表中的欄位必須完全依賴於全部主鍵而非部分主鍵。
其他欄位組成的這行記錄和主鍵表示的是同一個東西,而主鍵是唯一的,它們只需要依賴於主鍵,也就成了唯一的
學號為1024的同學,姓名為Java3y,年齡是22歲。姓名和年齡欄位都依賴著學號主鍵。
第三正規化:滿足第二正規化,非主鍵外的所有欄位必須互不依賴
就是資料只在一個地方儲存,不重複出現在多張表中,可以認為就是消除傳遞依賴
比如,我們大學分了很多系(中文系、英語系、計算機系……),這個系別管理表資訊有以下欄位組成:系編號,系主任,系簡介,系架構。那我們能不能在學生資訊表新增系編號,系主任,系簡介,系架構欄位呢?不行的,因為這樣就冗餘了,非主鍵外的欄位形成了依賴關係(依賴到學生資訊表了)!正確的做法是:學生表就只能增加一個系編號欄位。
什麼是檢視?以及檢視的使用場景有哪些?
檢視是一種基於資料表的一種虛表
(1)檢視是一種虛表
(2)檢視建立在已有表的基礎上, 檢視賴以建立的這些表稱為基表
(3)向檢視提供資料內容的語句為 SELECT 語句,可以將檢視理解為儲存起來的 SELECT 語句
(4)檢視向用戶提供基表資料的另一種表現形式
(5)檢視沒有儲存真正的資料,真正的資料還是儲存在基表中
(6)程式設計師雖然操作的是檢視,但最終檢視還會轉成操作基表
(7)一個基表可以有0個或多個檢視
有的時候,我們可能只關係一張資料表中的某些欄位,而另外的一些人只關係同一張資料表的某些欄位…
那麼把全部的欄位都都顯示給他們看,這是不合理的。
我們應該做到:他們想看到什麼樣的資料,我們就給他們什麼樣的資料…一方面就能夠讓他們只關注自己的資料,另一方面,我們也保證資料表一些保密的資料不會洩露出來…
我們在查詢資料的時候,常常需要編寫非常長的SQL語句,幾乎每次都要寫很長很長….上面已經說了,檢視就是基於查詢的一種虛表,也就是說,檢視可以將查詢出來的資料進行封裝。。。那麼我們在使用的時候就會變得非常方便…
值得注意的是:使用檢視可以讓我們專注與邏輯,但不提高查詢效率
drop、delete與truncate分別在什麼場景之下使用?
我們來對比一下他們的區別:
drop table
1)屬於DDL
2)不可回滾
3)不可帶where
4)表內容和結構刪除
5)刪除速度快
truncate table
1)屬於DDL
2)不可回滾
3)不可帶where
4)表內容刪除
5)刪除速度快
delete from
1)屬於DML
2)可回滾
3)可帶where
4)表結構在,表內容要看where執行的情況
5)刪除速度慢,需要逐行刪除
不再需要一張表的時候,用drop
想刪除部分資料行時候,用delete,並且帶上where子句
保留表而刪除所有資料的時候用truncate
索引是什麼?有什麼作用以及優缺點?
(1)是一種快速查詢表中內容的機制,類似於新華字典的目錄
(2)運用在表中某個些欄位上,但儲存時,獨立於表之外
索引表把資料變成是有序的….
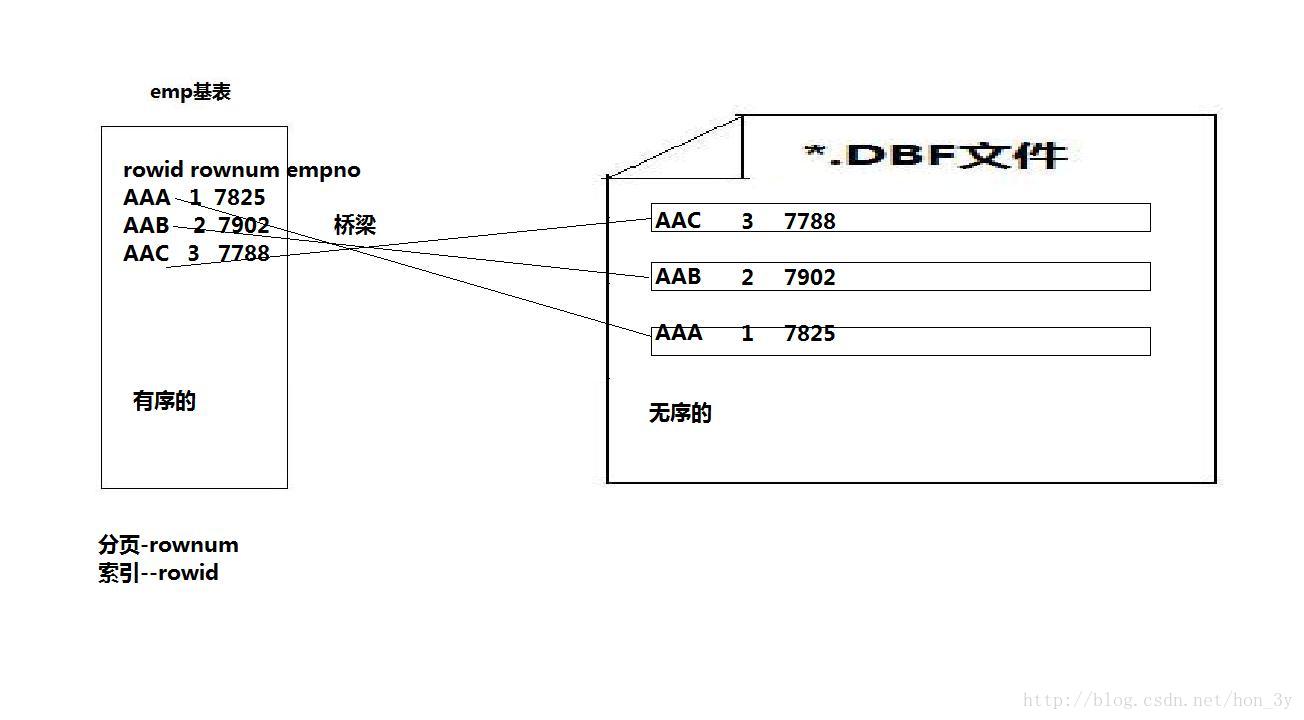
快速定位到硬碟中的資料檔案…
rowid特點
rowid的特點
(1)位於每個表中,但表面上看不見,例如:desc emp是看不見的
(2)只有在select中,顯示寫出rowid,方可看見
(3)它與每個表繫結在一起,表亡,該表的rowid亡,二張表rownum可以相同,但rowid必須是唯一的
(4)rowid是18位大小寫加數字混雜體,唯一表代該條記錄在DBF檔案中的位置
(5)rowid可以參與=/like比較時,用”單引號將rowid的值包起來,且區分大小寫
(6)rowid是聯絡表與DBF檔案的橋樑
索引特點
索引的特點
(1)索引一旦建立,* Oracle管理系統會對其進行自動維護*, 而且由Oracle管理系統決定何時使用索引
(2)使用者不用在查詢語句中指定使用哪個索引
(3)在定義primary key或unique約束後系統自動在相應的列上建立索引
(4)使用者也能按自己的需求,對指定單個欄位或多個欄位,新增索引
需要注意的是:Oracle是自動幫我們管理索引的,並且如果我們指定了primary key或者unique約束,系統會自動在對應的列上建立索引..
什麼時候【要】建立索引
(1)表經常進行 SELECT 操作
(2)表很大(記錄超多),記錄內容分佈範圍很廣
(3)列名經常在 WHERE 子句或連線條件中出現
什麼時候【不要】建立索引
(1)表經常進行 INSERT/UPDATE/DELETE 操作
(2)表很小(記錄超少)
(3)列名不經常作為連線條件或出現在 WHERE 子句中
索引優缺點:
索引加快資料庫的檢索速度
索引降低了插入、刪除、修改等維護任務的速度(雖然索引可以提高查詢速度,但是它們也會導致資料庫系統更新資料的效能下降,因為大部分資料更新需要同時更新索引)
唯一索引可以確保每一行資料的唯一性,通過使用索引,可以在查詢的過程中使用優化隱藏器,提高系統的效能
索引需要佔物理和資料空間
索引分類:
唯一索引:唯一索引不允許兩行具有相同的索引值
主鍵索引:為表定義一個主鍵將自動建立主鍵索引,主鍵索引是唯一索引的特殊型別。主鍵索引要求主鍵中的每個值是唯一的,並且不能為空
聚集索引(Clustered):表中各行的物理順序與鍵值的邏輯(索引)順序相同,每個表只能有一個
非聚集索引(Non-clustered):非聚集索引指定表的邏輯順序。資料儲存在一個位置,索引儲存在另一個位置,索引中包含指向資料儲存位置的指標。可以有多個,小於249個
什麼是事務?
事務簡單來說:一個Session中所進行所有的操作,要麼同時成功,要麼同時失敗
ACID — 資料庫事務正確執行的四個基本要素
包含:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永續性(Durability)。
一個支援事務(Transaction)中的資料庫系統,必需要具有這四種特性,否則在事務過程(Transaction processing)當中無法保證資料的正確性,交易過程極可能達不到交易。
舉個例子:A向B轉賬,轉賬這個流程中如果出現問題,事務可以讓資料恢復成原來一樣【A賬戶的錢沒變,B賬戶的錢也沒變】。
上面的程式也一樣丟擲了異常,A賬戶錢沒有減少,B賬戶的錢也沒有增加。
注意:當Connection遇到一個未處理的SQLException時,系統會非正常退出,事務也會自動回滾,但如果程式捕獲到了異常,是需要在catch中顯式回滾事務的。
事務隔離級別
資料庫定義了4個隔離級別:
Serializable【可避免髒讀,不可重複讀,虛讀】
Repeatable read【可避免髒讀,不可重複讀】
Read committed【可避免髒讀】
Read uncommitted【級別最低,什麼都避免不了】
分別對應Connection類中的4個常量
TRANSACTION_READ_UNCOMMITTED
TRANSACTION_READ_COMMITTED
TRANSACTION_REPEATABLE_READ
TRANSACTION_SERIALIZABLE
髒讀:一個事務讀取到另外一個事務未提交的資料
例子:A向B轉賬,A執行了轉賬語句,但A還沒有提交事務,B讀取資料,發現自己賬戶錢變多了!B跟A說,我已經收到錢了。A回滾事務【rollback】,等B再檢視賬戶的錢時,發現錢並沒有多。
不可重複讀:一個事務讀取到另外一個事務已經提交的資料,也就是說一個事務可以看到其他事務所做的修改
注:A查詢資料庫得到資料,B去修改資料庫的資料,導致A多次查詢資料庫的結果都不一樣【危害:A每次查詢的結果都是受B的影響的,那麼A查詢出來的資訊就沒有意思了】
虛讀(幻讀):是指在一個事務內讀取到了別的事務插入的資料,導致前後讀取不一致。
注:和不可重複讀類似,但虛讀(幻讀)會讀到其他事務的插入的資料,導致前後讀取不一致
資料庫的樂觀鎖和悲觀鎖是什麼?
確保在多個事務同時存取資料庫中同一資料時不破壞事務的隔離性和統一性以及資料庫的統一性,樂觀鎖和悲觀鎖是併發控制主要採用的技術手段。
悲觀鎖:假定會發生併發衝突,遮蔽一切可能違反資料完整性的操作
在查詢完資料的時候就把事務鎖起來,直到提交事務
實現方式:使用資料庫中的鎖機制
樂觀鎖:假設不會發生併發衝突,只在提交操作時檢查是否違反資料完整性。
在修改資料的時候把事務鎖起來,通過version的方式來進行鎖定
實現方式:使用version版本或者時間戳
超鍵、候選鍵、主鍵、外來鍵分別是什麼?
超鍵:在關係中能唯一標識元組的屬性集稱為關係模式的超鍵。一個屬性可以為作為一個超鍵,多個屬性組合在一起也可以作為一個超鍵。超鍵包含候選鍵和主鍵。
候選鍵(候選碼):是最小超鍵,即沒有冗餘元素的超鍵。
主鍵(主碼):資料庫表中對儲存資料物件予以唯一和完整標識的資料列或屬性的組合。一個數據列只能有一個主鍵,且主鍵的取值不能缺失,即不能為空值(Null)。
外來鍵:在一個表中存在的另一個表的主鍵稱此表的外來鍵。
候選碼和主碼:
例子:郵寄地址(城市名,街道名,郵政編碼,單位名,收件人)
它有兩個候選鍵:{城市名,街道名} 和 {街道名,郵政編碼}
如果我選取{城市名,街道名}作為唯一標識實體的屬性,那麼{城市名,街道名} 就是主碼(主鍵)
SQL 約束有哪幾種?
NOT NULL: 用於控制欄位的內容一定不能為空(NULL)。
UNIQUE: 控制元件欄位內容不能重複,一個表允許有多個 Unique 約束。
PRIMARY KEY: 也是用於控制元件欄位內容不能重複,但它在一個表只允許出現一個。
FOREIGN KEY: 用於預防破壞表之間連線的動作,也能防止非法資料插入外來鍵列,因為它必須是它指向的那個表中的值之一。
CHECK: 用於控制欄位的值範圍。
資料庫運行於哪種狀態下可以防止資料的丟失?
在archivelog mode(歸檔模式)只要其歸檔日誌檔案不丟失,就可以有效地防止資料丟失。
Mysql儲存引擎
我的是5.7.15版本,預設使用的是Innodb版本!
常用的儲存引擎有以下:
Innodb引擎,Innodb引擎提供了對資料庫ACID事務的支援。並且還提供了行級鎖和外來鍵的約束。它的設計的目標就是處理大資料容量的資料庫系統。
MyIASM引擎(原本Mysql的預設引擎),不提供事務的支援,也不支援行級鎖和外來鍵。
MEMORY引擎:所有的資料都在記憶體中,資料的處理速度快,但是安全性不高。

同一個資料庫也可以使用多種儲存引擎的表。如果一個表修改要求比較高的事務處理,可以選擇InnoDB。這個資料庫中可以將查詢要求比較高的表選擇MyISAM儲存。如果該資料庫需要一個用於查詢的臨時表,可以選擇MEMORY儲存引擎。
MyIASM和Innodb兩種引擎所使用的索引的資料結構是什麼?
MyIASM引擎,B+樹的資料結構中儲存的內容實際上是實際資料的地址值。也就是說它的索引和實際資料是分開的,只不過使用索引指向了實際資料。這種索引的模式被稱為非聚集索引。
Innodb引擎的索引的資料結構也是B+樹,只不過資料結構中儲存的都是實際的資料,這種索引有被稱為聚集索引。
varchar和char的區別
Char是一種固定長度的型別,varchar是一種可變長度的型別
mysql有關許可權的表都有哪幾個
MySQL伺服器通過許可權表來控制使用者對資料庫的訪問,許可權表存放在mysql資料庫裡,由mysql_install_db指令碼初始化。這些許可權表分別user,db,table_priv,columns_priv和host。下面分別介紹一下這些表的結構和內容:
user許可權表:記錄允許連線到伺服器的使用者帳號資訊,裡面的許可權是全域性級的。
db許可權表:記錄各個帳號在各個資料庫上的操作許可權。
table_priv許可權表:記錄資料表級的操作許可權。
columns_priv許可權表:記錄資料列級的操作許可權。
host許可權表:配合db許可權表對給定主機上資料庫級操作許可權作更細緻的控制。這個許可權表不受GRANT和REVOKE語句的影響。
資料表損壞的修復方式有哪些?
使用 myisamchk 來修復,具體步驟:
1)修復前將mysql服務停止。
2)開啟命令列方式,然後進入到mysql的/bin目錄。
3)執行myisamchk –recover 資料庫所在路徑/*.MYI
使用repair table 或者 OPTIMIZE table命令來修復,REPAIR TABLE table_name 修復表 OPTIMIZE TABLE table_name 優化表 REPAIR TABLE 用於修復被破壞的表。
OPTIMIZE TABLE 用於回收閒置的資料庫空間,當表上的資料行被刪除時,所佔據的磁碟空間並沒有立即被回收,使用了OPTIMIZE TABLE命令後這些空間將被回收,並且對磁碟上的資料行進行重排(注意:是磁碟上,而非資料庫)
MySQL中InnoDB引擎的行鎖是通過加在什麼上完成
InnoDB是基於索引來完成行鎖
例: select * from tab_with_index where id = 1 for update;
for update 可以根據條件來完成行鎖鎖定,並且 id 是有索引鍵的列,
如果 id 不是索引鍵那麼InnoDB將完成表鎖,,併發將無從談起
資料庫優化的思路
選擇最有效率的表名順序
資料庫的解析器按照從右到左的順序處理FROM子句中的表名,FROM子句中寫在最後的表將被最先處理
在FROM子句中包含多個表的情況下:
如果三個表是完全無關係的話,將記錄和列名最少的表,寫在最後,然後依次類推 也就是說:選擇記錄條數最少的表放在最後
如果有3個以上的表連線查詢:如果三個表是有關係的話,將引用最多的表,放在最後,然後依次類推。 也就是說:被其他表所引用的表放在最後
例如:查詢員工的編號,姓名,工資,工資等級,部門名WHERE子句中的連線順序
資料庫採用自右而左的順序解析WHERE子句,根據這個原理,表之間的連線必須寫在其他WHERE條件之左,那些可以過濾掉最大數量記錄的條件必須寫在WHERE子句的之右。
emp.sal可以過濾多條記錄,寫在WHERE字句的最右邊
SELECT子句中避免使用*號
我們當時學習的時候,“*”號是可以獲取表中全部的欄位資料的。
但是它要通過查詢資料字典完成的,這意味著將耗費更多的時間 使用*號寫出來的SQL語句也不夠直觀。用TRUNCATE替代DELETE
這裡僅僅是:刪除表的全部記錄,除了表結構才這樣做。
DELETE是一條一條記錄的刪除,而Truncate是將整個表刪除,保留表結構,這樣比DELETE快
多使用內部函式提高SQL效率
例如使用mysql的concat()函式會比使用||來進行拼接快,因為concat()函式已經被mysql優化過了。
使用表或列的別名
- 多使用commit
善用索引
索引就是為了提高我們的查詢資料的,當表的記錄量非常大的時候,我們就可以使用索引了。
SQL寫大寫
- 避免在索引列上使用NOT
- 避免在索引列上使用計算,WHERE子句中,如果索引列是函式的一部分,優化器將不使用索引而使用全表掃描,這樣會變得變慢
- 用 >= 替代 > SELECT * FROM EMP WHERE DEPTNO >= 4 直接跳到第一個DEPT等於4的記錄
- 用IN替代OR
- 總是使用索引的第一個列
如何理解資料庫架構?
資料庫架構要考慮的問題:
1. 資料可靠和一致性;
2. 資料容災;
3. 當資料量和訪問壓力變大時,方便擴充;
4. 高度可用,出問題時能及時恢復,無單點故障;
5. 不應因為某一臺機器出現問題,導致整網效能的急劇下降;
6. 方便維護
索引的工作原理及其種類
邏輯上:
Single column 單行索引
Concatenated 多行索引
Unique 唯一索引
NonUnique 非唯一索引
Function-based 函式索引
Domain 域索引
物理上:
Partitioned 分割槽索引
NonPartitioned 非分割槽索引
B-tree :
Normal 正常型B樹
Rever Key 反轉型B樹 Bitmap 點陣圖索引
儲存過程與觸發器的區別
觸發器與儲存過程非常相似,觸發器也是SQL語句集,兩者唯一的區別是觸發器不能用EXECUTE語句呼叫,而是在使用者執行Transact-SQL語句時自動觸發(啟用)執行。觸發器是在一個修改了指定表中的資料時執行的儲存過程。通常通過建立觸發器來強制實現不同表中的邏輯相關資料的引用完整性和一致性。由於使用者不能繞過觸發器,所以可以用它來強制實施複雜的業務規則,以確保資料的完整性。觸發器不同於儲存過程,觸發器主要是通過事件執行觸發而被執行的,而儲存過程可以通過儲存過程名稱名字而直接呼叫。當對某一表進行諸如UPDATE、INSERT、DELETE這些操作時,SQLSERVER就會自動執行觸發器所定義的SQL語句,從而確保對資料的處理必須符合這些SQL語句所定義的規則。
觸發器分為事前觸發和事後觸發,這兩種觸發有什麼區別。語句級觸發和行級觸發有何區別。
事前觸發器運行於觸發事件發生之前,而事後觸發器運行於觸發事件發生之後。通常事前觸發器可以獲取事件之前和新的欄位值。
語句級觸發器可以在語句執行前或後執行,而行級觸發在觸發器所影響的每一行觸發一次。
儲存過程和函式的區別
儲存過程是使用者定義的一系列sql語句的集合,涉及特定表或其它物件的任務,使用者可以呼叫儲存過程,而函式通常是資料庫已定義的方法,它接收引數並返回某種型別的值並且不涉及特定使用者表。
另外,儲存過程和函式還有以下幾個區別:
1)儲存過程一般是作為一個獨立的部分來執行的,而函式可以作為查詢語句的一個部分來呼叫。由於函式可以返回一個物件,因此它可以在查詢語句中位於From關鍵字的後面。
2)一般而言,儲存過程實現的功能較為複雜,而函式實現的功能針對性較強。
3)函式需要用括號包住輸入的引數,且只能返回一個值或表物件,而儲存過程可以返回多個引數。
4)函式可以嵌入在SQL中使用,可以在SELECT中呼叫,儲存過程不行。
5)函式不能直接操作實體表,只能操作內建表。
6)儲存過程在建立時即在伺服器上進行了編譯,其執行速度比函式快。
遊標的作用?如何知道遊標已經到了最後?
遊標用於定位結果集的行,通過判斷全域性變數@@FETCH_STATUS可以判斷是否到了最後,通常此變數不等於0表示出錯或到了最後。
(關係資料庫中的操作會對整個行集起作用。由 SELECT 語句返回的行集包括滿足該語句的 WHERE 子句中條件的所有行。這種由語句返回的完整行集稱為結果集。應用程式,特別是互動式聯機應用程式,並不總能將整個結果集作為一個單元來有效地處理。這些應用程式需要一種機制以便每次處理一行或一部分行。遊標就是提供這種機制的對結果集的一種擴充套件。
遊標的特點是:
允許定位在結果集的特定行。
從結果集的當前位置檢索一行或一部分行。
支援對結果集中當前位置的行進行資料修改。
為由其他使用者對顯示在結果集中的資料庫資料所做的更改提供不同級別的可見性支援。
提供指令碼、儲存過程和觸發器中用於訪問結果集中的資料的 Transact-SQL 語句
在從遊標中提取資訊後,可以通過判斷@@FETCH_STATUS 的值來判斷是否到了最後。當@@FETCH_STATUS為0的時候,說明提取是成功的,否則就可以認為到了最後。)